Image registration is the process of transforming different sets of data into one coordinate system. Data may be multiple photographs, data from different sensors, times, depths, or viewpoints. It is used in computer vision, medical imaging, military automatic target recognition, and compiling and analyzing images and data from satellites. Registration is necessary in order to be able to compare or integrate the data obtained from these different measurements.
Facial motion capture is the process of electronically converting the movements of a person's face into a digital database using cameras or laser scanners. This database may then be used to produce CG computer animation for movies, games, or real-time avatars. Because the motion of CG characters is derived from the movements of real people, it results in more realistic and nuanced computer character animation than if the animation were created manually.
Thomas Shi-Tao Huang is a Chinese-born American electrical engineer and computer scientist. He is a researcher and professor emeritus at the University of Illinois at Urbana-Champaign (UIUC). Huang is one of the leading figures in computer vision, pattern recognition and human computer interaction.
Structure from motion (SfM) is a photogrammetric range imaging technique for estimating three-dimensional structures from two-dimensional image sequences that may be coupled with local motion signals. It is studied in the fields of computer vision and visual perception. In biological vision, SfM refers to the phenomenon by which humans can recover 3D structure from the projected 2D (retinal) motion field of a moving object or scene.

Takeo Kanade is a Japanese computer scientist and one of the world's foremost researchers in computer vision. He is U.A. and Helen Whitaker Professor at Carnegie Mellon University. He has approximately 300 peer-reviewed academic publications and holds around 20 patents.

Mean shift is a non-parametric feature-space analysis technique for locating the maxima of a density function, a so-called mode-seeking algorithm. Application domains include cluster analysis in computer vision and image processing.
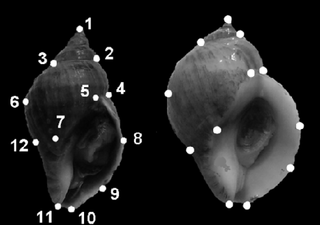
The point distribution model is a model for representing the mean geometry of a shape and some statistical modes of geometric variation inferred from a training set of shapes.
In computer vision, the bag-of-words model can be applied to image classification, by treating image features as words. In document classification, a bag of words is a sparse vector of occurrence counts of words; that is, a sparse histogram over the vocabulary. In computer vision, a bag of visual words is a vector of occurrence counts of a vocabulary of local image features.
Part-based models refers to a broad class of detection algorithms used on images, in which various parts of the image are used separately in order to determine if and where an object of interest exists. Amongst these methods a very popular one is the constellation model which refers to those schemes which seek to detect a small number of features and their relative positions to then determine whether or not the object of interest is present.
Caltech 101 is a data set of digital images created in September 2003 and compiled by Fei-Fei Li, Marco Andreetto, Marc 'Aurelio Ranzato and Pietro Perona at the California Institute of Technology. It is intended to facilitate Computer Vision research and techniques and is most applicable to techniques involving image recognition classification and categorization. Caltech 101 contains a total of 9,146 images, split between 101 distinct object categories and a background category. Provided with the images are a set of annotations describing the outlines of each image, along with a Matlab script for viewing.

Pedestrian detection is an essential and significant task in any intelligent video surveillance system, as it provides the fundamental information for semantic understanding of the video footages. It has an obvious extension to automotive applications due to the potential for improving safety systems. Many car manufacturers offer this as an ADAS option in 2017.
The random walker algorithm is an algorithm for image segmentation. In the first description of the algorithm, a user interactively labels a small number of pixels with known labels, e.g., "object" and "background". The unlabeled pixels are each imagined to release a random walker, and the probability is computed that each pixel's random walker first arrives at a seed bearing each label, i.e., if a user places K seeds, each with a different label, then it is necessary to compute, for each pixel, the probability that a random walker leaving the pixel will first arrive at each seed. These probabilities may be determined analytically by solving a system of linear equations. After computing these probabilities for each pixel, the pixel is assigned to the label for which it is most likely to send a random walker. The image is modeled as a graph, in which each pixel corresponds to a node which is connected to neighboring pixels by edges, and the edges are weighted to reflect the similarity between the pixels. Therefore, the random walk occurs on the weighted graph.

Multilinear subspace learning is an approach to dimensionality reduction. Dimensionality reduction can be performed on a data tensor whose observations have been vectorized and organized into a data tensor, or whose observations are matrices that are concatenated into a data tensor. Here are some examples of data tensors whose observations are vectorized or whose observations are matrices concatenated into data tensor images (2D/3D), video sequences (3D/4D), and hyperspectral cubes (3D/4D).
Multilinear principal component analysis (MPCA) is a multilinear extension of principal component analysis (PCA). MPCA is employed in the analysis of n-way arrays, i.e. a cube or hyper-cube of numbers, also informally referred to as a "data tensor". N-way arrays may be decomposed, analyzed, or modeled by
Medical image computing (MIC) is an interdisciplinary field at the intersection of computer science, information engineering, electrical engineering, physics, mathematics and medicine. This field develops computational and mathematical methods for solving problems pertaining to medical images and their use for biomedical research and clinical care.

Demetri Terzopoulos is a Distinguished Professor of Computer Science in the Henry Samueli School of Engineering and Applied Science at the University of California, Los Angeles, where he directs the UCLA Computer Graphics & Vision Laboratory.
Chessboards arise frequently in computer vision theory and practice because their highly structured geometry is well-suited for algorithmic detection and processing. The appearance of chessboards in computer vision can be divided into two main areas: camera calibration and feature extraction. This article provides a unified discussion of the role that chessboards play in the canonical methods from these two areas, including references to the seminal literature, examples, and pointers to software implementations.
In computer vision, rigid motion segmentation is the process of separating regions, features, or trajectories from a video sequence into coherent subsets of space and time. These subsets correspond to independent rigidly moving objects in the scene. The goal of this segmentation is to differentiate and extract the meaningful rigid motion from the background and analyze it. Image segmentation techniques labels the pixels to be a part of pixels with certain characteristics at a particular time. Here, the pixels are segmented depending on its relative movement over a period of time i.e. the time of the video sequence.