In software quality assurance, performance testing is in general a testing practice performed to determine how a system performs in terms of responsiveness and stability under a particular workload. It can also serve to investigate, measure, validate or verify other quality attributes of the system, such as scalability, reliability and resource usage.
In computing, booting is the process of starting a computer. It can be initiated by hardware such as a button press, or by a software command. After it is switched on, a computer's central processing unit (CPU) has no software in its main memory, so some process must load software into memory before it can be executed. This may be done by hardware or firmware in the CPU, or by a separate processor in the computer system.
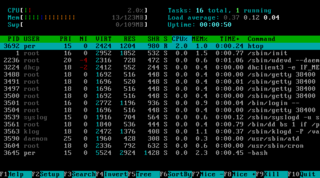
In computing, a process is the instance of a computer program that is being executed by one or many threads. It contains the program code and its activity. Depending on the operating system (OS), a process may be made up of multiple threads of execution that execute instructions concurrently.

In computer science, a library is a collection of non-volatile resources used by computer programs, often for software development. These may include configuration data, documentation, help data, message templates, pre-written code and subroutines, classes, values or type specifications. In IBM's OS/360 and its successors they are referred to as partitioned data sets.
In computer science, algorithmic efficiency is a property of an algorithm which relates to the number of computational resources used by the algorithm. An algorithm must be analyzed to determine its resource usage, and the efficiency of an algorithm can be measured based on usage of different resources. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.
In compiler theory, dead code elimination is a compiler optimization to remove code which does not affect the program results. Removing such code has several benefits: it shrinks program size, an important consideration in some contexts, and it allows the running program to avoid executing irrelevant operations, which reduces its running time. It can also enable further optimizations by simplifying program structure. Dead code includes code that can never be executed, and code that only affects dead variables, that is, irrelevant to the program.
Memory protection is a way to control memory access rights on a computer, and is a part of most modern instruction set architectures and operating systems. The main purpose of memory protection is to prevent a process from accessing memory that has not been allocated to it. This prevents a bug or malware within a process from affecting other processes, or the operating system itself. Protection may encompass all accesses to a specified area of memory, write accesses, or attempts to execute the contents of the area. An attempt to access unauthorized memory results in a hardware fault, e.g., a segmentation fault, storage violation exception, generally causing abnormal termination of the offending process. Memory protection for computer security includes additional techniques such as address space layout randomization and executable space protection.
Bare-metal restore is a technique in the field of data recovery and restoration where the backed up data is available in a form which allows one to restore a computer system from "bare metal", i.e. without any requirements as to previously installed software or operating system.
Hard coding is the software development practice of embedding data directly into the source code of a program or other executable object, as opposed to obtaining the data from external sources or generating it at run-time. Hard-coded data typically can only be modified by editing the source code and recompiling the executable, although it can be changed in memory or on disk using a debugger or hex editor. Data that are hard-coded usually represent unchanging pieces of information, such as physical constants, version numbers and static text elements. Softcoded data, on the other hand, encode arbitrary information like user input, HTTP server responses, or configuration files, and are determined at runtime.

A diskless node is a workstation or personal computer without disk drives, which employs network booting to load its operating system from a server.
In computing, hardware acceleration is the use of computer hardware specially made to perform some functions more efficiently than is possible in software running on a general-purpose central processing unit (CPU). Any transformation of data or routine that can be computed, can be calculated purely in software running on a generic CPU, purely in custom-made hardware, or in some mix of both. An operation can be computed faster in application-specific hardware designed or programmed to compute the operation than specified in software and performed on a general-purpose computer processor. Each approach has advantages and disadvantages. The implementation of computing tasks in hardware to decrease latency and increase throughput is known as hardware acceleration.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
Database tuning describes a group of activities used to optimize and homogenize the performance of a database. It usually overlaps with query tuning, but refers to design of the database files, selection of the database management system (DBMS) application, and configuration of the database's environment.
There are a number of security and safety features new to Windows Vista, most of which are not available in any prior Microsoft Windows operating system release.
Memory footprint refers to the amount of main memory that a program uses or references while running.
Microsoft SQL Server is a relational database management system developed by Microsoft. As a database server, it is a software product with the primary function of storing and retrieving data as requested by other software applications—which may run either on the same computer or on another computer across a network.

Raima Database Manager is an ACID-compliant embedded database management system designed for use in embedded systems applications. RDM has been designed to utilize multi-core computers, networking, and on-disk or in-memory storage management. RDM provides support for multiple application programming interfaces (APIs): low-level C API, C++, and SQL(native, ODBC, JDBC, ADO.NET, and LabView). RDM is highly portable and is available on Windows, Linux, Unix and several real-time or embedded operating systems. A source-code license is also available.
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software that requires access to stored data, such that the database system is "hidden" from the application’s end-user and requires little or no ongoing maintenance. It is actually a broad technology category that includes
Disk footprint of a software application refers to its sizing information when it's in an inactive state, or in other words, when it's not executing but stored on a secondary media or downloaded over a network connection. It gives a sense of the size of an application, typically expressed in units of computer bytes that would be required to store the application on a media device or to be transmitted over a network. Due to organization of modern software applications, disk footprint may not be the best indicator of its actual execution time memory requirements - a tiny application that has huge memory requirements or loads a large number dynamically linked libraries, may not have comparable disk footprint vis-a-vis its runtime footprint.