This article is about the computer memory management technique. For the technique of pooling multiple storage devices, see Storage virtualization. For the TBN game show, see Virtual Memory (game show).
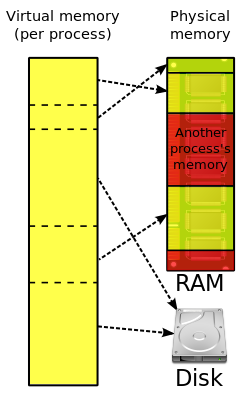
Virtual memory combines active RAM and inactive memory on DASD to form a large range of contiguous addresses.
In computing, virtual memory, or virtual storage,[b] is a memory management technique that provides an "idealized abstraction of the storage resources that are actually available on a given machine"[3] which "creates the illusion to users of a very large (main) memory".[4]
The computer's operating system, using a combination of hardware and software, maps memory addresses used by a program, called virtual addresses, into physical addresses in computer memory. Main storage, as seen by a process or task, appears as a contiguous address space or collection of contiguous segments. The operating system manages virtual address spaces and the assignment of real memory to virtual memory.[5] Address translation hardware in the CPU, often referred to as a memory management unit (MMU), automatically translates virtual addresses to physical addresses. Software within the operating system may extend these capabilities, utilizing, e.g., disk storage, to provide a virtual address space that can exceed the capacity of real memory and thus reference more memory than is physically present in the computer.
The primary benefits of virtual memory include freeing applications from having to manage a shared memory space, ability to share memory used by libraries between processes, increased security due to memory isolation, and being able to conceptually use more memory than might be physically available, using the technique of paging or segmentation.
Properties
Virtual memory makes application programming easier by hiding fragmentation of physical memory; by delegating to the kernel the burden of managing the memory hierarchy (eliminating the need for the program to handle overlays explicitly); and, when each process is run in its own dedicated address space, by obviating the need to relocate program code or to access memory with relative addressing.
Memory virtualization can be considered a generalization of the concept of virtual memory.
Virtual memory is an integral part of a modern computer architecture; implementations usually require hardware support, typically in the form of a memory management unit built into the CPU. While not necessary, emulators and virtual machines can employ hardware support to increase performance of their virtual memory implementations.[6]
Most modern operating systems that support virtual memory also run each process in its own dedicated address space. Each program thus appears to have sole access to the virtual memory. Some older operating systems (such as OS/VS1 and OS/VS2 SVS) and even later ones (such as IBM i) are single address space operating systems that run all processes in a single address space composed of virtualized memory.
Embedded systems and other special-purpose computer systems that require very fast and/or very consistent response times may opt not to use virtual memory due to decreased determinism; virtual memory systems trigger unpredictable traps that may produce unwanted and unpredictable delays in response to input, especially if the trap requires that data be read into main memory from secondary memory. The hardware to translate virtual addresses to physical addresses typically requires a significant chip area to implement, and not all chips used in embedded systems include that hardware, which is another reason some of those systems do not use virtual memory.
During the 1950s, 1960s, and early 1970s, computer memory was very expensive. Larger programs for which the available memory was not large enough to hold all the code and data had to contain logic for managing primary and secondary storage, such as overlaying. Virtual memory was therefore introduced not only to extend primary memory, but to make such an extension as easy as possible for programmers to use.[7]
The University of Manchester Atlas Computer was the first computer to feature true virtual memory.
