Related Research Articles

Hypertext is text displayed on a computer display or other electronic devices with references (hyperlinks) to other text that the reader can immediately access. Hypertext documents are interconnected by hyperlinks, which are typically activated by a mouse click, keypress set, or screen touch. Apart from text, the term "hypertext" is also sometimes used to describe tables, images, and other presentational content formats with integrated hyperlinks. Hypertext is one of the key underlying concepts of the World Wide Web, where Web pages are often written in the Hypertext Markup Language (HTML). As implemented on the Web, hypertext enables the easy-to-use publication of information over the Internet.
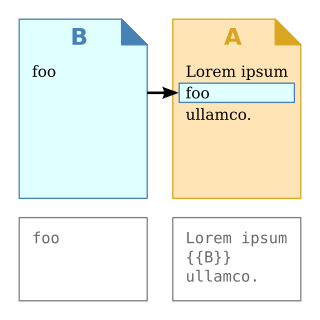
In computer science, transclusion is the inclusion of part or all of an electronic document into one or more other documents by reference via hypertext. Transclusion is usually performed when the referencing document is displayed, and is normally automatic and transparent to the end user. The result of transclusion is a single integrated document made of parts assembled dynamically from separate sources, possibly stored on different computers in disparate places.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.

In computing, a hyperlink, or simply a link, is a digital reference to data that the user can follow or be guided to by clicking or tapping. A hyperlink points to a whole document or to a specific element within a document. Hypertext is text with hyperlinks. The text that is linked from is known as anchor text. A software system that is used for viewing and creating hypertext is a hypertext system, and to create a hyperlink is to hyperlink. A user following hyperlinks is said to navigate or browse the hypertext.
Project Xanadu was the first hypertext project, founded in 1960 by Ted Nelson. Administrators of Project Xanadu have declared it superior to the World Wide Web, with the mission statement: "Today's popular software simulates paper. The World Wide Web trivialises our original hypertext model with one-way ever-breaking links and no management of version or contents."
Information architecture (IA) is the structural design of shared information environments; the art and science of organizing and labelling websites, intranets, online communities and software to support usability and findability; and an emerging community of practice focused on bringing principles of design, architecture and information science to the digital landscape. Typically, it involves a model or concept of information that is used and applied to activities which require explicit details of complex information systems. These activities include library systems and database development.
Hypermedia, an extension of hypertext, is a nonlinear medium of information that includes graphics, audio, video, plain text and hyperlinks. This designation contrasts with the broader term multimedia, which may include non-interactive linear presentations as well as hypermedia. The term was first used in a 1965 article written by Ted Nelson. Hypermedia is a type of multimedia that features interactive elements, such as hypertext, buttons, or interactive images and videos, allowing users to navigate and engage with content in a non-linear manner.
REST is a software architectural style that was created to guide the design and development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of a distributed, Internet-scale hypermedia system, such as the Web, should behave. The REST architectural style emphasises uniform interfaces, independent deployment of components, the scalability of interactions between them, and creating a layered architecture to promote caching to reduce user-perceived latency, enforce security, and encapsulate legacy systems.
NLS was a revolutionary computer collaboration system developed in the 1960s. It was designed by Douglas Engelbart and implemented by researchers at the Augmentation Research Center (ARC) at the Stanford Research Institute (SRI). It was the first computer system to employ the practical use of hypertext links, a computer mouse, raster-scan video monitors, information organized by relevance, screen windowing, presentation programs, and other modern computing concepts. It was funded by ARPA, NASA, and the US Air Force.
Personalization consists of tailoring a service or product to accommodate specific individuals. It is sometimes tied to groups or segments of individuals. Personalization involves collecting data on individuals, including web browsing history, web cookies, and location. Various organizations use personalization to improve customer satisfaction, digital sales conversion, marketing results, branding, and improved website metrics as well as for advertising. Personalization acts as a key element in social media and recommender systems. Personalization influences every sector of society — be it work, leisure, or citizenship.
Web Modeling Language, (WebML) is a visual notation and methodology for the design of a data-intensive web applications. It provides a graphical means to define the specifics of web application design within a structured design process. This process can be enhanced with the assistance of visual design tools.
Hypervideo, or hyperlinked video, is a displayed video stream that contains embedded, interactive anchors, allowing navigation between video and other hypermedia elements. Hypervideo is similar to hypertext, which allows a reader to click on a word in one document and retrieve information from another document, or another place in the same document. Hypervideo combines video with a non-linear information structure, allowing a user to make choices based on the content of the video and the user's interests.
KMS, an abbreviation of Knowledge Management System, was a commercial second generation hypermedia system, originally created as a successor for the early hypermedia system ZOG. KMS was developed by Don McCracken and Rob Akscyn of Knowledge Systems, a 1981 spinoff from the Computer Science Department of Carnegie Mellon University.
User modeling is the subdivision of human–computer interaction which describes the process of building up and modifying a conceptual understanding of the user. The main goal of user modeling is customization and adaptation of systems to the user's specific needs. The system needs to "say the 'right' thing at the 'right' time in the 'right' way". To do so it needs an internal representation of the user. Another common purpose is modeling specific kinds of users, including modeling of their skills and declarative knowledge, for use in automatic software-tests. User-models can thus serve as a cheaper alternative to user testing but should not replace user testing.
An adaptive website is a website that builds a model of user activity and modifies the information and/or presentation of information to the user in order to better address the user's needs.
Learning analytics is the measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimizing learning and the environments in which it occurs. The growth of online learning since the 1990s, particularly in higher education, has contributed to the advancement of Learning Analytics as student data can be captured and made available for analysis. When learners use an LMS, social media, or similar online tools, their clicks, navigation patterns, time on task, social networks, information flow, and concept development through discussions can be tracked. The rapid development of massive open online courses (MOOCs) offers additional data for researchers to evaluate teaching and learning in online environments.

