In computer science, an abstract data type (ADT) is a mathematical model for data types, defined by its behavior (semantics) from the point of view of a user of the data, specifically in terms of possible values, possible operations on data of this type, and the behavior of these operations. This mathematical model contrasts with data structures, which are concrete representations of data, and are the point of view of an implementer, not a user. For example, a stack has push/pop operations that follow a Last-In-First-Out rule, and can be concretely implemented using either a list or an array. Another example is a set which stores values, without any particular order, and no repeated values. Values themselves are not retrieved from sets, rather one tests a value for membership to obtain a Boolean "in" or "not in".

In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a data structure is a data organization, management, and storage format that is usually chosen for efficient access to data. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
In computing, a hash table, also known as a hash map, is a data structure that implements an associative array, also called a dictionary, which is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.

In computer science, a heap is a tree-based data structure that satisfies the heap property: In a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type that stores a collection of pairs, such that each possible key appears at most once in the collection. In mathematical terms, an associative array is a function with finite domain. It supports 'lookup', 'remove', and 'insert' operations.
The Standard Template Library (STL) is a software library originally designed by Alexander Stepanov for the C++ programming language that influenced many parts of the C++ Standard Library. It provides four components called algorithms, containers, functions, and iterators.
In computer programming, an iterator is an object that enables a programmer to traverse a container, particularly lists. Various types of iterators are often provided via a container's interface. Though the interface and semantics of a given iterator are fixed, iterators are often implemented in terms of the structures underlying a container implementation and are often tightly coupled to the container to enable the operational semantics of the iterator. An iterator performs traversal and also gives access to data elements in a container, but does not itself perform iteration.
In computer science, a list or sequence is an abstract data type that represents a finite number of ordered values, where the same value may occur more than once. An instance of a list is a computer representation of the mathematical concept of a tuple or finite sequence; the (potentially) infinite analog of a list is a stream. Lists are a basic example of containers, as they contain other values. If the same value occurs multiple times, each occurrence is considered a distinct item.

In computer programming, foreach loop is a control flow statement for traversing items in a collection. foreach is usually used in place of a standard for loop statement. Unlike other for loop constructs, however, foreach loops usually maintain no explicit counter: they essentially say "do this to everything in this set", rather than "do this x times". This avoids potential off-by-one errors and makes code simpler to read. In object-oriented languages, an iterator, even if implicit, is often used as the means of traversal.
In computer science, a multimap is a generalization of a map or associative array abstract data type in which more than one value may be associated with and returned for a given key. Both map and multimap are particular cases of containers. Often the multimap is implemented as a map with lists or sets as the map values.
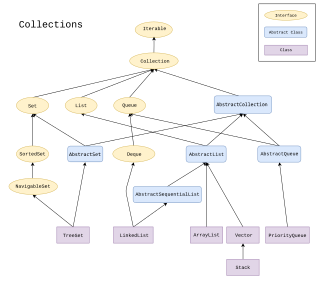
The Java collections framework is a set of classes and interfaces that implement commonly reusable collection data structures.
In computer programming, a collection is a grouping of some variable number of data items that have some shared significance to the problem being solved and need to be operated upon together in some controlled fashion. Generally, the data items will be of the same type or, in languages supporting inheritance, derived from some common ancestor type. A collection is a concept applicable to abstract data types, and does not prescribe a specific implementation as a concrete data structure, though often there is a conventional choice.
Language Integrated Query is a Microsoft .NET Framework component that adds native data querying capabilities to .NET languages, originally released as a major part of .NET Framework 3.5 in 2007.
This Comparison of programming languages (associative arrays) compares the features of associative array data structures or array-lookup processing for over 40 computer programming languages.
This comparison of programming languages (array) compares the features of array data structures or matrix processing for various computer programming languages.
In the programming language C++, unordered associative containers are a group of class templates in the C++ Standard Library that implement hash table variants. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. The following containers are defined in the current revision of the C++ standard: unordered_set, unordered_map, unordered_multiset, unordered_multimap. Each of these containers differ only on constraints placed on their elements.
In computer science, array is a data type that represents a collection of elements, each selected by one or more indices that can be computed at run time during program execution. Such a collection is usually called an array variable or array value. By analogy with the mathematical concepts vector and matrix, array types with one and two indices are often called vector type and matrix type, respectively. More generally, a multidimensional array type can be called a tensor type, by analogy with the physical concept, tensor.
In C++, associative containers refer to a group of class templates in the standard library of the C++ programming language that implement ordered associative arrays. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. The following containers are defined in the current revision of the C++ standard: set, map, multiset, multimap. Each of these containers differ only on constraints placed on their elements.