The first true virtual memory system was that implemented at the University of Manchester to create a one-level storage system[8] as part of the Atlas Computer. It used a paging mechanism to map the virtual addresses available to the programmer onto the real memory that consisted of 16,384 words of primary core memory with an additional 98,304 words of secondary drum memory.[9] The addition of virtual memory into the Atlas also eliminated a looming programming problem: planning and scheduling data transfers between main and secondary memory and recompiling programs for each change of size of main memory.[10] The first Atlas was commissioned in 1962 but working prototypes of paging had been developed by 1959.[7]:2[11][12]
A claim that the concept of virtual memory was first developed by German physicist Fritz-Rudolf Güntsch at the Technische Universität Berlin in 1956 in his doctoral thesis, Logical Design of a Digital Computer with Multiple Asynchronous Rotating Drums and Automatic High Speed Memory Operation,[13][14] does not stand up to careful scrutiny. The computer proposed by Güntsch (but never built) had an address space of 105 words which mapped exactly onto the 105 words of the drums, i.e. the addresses were real addresses and there was no form of indirect mapping, a key feature of virtual memory. What Güntsch did invent was a form of cache memory, since his high-speed memory was intended to contain a copy of some blocks of code or data taken from the drums. Indeed, he wrote (as quoted in translation[15]): "The programmer need not respect the existence of the primary memory (he need not even know that it exists), for there is only one sort of addresses [sic] by which one can program as if there were only one storage." This is exactly the situation in computers with cache memory, one of the earliest commercial examples of which was the IBM System/360 Model 85.[16] In the Model 85 all addresses were real addresses referring to the main core store. A semiconductor cache store, invisible to the user, held the contents of parts of the main store in use by the currently executing program. This is exactly analogous to Güntsch's system, designed as a means to improve performance, rather than to solve the problems involved in multi-programming.
As early as 1958, Robert S. Barton, working at Shell Research, suggested that main storage should be allocated automatically rather than have the programmer being concerned with overlays from secondary memory, in effect virtual memory.[17]:49[18] By 1960 Barton was lead architect on the BurroughsB5000 project. From 1959 to 1961, W. R. Lonergan was manager of the Burroughs Product Planning Group which included Barton, Donald Knuth as consultant, and Paul King. In May 1960, UCLA ran a two-week seminar "Using and Exploiting Giant Computers" to which Paul King and two others were sent. Stan Gill gave a presentation on virtual memory in the Atlas I computer. Paul King took the ideas back to Burroughs and it was determined that virtual memory should be designed into the core of the B5000.[17]:3. Burroughs Corporation released the B5000 in 1964 as the first commercial computer with virtual memory.[19]
IBM developed[c] the concept of hypervisors in their CP-40 and CP-67, and in 1972 provided it for the S/370 as Virtual Machine Facility/370.[21] IBM introduced the Start Interpretive Execution (SIE) instruction as part of 370-XA on the 3081, and VM/XA versions of VM to exploit it.
Before virtual memory could be implemented in mainstream operating systems, many problems had to be addressed. Dynamic address translation required expensive and difficult-to-build specialized hardware; initial implementations slowed down access to memory slightly.[7] There were worries that new system-wide algorithms utilizing secondary storage would be less effective than previously used application-specific algorithms. By 1969, the debate over virtual memory for commercial computers was over;[7] an IBM research team led by David Sayre showed that their virtual memory overlay system consistently worked better than the best manually controlled systems.[22]
Operating systems supporting virtual memory on mainframes of the 1960s include:
The introduction of virtual memory provided an ability for software systems with large memory demands to run on computers with less real memory. The savings from this provided a strong incentive to switch to virtual memory for all systems. The additional capability of providing virtual address spaces added another level of security and reliability, thus making virtual memory even more attractive to the marketplace.
Throughout the 1970s, the IBM System/370 series running their virtual-storage based operating systems provided a means for business users to migrate multiple older systems into fewer, more powerful, mainframes that had improved price/performance. The first minicomputer to introduce virtual memory was the Norwegian NORD-1; during the 1970s, other minicomputers implemented virtual memory, notably VAX models running VMS.
Virtual memory was introduced to the x86 architecture with the protected mode of the Intel 80286 processor, but its segment swapping technique scaled poorly to larger segment sizes. The Intel 80386 introduced paging support underneath the existing segmentation layer, enabling the page fault exception to chain with other exceptions without double fault. However, loading segment descriptors was an expensive operation, causing operating system designers to rely strictly on paging rather than a combination of paging and segmentation.[23]
Nearly all current implementations of virtual memory divide a virtual address space into pages, blocks of contiguous virtual memory addresses. Pages on contemporary[d] systems are usually at least 4 kilobytes in size; systems with large virtual address ranges or amounts of real memory generally use larger page sizes.[24]
Page tables
Page tables are used to translate the virtual addresses seen by the application into physical addresses used by the hardware to process instructions;[25] such hardware that handles this specific translation is often known as the memory management unit. Each entry in the page table holds a flag indicating whether the corresponding page is in real memory or not. If it is in real memory, the page table entry will contain the real memory address at which the page is stored. When a reference is made to a page by the hardware, if the page table entry for the page indicates that it is not currently in real memory, the hardware raises a page faultexception, invoking the paging supervisor component of the operating system.
