Protein engineering is the process of developing useful or valuable proteins through the design and production of unnatural polypeptides, often by altering amino acid sequences found in nature. It is a young discipline, with much research taking place into the understanding of protein folding and recognition for protein design principles. It has been used to improve the function of many enzymes for industrial catalysis. It is also a product and services market, with an estimated value of $168 billion by 2017.

In biochemistry, a nuclease is an enzyme capable of cleaving the phosphodiester bonds that link nucleotides together to form nucleic acids. Nucleases variously affect single and double stranded breaks in their target molecules. In living organisms, they are essential machinery for many aspects of DNA repair. Defects in certain nucleases can cause genetic instability or immunodeficiency. Nucleases are also extensively used in molecular cloning.
A cDNA library is a combination of cloned cDNA fragments inserted into a collection of host cells, which constitute some portion of the transcriptome of the organism and are stored as a "library". cDNA is produced from fully transcribed mRNA found in the nucleus and therefore contains only the expressed genes of an organism. Similarly, tissue-specific cDNA libraries can be produced. In eukaryotic cells the mature mRNA is already spliced, hence the cDNA produced lacks introns and can be readily expressed in a bacterial cell. While information in cDNA libraries is a powerful and useful tool since gene products are easily identified, the libraries lack information about enhancers, introns, and other regulatory elements found in a genomic DNA library.
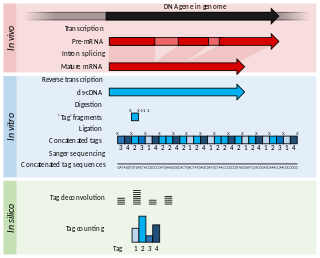
Serial Analysis of Gene Expression (SAGE) is a transcriptomic technique used by molecular biologists to produce a snapshot of the messenger RNA population in a sample of interest in the form of small tags that correspond to fragments of those transcripts. Several variants have been developed since, most notably a more robust version, LongSAGE, RL-SAGE and the most recent SuperSAGE. Many of these have improved the technique with the capture of longer tags, enabling more confident identification of a source gene.

In molecular biology, subcloning is a technique used to move a particular DNA sequence from a parent vector to a destination vector.
Restriction sites, or restriction recognition sites, are located on a DNA molecule containing specific sequences of nucleotides, which are recognized by restriction enzymes. These are generally palindromic sequences, and a particular restriction enzyme may cut the sequence between two nucleotides within its recognition site, or somewhere nearby.
A genomic library is a collection of overlapping DNA fragments that together make up the total genomic DNA of a single organism. The DNA is stored in a population of identical vectors, each containing a different insert of DNA. In order to construct a genomic library, the organism's DNA is extracted from cells and then digested with a restriction enzyme to cut the DNA into fragments of a specific size. The fragments are then inserted into the vector using DNA ligase. Next, the vector DNA can be taken up by a host organism - commonly a population of Escherichia coli or yeast - with each cell containing only one vector molecule. Using a host cell to carry the vector allows for easy amplification and retrieval of specific clones from the library for analysis.

EcoRV is a type II restriction endonuclease isolated from certain strains of Escherichia coli. It has the alternative name Eco32I.
Fragmentation describes the process of splitting into several pieces or fragments. In cell biology, fragmentation is useful for a cell during both DNA cloning and apoptosis. DNA cloning is important in asexual reproduction or creation of identical DNA molecules, and can be performed spontaneously by the cell or intentionally by laboratory researchers. Apoptosis is the programmed destruction of cells, and the DNA molecules within them, and is a highly regulated process. These two ways in which fragmentation is used in cellular processes describe normal cellular functions and common laboratory procedures performed with cells. However, problems within a cell can sometimes cause fragmentation that results in irregularities such as red blood cell fragmentation and sperm cell DNA fragmentation.
Artificial gene synthesis, or simply gene synthesis, refers to a group of methods that are used in synthetic biology to construct and assemble genes from nucleotides de novo. Unlike DNA synthesis in living cells, artificial gene synthesis does not require template DNA, allowing virtually any DNA sequence to be synthesized in the laboratory. It comprises two main steps, the first of which is solid-phase DNA synthesis, sometimes known as DNA printing. This produces oligonucleotide fragments that are generally under 200 base pairs. The second step then involves connecting these oligonucleotide fragments using various DNA assembly methods. Because artificial gene synthesis does not require template DNA, it is theoretically possible to make a completely synthetic DNA molecule with no limits on the nucleotide sequence or size.

