Generalized form of persistence
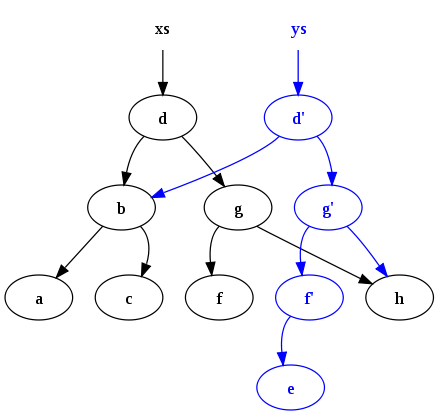
Path copying is one of the simple methods to achieve persistency in a certain data structure such as binary search trees. It is nice to have a general strategy for implementing persistence that works with any given data structure. In order to achieve that, we consider a directed graph G. We assume that each vertex v in G has a constant number c of outgoing edges that are represented by pointers. Each vertex has a label representing the data. We consider that a vertex has a bounded number d of edges leading into it which we define as inedges(v). We allow the following different operations on G.
- CREATE-NODE(): Creates a new vertex with no incoming or outgoing edges.
- CHANGE-EDGE(v, i, u): Changes the ith edge of v to point to u
- CHANGE-LABEL(v, x): Changes the value of the data stored at v to x
Any of the above operations is performed at a specific time and the purpose of the persistent graph representation is to be able to access any version of G at any given time. For this purpose we define a table for each vertex v in G. The table contains c columns and rows. Each row contains in addition to the pointers for the outgoing edges, a label which represents the data at the vertex and a time t at which the operation was performed. In addition to that there is an array inedges(v) that keeps track of all the incoming edges to v. When a table is full, a new table with rows can be created. The old table becomes inactive and the new table becomes the active table.

CREATE-NODE
A call to CREATE-NODE creates a new table and set all the references to null
CHANGE-EDGE
If we assume that CHANGE-EDGE(v, i, u) is called, then there are two cases to consider.
- There is an empty row in the table of the vertex v: In this case we copy the last row in the table and we change the ith edge of vertex v to point to the new vertex u
- Table of the vertex v is full: In this case we need to create a new table. We copy the last row of the old table into the new table. We need to loop in the array inedges(v) in order to let each vertex in the array point to the new table created. In addition to that, we need to change the entry v in the inedges(w) for every vertex w such that edge v,w exists in the graph G.
CHANGE-LABEL
It works exactly the same as CHANGE-EDGE except that instead of changing the ith edge of the vertex, we change the ith label.
Efficiency of the generalized persistent data structure
In order to find the efficiency of the scheme proposed above, we use an argument defined as a credit scheme. The credit represents a currency. For example, the credit can be used to pay for a table. The argument states the following:
- The creation of one table requires one credit
- Each call to CREATE-NODE comes with two credits
- Each call to CHANGE-EDGE comes with one credit
The credit scheme should always satisfy the following invariant: Each row of each active table stores one credit and the table has the same number of credits as the number of rows. Let us confirm that the invariant applies to all the three operations CREATE-NODE, CHANGE-EDGE and CHANGE-LABEL.
- CREATE-NODE: It acquires two credits, one is used to create the table and the other is given to the one row that is added to the table. Thus the invariant is maintained.
- CHANGE-EDGE: There are two cases to consider. The first case occurs when there is still at least one empty row in the table. In this case one credit is used to the newly inserted row. The second case occurs when the table is full. In this case the old table becomes inactive and the credits are transformed to the new table in addition to the one credit acquired from calling the CHANGE-EDGE. So in total we have credits. One credit will be used for the creation of the new table. Another credit will be used for the new row added to the table and the d credits left are used for updating the tables of the other vertices that need to point to the new table. We conclude that the invariant is maintained.
- CHANGE-LABEL: It works exactly the same as CHANGE-EDGE.

As a summary, we conclude that having calls to CREATE_NODE and calls to CHANGE_EDGE will result in the creation of tables. Since each table has size without taking into account the recursive calls, then filling in a table requires where the additional d factor comes from updating the inedges at other nodes. Therefore, the amount of work required to complete a sequence of operations is bounded by the number of tables created multiplied by . Each access operation can be done in and there are edge and label operations, thus it requires . We conclude that There exists a data structure that can complete any sequence of CREATE-NODE, CHANGE-EDGE and CHANGE-LABEL in .