Systems can have, e.g., one page table for the whole system, separate page tables for each address space or process, separate page tables for each segment; similarly, systems can have, e.g., no segment table, one segment table for the whole system, separate segment tables for each address space or process, separate segment tables for each region in a tree[e] of region tables for each address space or process. If there is only one page table, different applications running at the same time use different parts of a single range of virtual addresses. If there are multiple page or segment tables, there are multiple virtual address spaces and concurrent applications with separate page tables redirect to different real addresses.
Some earlier systems with smaller real memory sizes, such as the SDS 940, used page registers instead of page tables in memory for address translation.
Paging supervisor
This part of the operating system creates and manages page tables and lists of free page frames. In order to ensure that there will be enough free page frames to quickly resolve page faults, the system may periodically steal allocated page frames, using a page replacement algorithm, e.g., a least recently used (LRU) algorithm. Stolen page frames that have been modified are written back to auxiliary storage before they are added to the free queue. On some systems the paging supervisor is also responsible for managing translation registers that are not automatically loaded from page tables.
Typically, a page fault that cannot be resolved results in an abnormal termination of the application. However, some systems allow the application to have exception handlers for such errors. The paging supervisor may handle a page fault exception in several different ways, depending on the details:
If the virtual address is invalid, the paging supervisor treats it as an error.
If the page is valid and the page information is not loaded into the MMU, the page information will be stored into one of the page registers.
If the page is uninitialized, a new page frame may be assigned and cleared.
If there is a stolen page frame containing the desired page, that page frame will be reused.
For a fault due to a write attempt into a read-protected page, if it is a copy-on-write page then a free page frame will be assigned and the contents of the old page copied; otherwise it is treated as an error.
If the virtual address is a valid page in a memory-mapped file or a paging file, a free page frame will be assigned and the page read in.
In most cases, there will be an update to the page table, possibly followed by purging the Translation Lookaside Buffer (TLB), and the system restarts the instruction that causes the exception.
If the free page frame queue is empty then the paging supervisor must free a page frame using the same page replacement algorithm for page stealing.
Pinned pages
Operating systems have memory areas that are pinned (never swapped to secondary storage). Other terms used are locked, fixed, or wired pages. For example, interrupt mechanisms rely on an array of pointers to their handlers, such as I/O completion and page fault. If the pages containing these pointers or the code that they invoke were pageable, interrupt-handling would become far more complex and time-consuming, particularly in the case of page fault interruptions. Hence, some part of the page table structures is not pageable.
Some pages may be pinned for short periods of time, others may be pinned for long periods of time, and still others may need to be permanently pinned. For example:
The paging supervisor code and drivers for secondary storage devices on which pages reside must be permanently pinned, as otherwise paging would not even work because the necessary code would not be available.
Timing-dependent components may be pinned to avoid variable paging delays.
Data buffers that are accessed directly by peripheral devices that use direct memory access or I/O channels must reside in pinned pages while the I/O operation is in progress because such devices and the buses to which they are attached expect to find data buffers located at physical memory addresses; regardless of whether the bus has a memory management unit for I/O, transfers cannot be stopped if a page fault occurs and then restarted when the page fault has been processed. For example, the data could come from a measurement sensor unit and lost real time data that got lost because of a page fault can not be recovered.
In IBM's operating systems for System/370 and successor systems, the term is "fixed", and such pages may be long-term fixed, or may be short-term fixed, or may be unfixed (i.e., pageable). System control structures are often long-term fixed (measured in wall-clock time, i.e., time measured in seconds, rather than time measured in fractions of one second) whereas I/O buffers are usually short-term fixed (usually measured in significantly less than wall-clock time, possibly for tens of milliseconds). Indeed, the OS has a special facility for "fast fixing" these short-term fixed data buffers (fixing which is performed without resorting to a time-consuming Supervisor Call instruction).
