This article relies too much on references to primary sources .(June 2012) (Learn how and when to remove this template message) |
This article describes and classifies the Unicode characters that may validly appear in XML.
This article relies too much on references to primary sources .(June 2012) (Learn how and when to remove this template message) |
This article describes and classifies the Unicode characters that may validly appear in XML.
Unicode code points in the following ranges are valid in XML 1.0 documents: [1]
The preceding code points ranges contain the following controls which are only valid in certain contexts in XML 1.0 documents, and whose usage is restricted and highly discouraged:
Unicode code points in the following code point ranges are always valid in XML 1.1 documents: [2]
The preceding code points ranges contain the following controls which are only valid in certain contexts in XML 1.1 documents, and whose usage is restricted and highly discouraged:
In addition, the following code points, even though they are valid in all XML 1.0 and XML 1.1 documents, are also restricted and discouraged in both versions of XML, as they are permanently assigned to non-characters in Unicode and ISO/IEC 10646. Some XML parsers may even signal them as invalid in their character set decoder, and XML documents containing them may not pass through some restricted interfaces or may not be interchangeable. These non-characters can still be encoded in standard UTFs (such as UTF-8) because these UTFs only restrict the code points assigned to surrogate non-characters:
Note that the code point U+0000, assigned to the null control character, is the only character encoded in Unicode and ISO/IEC 10646 that is always invalid in any XML 1.0 and 1.1 document.
On the opposite, the code point U+0085 is a valid control character in Unicode and ISO/IEC 10646, as well as in XML 1.0 and XML 1.1 documents (in all contexts), and its usage is not discouraged (it is treated as whitespace in many XML contexts, or as a line-break control similar to U+000D and U+000A in preformatted texts in some XML applications).
For these reasons, the non-restricted repertoire which can be used in all versions of XML and in all contexts (as permitted by the XML syntax) contains only code points that are permanently assigned to characters (excluding non-characters), or reserved for possible future encoding in Unicode and ISO/IEC 10646, and excludes the restricted repertoire, for better interoperability. They are:
Unicode is a computing industry standard for the consistent encoding, representation, and handling of text expressed in most of the world's writing systems. The standard is maintained by the Unicode Consortium, and as of May 2019 the most recent version, Unicode 12.1, contains a repertoire of 137,994 characters covering 150 modern and historic scripts, as well as multiple symbol sets and emoji. The character repertoire of the Unicode Standard is synchronized with ISO/IEC 10646, and both are code-for-code identical.
Web pages authored using hypertext markup language (HTML) may contain multilingual text represented with the Unicode universal character set. Key to the relationship between Unicode and HTML is the relationship between the "document character set" which defines the set of characters that may be present in a HTML document and assigns numbers to them and the "external character encoding" or "charset" used to encode a given document as a sequence of bytes.

UTF-8 is a variable width character encoding capable of encoding all 1,112,064 valid code points in Unicode using one to four 8-bit bytes. The encoding is defined by the Unicode Standard, and was originally designed by Ken Thompson and Rob Pike. The name is derived from UnicodeTransformation Format – 8-bit.
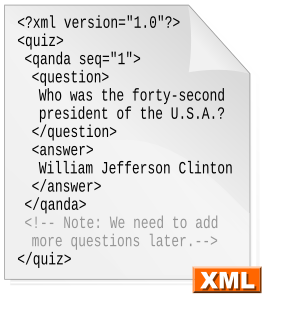
Extensible Markup Language (XML) is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.

UTF-16 is a character encoding capable of encoding all 1,112,064 valid code points of Unicode. The encoding is variable-length, as code points are encoded with one or two 16-bit code units.
UTF-32 (32-bit Unicode Transformation Format) is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point (but a number of leading bits must be zero as there are far fewer than 232 Unicode code points). UTF-32 is a fixed-length encoding, in contrast to all other Unicode transformation formats, which are variable-length encodings. Each 32-bit value in UTF-32 represents one Unicode code point and is exactly equal to that code point's numerical value.
ISO/IEC 8859-6:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 6: Latin/Arabic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Arabic. It was designed to cover Arabic. Only nominal letters are encoded, no preshaped forms of the letters, so shaping processing is required for display. It does not include the extra letters needed to write most Arabic-script languages other than Arabic itself.
A numeric character reference (NCR) is a common markup construct used in SGML and SGML-derived markup languages such as HTML and XML. It consists of a short sequence of characters that, in turn, represents a single character. Since WebSgml, XML and HTML 4, the code points of the Universal Character Set (UCS) of Unicode are used. NCRs are typically used in order to represent characters that are not directly encodable in a particular document. When the document is interpreted by a markup-aware reader, each NCR is treated as if it were the character it represents.