Hypertext is text displayed on a computer or other electronic device with references (hyperlinks) to other text that the reader can immediately access, usually by a mouse click or keypress sequence. Early conceptions of hypertext defined it as text that could be connected by a linking system to a range of other documents that were stored outside that text. In 1934 Belgian bibliographer, Paul Otlet, developed a blueprint for links that telescoped out from hypertext electrically to allow readers to access documents, books, photographs, and so on, stored anywhere in the world.

Web navigation refers to the process of navigating a network of information resources in the World Wide Web, which is organized as hypertext or hypermedia. The user interface that is used to do so is called a web browser.
Peter Brusilovsky is a professor of information science and intelligent systems at the University of Pittsburgh. He is known as one of the pioneers of adaptive hypermedia, adaptive web design, and web-based adaptive learning. He has published numerous articles in user modeling, personalization, educational technology, intelligent tutoring systems, and information access. As of February 2015 Brusilovsky was ranked as #1 in the world in the area of computer education and #21 in the world in the area of World Wide Web by Microsoft Academic Search. According to Google Scholar as of April 2018, he has over 33,000 citations and h-index of 77. Brusilovsky's group has been awarded best paper awards at Adaptive Hypermedia, User Modeling, Hypertext, IUI, ICALT, and EC-TEL conference series, including five James Chen Best Student paper awards.
Social navigation is a form of social computing introduced by Paul Dourish and Matthew Chalmers in 1994, who defined it as when "movement from one item to another is provoked as an artifact of the activity of another or a group of others". According to later research in 2002, "social navigation exploits the knowledge and experience of peer users of information resources" to guide users in the information space, and that it is becoming more difficult to navigate and search efficiently with all the digital information available from the World Wide Web and other sources. Studying others' navigational trails and understanding their behavior can help improve one's own search strategy by guiding them to make more informed decisions based on the actions of others.
References
- 1 2 3 Brusilovsky, Peter (2001). "Adaptive Hypermedia". User Modeling and User-Adapted Interaction. 11 (1–2): 87–110. doi: 10.1023/A:1011143116306 .
- ↑ Weber, Gerherd; Peter Brusilovsky (2003). "ELM-ART: An adaptive versatile system for Web-based instruction". International Journal of Artificial Intelligence in Education. 13 (2–4): 159–172.
- ↑ Brusilovsky, Peter; John Eklund (1998). "A study of user-model based link annotation in educational hypermedia". Journal of Universal Computer Science. 4 (4): 429–448.
- ↑ Paul De Bra; Licia Calvi (1998). "AHA! An open Adaptive Hypermedia Architecture". The New Review of Hypermedia and Multimedia. 4: 115–139. doi:10.1080/13614569808914698.
- 1 2 3 4 5 6 7 8 9 Brusilovsky, Peter (1996). "Methods and Techniques of Adaptive Hypermedia". User Modeling and User-Adapted Interaction. 6 (2–3): 87–129. doi:10.1007/bf00143964. hdl: 10818/31086 . S2CID 16808655.
- ↑ De Bra, Paul; Calvi, Licia. "AHA: a Generic Adaptive Hypermedia System" . Retrieved 1 April 2013.
- ↑ Rodríguez, Verónica; Ayala, Gerardo (2012). "Adaptivity and Adaptability of Learning Object's Interface". International Journal of Computer Applications. 37 (1): 6. Bibcode:2012IJCA...37a...6R. doi: 10.5120/4570-6535 .
- 1 2 3 4 5 6 7 8 Benyon, David; Murray, Dianne. "Applying user modelling to human-computer interaction design" (PDF). lucite. Archived from the original (PDF) on November 28, 2021. Retrieved 4 March 2013.
- ↑ Wahlster, W.; Kobsa, A. (1987). "Dialogue-based user models". Proc. IEEE. 74 (4).
- 1 2 3 Triantafillou, E, Pomportsis, A, & Demetriadis, S. (2003). The design and the formative evaluation of an adaptive educational system based on cognitive styles. Computers & Education, 41(87-103), Retrieved from http://www.cdli.ca/~bmann/0_ARTICLES/FormEval_Triantafillou_03.pdf doi : 10.1016/S0360-1315(03)00031-9
- 1 2 3 Brusilovsky, Peter (2003). "Developing Adaptive Educational Hypermedia Systems: From Design Models to Authoring Tools". Authoring Tools for Advanced Technology Learning Environments: Toward cost-effective adaptive, interactive, and intelligent educational software (PDF). Kluwer. ISBN 978-1-4020-1772-8.
- 1 2 3 De Bra, Paul; Houben, Geert-Jan; Wu, Hongjing. "AHA: AHAM: A Reference Model to Support Adaptive Hypermedia Authoring" . Retrieved 1 April 2013.
- ↑ LAG language by Alexandra I. Cristea et al., the LAG-XLS language by Natalia Stash et al.
- ↑ "Dr. Alexandra Cristea: MOT (My Online Teacher)". Archived from the original on 2012-02-12. Retrieved 2016-04-23.
- ↑ "OPAH - Opah". Archived from the original on 2013-06-08. Retrieved 2016-04-23.
- Cristea, A. (2005). Authoring of Adaptive Hypermedia. Educational Technology & Society, 8 (3), 6-8. ()
- A. Cristea and L. Aroyo, Adaptive Authoring of Adaptive Educational Hypermedia, AH 2002, Adaptive Hypermedia and Adaptive Web-Based Systems, LNCS 2347, Springer, 122-132 "Archived copy" (PDF). Archived from the original (PDF) on 2010-02-16. Retrieved 2008-02-28.
{{cite web}}: CS1 maint: archived copy as title (link)