
In computer science, a binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child. That is, it is a k-ary tree with k = 2. A recursive definition using set theory is that a binary tree is a tuple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set containing the root.
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.

In computer programming, the exclusive or swap is an algorithm that uses the exclusive or bitwise operation to swap the values of two variables without using the temporary variable which is normally required.
Kademlia is a distributed hash table for decentralized peer-to-peer computer networks designed by Petar Maymounkov and David Mazières in 2002. It specifies the structure of the network and the exchange of information through node lookups. Kademlia nodes communicate among themselves using UDP. A virtual or overlay network is formed by the participant nodes. Each node is identified by a number or node ID. The node ID serves not only as identification, but the Kademlia algorithm uses the node ID to locate values.
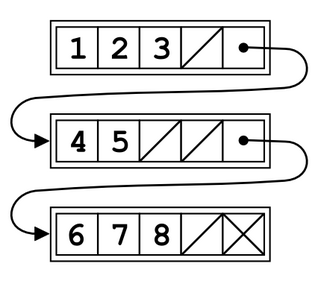
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can dramatically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references. It is related to the B-tree.
Loop unrolling, also known as loop unwinding, is a loop transformation technique that attempts to optimize a program's execution speed at the expense of its binary size, which is an approach known as space–time tradeoff. The transformation can be undertaken manually by the programmer or by an optimizing compiler. On modern processors, loop unrolling is often counterproductive, as the increased code size can cause more cache misses; cf. Duff's device.
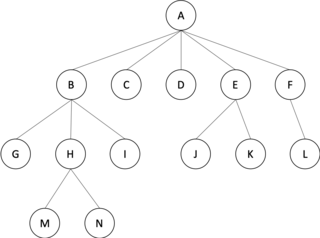
In graph theory, an m-ary tree is an arborescence in which each node has no more than m children. A binary tree is an important case where m = 2; similarly, a ternary tree is one where m = 3.
In computer programming, a sentinel node is a specifically designated node used with linked lists and trees as a traversal path terminator. This type of node does not hold or reference any data managed by the data structure.

In computing, a threaded binary tree is a binary tree variant that facilitates traversal in a particular order.
In computer science, a doubly linked list is a linked data structure that consists of a set of sequentially linked records called nodes. Each node contains three fields: two link fields and one data field. The beginning and ending nodes' previous and next links, respectively, point to some kind of terminator, typically a sentinel node or null, to facilitate traversal of the list. If there is only one sentinel node, then the list is circularly linked via the sentinel node. It can be conceptualized as two singly linked lists formed from the same data items, but in opposite sequential orders.

The TI-990 was a series of 16-bit minicomputers sold by Texas Instruments (TI) in the 1970s and 1980s. The TI-990 was a replacement for TI's earlier minicomputer systems, the TI-960 and the TI-980. It had several unique features, and was easier to program than its predecessors.

In computing, ATS is a multi-paradigm, general-purpose, high-level, functional programming language. It is a dialect of the programming language ML, designed by Hongwei Xi to unify computer programming with formal specification. ATS has support for combining theorem proving with practical programming through the use of advanced type systems. A past version of The Computer Language Benchmarks Game has demonstrated that the performance of ATS is comparable to that of the languages C and C++. By using theorem proving and strict type checking, the compiler can detect and prove that its implemented functions are not susceptible to bugs such as division by zero, memory leaks, buffer overflow, and other forms of memory corruption by verifying pointer arithmetic and reference counting before the program compiles. Also, by using the integrated theorem-proving system of ATS (ATS/LF), the programmer may make use of static constructs that are intertwined with the operative code to prove that a function conforms to its specification.
In computer science, a linked data structure is a data structure which consists of a set of data records (nodes) linked together and organized by references. The link between data can also be called a connector.

In computer science, a queap is a priority queue data structure. The data structure allows insertions and deletions of arbitrary elements, as well as retrieval of the highest-priority element. Each deletion takes amortized time logarithmic in the number of items that have been in the structure for a longer time than the removed item. Insertions take constant amortized time.
Skip graphs are a kind of distributed data structure based on skip lists. They were invented in 2003 by James Aspnes and Gauri Shah. A nearly identical data structure called SkipNet was independently invented by Nicholas Harvey, Michael Jones, Stefan Saroiu, Marvin Theimer and Alec Wolman, also in 2003.

In geometry, Coxeter notation is a system of classifying symmetry groups, describing the angles between fundamental reflections of a Coxeter group in a bracketed notation expressing the structure of a Coxeter-Dynkin diagram, with modifiers to indicate certain subgroups. The notation is named after H. S. M. Coxeter, and has been more comprehensively defined by Norman Johnson.
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives: