In mathematics and computer science, mutual recursion is a form of recursion where two mathematical or computational objects, such as functions or datatypes, are defined in terms of each other. Mutual recursion is very common in functional programming and in some problem domains, such as recursive descent parsers, where the datatypes are naturally mutually recursive.
In mathematics, fuzzy sets are sets whose elements have degrees of membership. Fuzzy sets were introduced independently by Lotfi A. Zadeh in 1965 as an extension of the classical notion of set. At the same time, Salii (1965) defined a more general kind of structure called an L-relation, which he studied in an abstract algebraic context. Fuzzy relations, which are now used throughout fuzzy mathematics and have applications in areas such as linguistics, decision-making, and clustering, are special cases of L-relations when L is the unit interval [0, 1].

Mu is the twelfth letter of the Greek alphabet, representing the voiced bilabial nasal IPA:[m]. In the system of Greek numerals it has a value of 40. Mu was derived from the Egyptian hieroglyphic symbol for water, which had been simplified by the Phoenicians and named after their word for water, to become 𐤌 (mem). Letters that derive from mu include the Roman M and the Cyrillic М, though the lowercase resembles a small Latin U (μ).
In computer programming, especially functional programming and type theory, an algebraic data type (ADT) is a kind of composite type, i.e., a type formed by combining other types.
System F is a typed lambda calculus that introduces, to simply typed lambda calculus, a mechanism of universal quantification over types. System F formalizes parametric polymorphism in programming languages, thus forming a theoretical basis for languages such as Haskell and ML. It was discovered independently by logician Jean-Yves Girard (1972) and computer scientist John C. Reynolds.

In mathematics, mixing is an abstract concept originating from physics: the attempt to describe the irreversible thermodynamic process of mixing in the everyday world: e.g. mixing paint, mixing drinks, industrial mixing.
In computer science, corecursion is a type of operation that is dual to recursion. Whereas recursion works analytically, starting on data further from a base case and breaking it down into smaller data and repeating until one reaches a base case, corecursion works synthetically, starting from a base case and building it up, iteratively producing data further removed from a base case. Put simply, corecursive algorithms use the data that they themselves produce, bit by bit, as they become available, and needed, to produce further bits of data. A similar but distinct concept is generative recursion which may lack a definite "direction" inherent in corecursion and recursion.
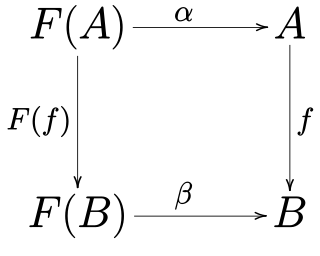
In mathematics, specifically in category theory, F-algebras generalize the notion of algebraic structure. Rewriting the algebraic laws in terms of morphisms eliminates all references to quantified elements from the axioms, and these algebraic laws may then be glued together in terms of a single functor F, the signature.
In programming languages and type theory, parametric polymorphism allows a single piece of code to be given a "generic" type, using variables in place of actual types, and then instantiated with particular types as needed. Parametrically polymorphic functions and data types are sometimes called generic functions and generic datatypes, respectively, and they form the basis of generic programming.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
In mathematics, an initial algebra is an initial object in the category of F-algebras for a given endofunctor F. This initiality provides a general framework for induction and recursion.
In category theory, the concept of catamorphism denotes the unique homomorphism from an initial algebra into some other algebra.
In functional programming, a generalized algebraic data type is a generalization of parametric algebraic data types.
In computer programming, an anamorphism is a function that generates a sequence by repeated application of the function to its previous result. You begin with some value A and apply a function f to it to get B. Then you apply f to B to get C, and so on until some terminating condition is reached. The anamorphism is the function that generates the list of A, B, C, etc. You can think of the anamorphism as unfolding the initial value into a sequence.
In recursion theory, α recursion theory is a generalisation of recursion theory to subsets of admissible ordinals . An admissible set is closed under functions, where denotes a rank of Godel's constructible hierarchy. is an admissible ordinal if is a model of Kripke–Platek set theory. In what follows is considered to be fixed.
In mathematics, the Butcher group, named after the New Zealand mathematician John C. Butcher by Hairer & Wanner (1974), is an infinite-dimensional Lie group first introduced in numerical analysis to study solutions of non-linear ordinary differential equations by the Runge–Kutta method. It arose from an algebraic formalism involving rooted trees that provides formal power series solutions of the differential equation modeling the flow of a vector field. It was Cayley (1857), prompted by the work of Sylvester on change of variables in differential calculus, who first noted that the derivatives of a composition of functions can be conveniently expressed in terms of rooted trees and their combinatorics.
In computer science, polymorphic recursion refers to a recursive parametrically polymorphic function where the type parameter changes with each recursive invocation made, instead of staying constant. Type inference for polymorphic recursion is equivalent to semi-unification and therefore undecidable and requires the use of a semi-algorithm or programmer-supplied type annotations.
In computability theory, computational complexity theory and proof theory, the Hardy hierarchy, named after G. H. Hardy, is a hierarchy of sets of numerical functions generated from an ordinal-indexed family of functions hα: N → N called Hardy functions. It is related to the fast-growing hierarchy and slow-growing hierarchy.
In set theory and logic, Buchholz's ID hierarchy is a hierarchy of subsystems of first-order arithmetic. The systems/theories are referred to as "the formal theories of ν-times iterated inductive definitions". IDν extends PA by ν iterated least fixed points of monotone operators.
In theoretical physics, more specifically in quantum field theory and supersymmetry, supersymmetric Yang–Mills, also known as super Yang–Mills and abbreviated to SYM, is a supersymmetric generalization of Yang–Mills theory, which is a gauge theory that plays an important part in the mathematical formulation of forces in particle physics.