Multics used the term "wired". OpenVMS and Windows refer to pages temporarily made nonpageable (as for I/O buffers) as "locked", and simply "nonpageable" for those that are never pageable. The Single UNIX Specification also uses the term "locked" in the specification for mlock(), as do the mlock()man pages on many Unix-like systems.
Virtual-real operation
In OS/VS1 and similar OSes, some parts of systems memory are managed in "virtual-real" mode, called "V=R". In this mode every virtual address corresponds to the same real address. This mode is used for interrupt mechanisms, for the paging supervisor and page tables in older systems, and for application programs using non-standard I/O management. For example, IBM's z/OS has 3 modes (virtual-virtual, virtual-real and virtual-fixed).[citation needed]
Thrashing
When paging and page stealing are used, a problem called "thrashing"[27] can occur, in which the computer spends an unsuitably large amount of time transferring pages to and from a backing store, hence slowing down useful work. A task's working set is the minimum set of pages that should be in memory in order for it to make useful progress. Thrashing occurs when there is insufficient memory available to store the working sets of all active programs. Adding real memory is the simplest response, but improving application design, scheduling, and memory usage can help. Another solution is to reduce the number of active tasks on the system. This reduces demand on real memory by swapping out the entire working set of one or more processes.
A system thrashing is often a result of a sudden spike in page demand from a small number of running programs. Swap-token[28] is a lightweight and dynamic thrashing protection mechanism. The basic idea is to set a token in the system, which is randomly given to a process that has page faults when thrashing happens. The process that has the token is given a privilege to allocate more physical memory pages to build its working set, which is expected to quickly finish its execution and to release the memory pages to other processes. A time stamp is used to handover the token one by one. The first version of swap-token was implemented in Linux 2.6.[29] The second version is called preempt swap-token and is also in Linux 2.6.[29] In this updated swap-token implementation, a priority counter is set for each process to track the number of swap-out pages. The token is always given to the process with a high priority, which has a high number of swap-out pages. The length of the time stamp is not a constant but is determined by the priority: the higher the number of swap-out pages of a process, the longer the time stamp for it will be.
Segmented virtual memory
Some systems, such as the Burroughs B5500,[30] and the current Unisys MCP systems[31] use segmentation instead of paging, dividing virtual address spaces into variable-length segments. Using segmentation matches the allocated memory blocks to the logical needs and requests of the programs, rather than the physical view of a computer, although pages themselves are an artificial division in memory. The designers of the B5000 would have found the artificial size of pages to be Procrustean in nature, a story they would later use for the exact data sizes in the B1700.[32]
In the Burroughs and Unisys systems, each memory segment is described by a master descriptor which is a single absolute descriptor which may be referenced by other relative (copy) descriptors, effecting sharing either within a process or between processes. Descriptors are central to the working of virtual memory in MCP systems. Descriptors contain not only the address of a segment, but the segment length and status in virtual memory indicated by the 'p-bit' or 'presence bit' which indicates if the address is to a segment in main memory or to a secondary-storage block. When a non-resident segment (p-bit is off) is accessed, an interrupt occurs to load the segment from secondary storage at the given address, or if the address itself is 0 then allocate a new block. In the latter case, the length field in the descriptor is used to allocate a segment of that length.
A further problem to thrashing in using a segmented scheme is checkerboarding,[33] where all free segments become too small to satisfy requests for new segments. The solution is to perform memory compaction to pack all used segments together and create a large free block from which further segments may be allocated. Since there is a single master descriptor for each segment the new block address only needs to be updated in a single descriptor, since all copies refer to the master descriptor.
Paging is not free from fragmentation – the fragmentation is internal to pages (internal fragmentation). If a requested block is smaller than a page, then some space in the page will be wasted. If a block requires larger than a page, a small area in another page is required resulting in large wasted space. The fragmentation thus becomes a problem passed to programmers who may well distort their program to match certain page sizes. With segmentation, the fragmentation is external to segments (external fragmentation) and thus a system problem, which was the aim of virtual memory in the first place, to relieve programmers of such memory considerations. In multi-processing systems, optimal operation of the system depends on the mix of independent processes at any time. Hybrid schemes of segmentation and paging may be used.
