
In computer science, a data structure is a data organization, management, and storage format that is usually chosen for efficient access to data. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
First-order logic—also known as predicate logic, quantificational logic, and first-order predicate calculus—is a collection of formal systems used in mathematics, philosophy, linguistics, and computer science. First-order logic uses quantified variables over non-logical objects, and allows the use of sentences that contain variables, so that rather than propositions such as "Socrates is a man", one can have expressions in the form "there exists x such that x is Socrates and x is a man", where "there exists" is a quantifier, while x is a variable. This distinguishes it from propositional logic, which does not use quantifiers or relations; in this sense, propositional logic is the foundation of first-order logic.
Forth is a procedural, concatenative, stack-oriented programming language and interactive development environment designed by Charles H. "Chuck" Moore and first used by other programmers in 1970. Although not an acronym, the language's name in its early years was often spelled in all capital letters as FORTH. The FORTH-79 and FORTH-83 implementations, which were not written by Moore, became de facto standards, and an official standardization of the language was published in 1994 as ANS Forth. A wide range of Forth derivatives existed before and after ANS Forth. The free software Gforth implementation is actively maintained, as are several commercially supported systems.
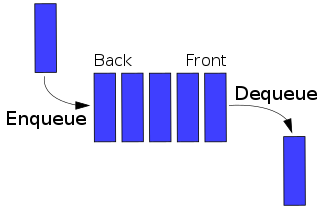
In computer science, a queue is a collection of entities that are maintained in a sequence and can be modified by the addition of entities at one end of the sequence and the removal of entities from the other end of the sequence. By convention, the end of the sequence at which elements are added is called the back, tail, or rear of the queue, and the end at which elements are removed is called the head or front of the queue, analogously to the words used when people line up to wait for goods or services.
The SECD machine is a highly influential virtual machine and abstract machine intended as a target for functional programming language compilers. The letters stand for Stack, Environment, Control, Dump—the internal registers of the machine. The registers Stack, Control, and Dump point to stacks, and Environment points to an associative array.
In computer science, denotational semantics is an approach of formalizing the meanings of programming languages by constructing mathematical objects that describe the meanings of expressions from the languages. Other approaches providing formal semantics of programming languages include axiomatic semantics and operational semantics.
In computer science, abstract interpretation is a theory of sound approximation of the semantics of computer programs, based on monotonic functions over ordered sets, especially lattices. It can be viewed as a partial execution of a computer program which gains information about its semantics without performing all the calculations.

In computer science and computer programming, a data type is a collection or grouping of data values, usually specified by a set of possible values, a set of allowed operations on these values, and/or a representation of these values as machine types. A data type specification in a program constrains the possible values that an expression, such as a variable or a function call, might take. On literal data, it tells the compiler or interpreter how the programmer intends to use the data. Most programming languages support basic data types of integer numbers, floating-point numbers, characters and Booleans.
Generic programming is a style of computer programming in which algorithms are written in terms of data types to-be-specified-later that are then instantiated when needed for specific types provided as parameters. This approach, pioneered by the ML programming language in 1973, permits writing common functions or types that differ only in the set of types on which they operate when used, thus reducing duplicate code.
In computer science, a set is an abstract data type that can store unique values, without any particular order. It is a computer implementation of the mathematical concept of a finite set. Unlike most other collection types, rather than retrieving a specific element from a set, one typically tests a value for membership in a set.
In computer science, a list or sequence is an abstract data type that represents a finite number of ordered values, where the same value may occur more than once. An instance of a list is a computer representation of the mathematical concept of a tuple or finite sequence; the (potentially) infinite analog of a list is a stream. Lists are a basic example of containers, as they contain other values. If the same value occurs multiple times, each occurrence is considered a distinct item.
In computer programming, a reference is a value that enables a program to indirectly access a particular datum, such as a variable's value or a record, in the computer's memory or in some other storage device. The reference is said to refer to the datum, and accessing the datum is called dereferencing the reference. A reference is distinct from the datum itself.

In computer science, a stack is an abstract data type that serves as a collection of elements with two main operations:
In computer programming, especially functional programming and type theory, an algebraic data type (ADT) is a kind of composite type, i.e., a type formed by combining other types.
In computer programming, specifically object-oriented programming, a class invariant is an invariant used for constraining objects of a class. Methods of the class should preserve the invariant. The class invariant constrains the state stored in the object.
Constraint Handling Rules (CHR) is a declarative, rule-based programming language, introduced in 1991 by Thom Frühwirth at the time with European Computer-Industry Research Centre (ECRC) in Munich, Germany. Originally intended for constraint programming, CHR finds applications in grammar induction, type systems, abductive reasoning, multi-agent systems, natural language processing, compilation, scheduling, spatial-temporal reasoning, testing, and verification.
Constraint logic programming is a form of constraint programming, in which logic programming is extended to include concepts from constraint satisfaction. A constraint logic program is a logic program that contains constraints in the body of clauses. An example of a clause including a constraint is A(X,Y):-X+Y>0,B(X),C(Y). In this clause, X+Y>0 is a constraint; A(X,Y), B(X), and C(Y) are literals as in regular logic programming. This clause states one condition under which the statement A(X,Y) holds: X+Y is greater than zero and both B(X) and C(Y) are true.
In computer programming, a collection is a grouping of some variable number of data items that have some shared significance to the problem being solved and need to be operated upon together in some controlled fashion. Generally, the data items will be of the same type or, in languages supporting inheritance, derived from some common ancestor type. A collection is a concept applicable to abstract data types, and does not prescribe a specific implementation as a concrete data structure, though often there is a conventional choice.
In computer science, array is a data type that represents a collection of elements, each selected by one or more indices that can be computed at run time during program execution. Such a collection is usually called an array variable or array value. By analogy with the mathematical concepts vector and matrix, array types with one and two indices are often called vector type and matrix type, respectively. More generally, a multidimensional array type can be called a tensor type, by analogy with the physical concept, tensor.
In computer science, algebraic semantics is a form of axiomatic semantics based on algebraic laws for describing and reasoning about program specifications in a formal manner.