The Compatibility Encoding Scheme for UTF-16: 8-Bit (CESU-8) is a variant of UTF-8 that is described in Unicode Technical Report #26. A Unicode code point from the Basic Multilingual Plane (BMP), i.e. a code point in the range U+0000 to U+FFFF, is encoded in the same way as in UTF-8. A Unicode supplementary character, i.e. a code point in the range U+10000 to U+10FFFF, is first represented as a surrogate pair, like in UTF-16, and then each surrogate code point is encoded in UTF-8. Therefore, CESU-8 needs six bytes for each Unicode supplementary character while UTF-8 needs only four.
In Unicode, a Private Use Area (PUA) is a range of code points that, by definition, will not be assigned characters by the Unicode Consortium. Three private use areas are defined: one in the Basic Multilingual Plane (U+E000–U+F8FF), and one each in, and nearly covering, planes 15 and 16. The code points in these areas cannot be considered as standardized characters in Unicode itself. They are intentionally left undefined so that third parties may define their own characters without conflicting with Unicode Consortium assignments. Under the Unicode Stability Policy, the Private Use Areas will remain allocated for that purpose in all future Unicode versions.
The C0 and C1 control code or control character sets define control codes for use in text by computer systems that use ASCII and derivatives of ASCII. The codes represent additional information about the text, such as the position of a cursor, an instruction to start a new line, or a message that the text has been received.
This article compares Unicode encodings. Two situations are considered: 8-bit-clean environments, and environments that forbid use of byte values that have the high bit set. Originally such prohibitions were to allow for links that used only seven data bits, but they remain in the standards and so software must generate messages that comply with the restrictions. Standard Compression Scheme for Unicode and Binary Ordered Compression for Unicode are excluded from the comparison tables because it is difficult to simply quantify their size.
UTF-1 is one way of transforming ISO 10646/Unicode into a stream of bytes. Its design does not provide self-synchronization, which makes searching for substrings and error recovery difficult. It reuses the ASCII printing characters for multi-byte encodings, making it unsuited for some uses. UTF-1 is also slow to encode or decode due to its use of division and multiplication by a number which is not a power of 2. Due to these issues, it did not gain acceptance and was quickly replaced by UTF-8.
In computer programming, whitespace is any character or series of characters that represent horizontal or vertical space in typography. When rendered, a whitespace character does not correspond to a visible mark, but typically does occupy an area on a page. For example, the common whitespace symbol represents a blank space punctuation character in text, used as a word divider in Western scripts.
The Unicode Consortium (UC) and the International Organisation for Standardisation (ISO) collaborate on the Universal Character Set (UCS). The UCS is an international standard to map characters used in natural language, mathematics, music, and other domains to machine readable values. By creating this mapping, the UCS enables computer software vendors to interoperate and transmit UCS encoded text strings from one to another. Because it is a universal map, it can be used to represent multiple languages at the same time. This avoids the confusion of using multiple legacy character encodings, which can result in the same sequence of codes having multiple meanings and thus be improperly decoded if the wrong one is chosen.
Specials is a short Unicode block allocated at the very end of the Basic Multilingual Plane, at U+FFF0–FFFF. Of these 16 code points, five are assigned as of Unicode 12.0:
A QName, or qualified name, is the fully qualified name of an element, attribute, or identifier in an XML document. A QName concisely associates the URI of an XML namespace with the local name of an element, attribute, or identifier in that namespace. To make this association, the QName assigns the local name a prefix that corresponds to its namespace. In all, the QName comprises the URI of the XML namespace, the prefix, and the local name.
Unicode input is the insertion of a specific Unicode character on a computer by a user; it is a common way to input characters not directly supported by a physical keyboard. Unicode characters can be produced either by selecting them from a display or by typing a certain sequence of keys on a physical keyboard. In addition, a character produced by one of these methods in one web page or document can be copied into another. Unicode is similar to ASCII but provides many more options and encodes many more signs.
The Universal Coded Character Set (UCS) is a standard set of characters defined by the International Standard ISO/IEC 10646, Information technology — Universal Coded Character Set (UCS), which is the basis of many character encodings. The latest version contains over 136,000 abstract characters, each identified by an unambiguous name and an integer number called its code point. This ISO/IEC 10646 standard is maintained in conjunction with The Unicode Standard ("Unicode"), and they are code-for-code identical.