The Intel 80286 supports a similar segmentation scheme as an option, but it is rarely used.
Segmentation and paging can be used together by dividing each segment into pages; systems with this memory structure, such as Multics and IBM System/38, are usually paging-predominant, segmentation providing memory protection.[34][35][36]
In the Intel 80386 and later IA-32 processors, the segments reside in a 32-bit linear, paged address space. Segments can be moved in and out of that space; pages there can "page" in and out of main memory, providing two levels of virtual memory; few if any operating systems do so, instead using only paging. Early non-hardware-assisted x86 virtualization solutions combined paging and segmentation because x86 paging offers only two protection domains whereas a VMM, guest OS or guest application stack needs three.[37]:22 The difference between paging and segmentation systems is not only about memory division; segmentation is visible to user processes, as part of memory model semantics. Hence, instead of memory that looks like a single large space, it is structured into multiple spaces.
This difference has important consequences; a segment is not a page with variable length or a simple way to lengthen the address space. Segmentation that can provide a single-level memory model in which there is no differentiation between process memory and file system consists of only a list of segments (files) mapped into the process's potential address space.[38]
This is not the same as the mechanisms provided by calls such as mmap and Win32's MapViewOfFile, because inter-file pointers do not work when mapping files into semi-arbitrary places. In Multics, a file (or a segment from a multi-segment file) is mapped into a segment in the address space, so files are always mapped at a segment boundary. A file's linkage section can contain pointers for which an attempt to load the pointer into a register or make an indirect reference through it causes a trap. The unresolved pointer contains an indication of the name of the segment to which the pointer refers and an offset within the segment; the handler for the trap maps the segment into the address space, puts the segment number into the pointer, changes the tag field in the pointer so that it no longer causes a trap, and returns to the code where the trap occurred, re-executing the instruction that caused the trap.[39] This eliminates the need for a linker completely[7] and works when different processes map the same file into different places in their private address spaces.[40]
Address space swapping
Some operating systems provide for swapping entire address spaces, in addition to whatever facilities they have for paging and segmentation. When this occurs, the OS writes those pages and segments currently in real memory to swap files. In a swap-in, the OS reads back the data from the swap files but does not automatically read back pages that had been paged out at the time of the swap out operation.
IBM's MVS, from OS/VS2 Release 2 through z/OS, provides for marking an address space as unswappable; doing so does not pin any pages in the address space. This can be done for the duration of a job by entering the name of an eligible[41] main program in the Program Properties Table with an unswappable flag. In addition, privileged code can temporarily make an address space unswappable using a SYSEVENT Supervisor Call instruction (SVC); certain changes[42] in the address space properties require that the OS swap it out and then swap it back in, using SYSEVENT TRANSWAP.[43]
Swapping does not necessarily require memory management hardware, if, for example, multiple jobs are swapped in and out of the same area of storage.
↑Denning, Peter J. (1 January 2003). "Virtual memory". Encyclopedia of Computer Science. John Wiley and Sons. pp.1832–1835. ISBN978-0-470-86412-8. Retrieved 10 January 2023.
↑Sayre, D. (1969). "Is automatic 'folding' of programs efficient enough to displace manual?". Communications of the ACM. 12 (12): 656–660. doi:10.1145/363626.363629. S2CID15655353.
↑Song Jiang; Xiaodong Zhang (2005). "Token-ordered LRU: an effective page replacement policy and its implementation in Linux systems". Performance Evaluation. 60 (1–4): 5–29. doi:10.1016/j.peva.2004.10.002. ISSN0166-5316.
"Time-Sharing Supervisor Programs"(PDF). Archived from the original(PDF) on 1 November 2012. by Michael T. Alexander in Advanced Topics in Systems Programming, University of Michigan Engineering Summer Conference 1970 (revised May 1971), compares the scheduling and resource allocation approaches, including virtual memory and paging, used in four mainframe operating systems: CP-67, TSS/360, MTS, and Multics.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.