BglII is a type II restriction endonuclease isolated from certain strains of Bacillus globigii.
DNA adenine methyltransferase identification, often abbreviated DamID, is a molecular biology protocol used to map the binding sites of DNA- and chromatin-binding proteins in eukaryotes. DamID identifies binding sites by expressing the proposed DNA-binding protein as a fusion protein with DNA methyltransferase. Binding of the protein of interest to DNA localizes the methyltransferase in the region of the binding site. Adenine methylation does not occur naturally in eukaryotes and therefore adenine methylation in any region can be concluded to have been caused by the fusion protein, implying the region is located near a binding site. DamID is an alternate method to ChIP-on-chip or ChIP-seq.
Paired-end tags (PET) are the short sequences at the 5’ and 3' ends of a DNA fragment which are unique enough that they (theoretically) exist together only once in a genome, therefore making the sequence of the DNA in between them available upon search or upon further sequencing. Paired-end tags (PET) exist in PET libraries with the intervening DNA absent, that is, a PET "represents" a larger fragment of genomic or cDNA by consisting of a short 5' linker sequence, a short 5' sequence tag, a short 3' sequence tag, and a short 3' linker sequence. It was shown conceptually that 13 base pairs are sufficient to map tags uniquely. However, longer sequences are more practical for mapping reads uniquely. The endonucleases used to produce PETs give longer tags but sequences of 50–100 base pairs would be optimal for both mapping and cost efficiency. After extracting the PETs from many DNA fragments, they are linked (concatenated) together for efficient sequencing. On average, 20–30 tags could be sequenced with the Sanger method, which has a longer read length. Since the tag sequences are short, individual PETs are well suited for next-generation sequencing that has short read lengths and higher throughput. The main advantages of PET sequencing are its reduced cost by sequencing only short fragments, detection of structural variants in the genome, and increased specificity when aligning back to the genome compared to single tags, which involves only one end of the DNA fragment.
Massive parallel sequencing or massively parallel sequencing is any of several high-throughput approaches to DNA sequencing using the concept of massively parallel processing; it is also called next-generation sequencing (NGS) or second-generation sequencing. Some of these technologies emerged between 1993 and 1998 and have been commercially available since 2005. These technologies use miniaturized and parallelized platforms for sequencing of 1 million to 43 billion short reads per instrument run.
DNA ends refer to the properties of the ends of linear DNA molecules, which in molecular biology are described as "sticky" or "blunt" based on the shape of the complementary strands at the terminus. In sticky ends, one strand is longer than the other, such that the longer strand has bases which are left unpaired. In blunt ends, both strands are of equal length – i.e. they end at the same base position, leaving no unpaired bases on either strand.

ChIP-exo is a chromatin immunoprecipitation based method for mapping the locations at which a protein of interest binds to the genome. It is a modification of the ChIP-seq protocol, improving the resolution of binding sites from hundreds of base pairs to almost one base pair. It employs the use of exonucleases to degrade strands of the protein-bound DNA in the 5'-3' direction to within a small number of nucleotides of the protein binding site. The nucleotides of the exonuclease-treated ends are determined using some combination of DNA sequencing, microarrays, and PCR. These sequences are then mapped to the genome to identify the locations on the genome at which the protein binds.

Jumping libraries or junction-fragment libraries are collections of genomic DNA fragments generated by chromosome jumping. These libraries allow the analysis of large areas of the genome and overcome distance limitations in common cloning techniques. A jumping library clone is composed of two stretches of DNA that are usually located many kilobases away from each other. The stretch of DNA located between these two "ends" is deleted by a series of biochemical manipulations carried out at the start of this cloning technique.

Ligation is the joining of two nucleotides, or two nucleic acid fragments, into a single polymeric chain through the action of an enzyme known as a ligase. The reaction involves the formation of a phosphodiester bond between the 3'-hydroxyl terminus of one nucleotide and the 5'-phosphoryl terminus of another nucleotide, which results in the two nucleotides being linked consecutively on a single strand. Ligation works in fundamentally the same way for both DNA and RNA. A cofactor is generally involved in the reaction, usually ATP or NAD+. Eukaryotic ligases belong to the ATP type, while the NAD+ type are found in bacteria (e.g. E. coli).

Duplex sequencing is a library preparation and analysis method for next-generation sequencing (NGS) platforms that employs random tagging of double-stranded DNA to detect mutations with higher accuracy and lower error rates.
This glossary of cellular and molecular biology is a list of definitions of terms and concepts commonly used in the study of cell biology, molecular biology, and related disciplines, including molecular genetics, biochemistry, and microbiology. It is split across two articles:
