Overview
The average memory reference time is [1]

where
- = miss ratio = 1 - (hit ratio)
- = time to make main-memory access when there is a miss (or, with a multi-level cache, average memory reference time for the next-lower cache)
- = latency: time to reference the cache (should be the same for hits and misses)
- = secondary effects, such as queuing effects in multiprocessor systems




A cache has two primary figures of merit: latency and hit ratio. A number of secondary factors also affect cache performance. [1]
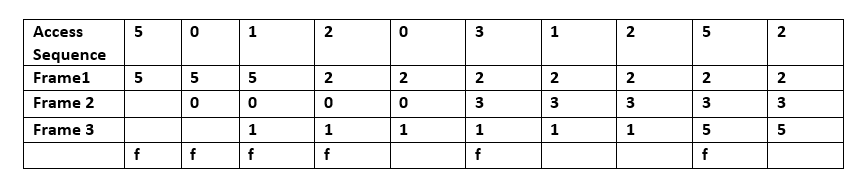
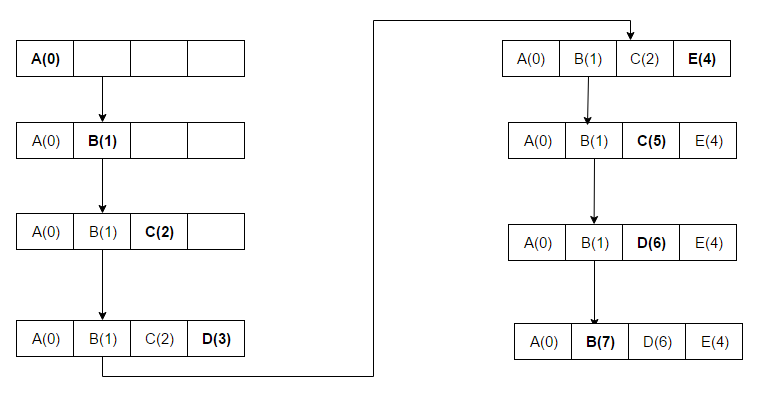
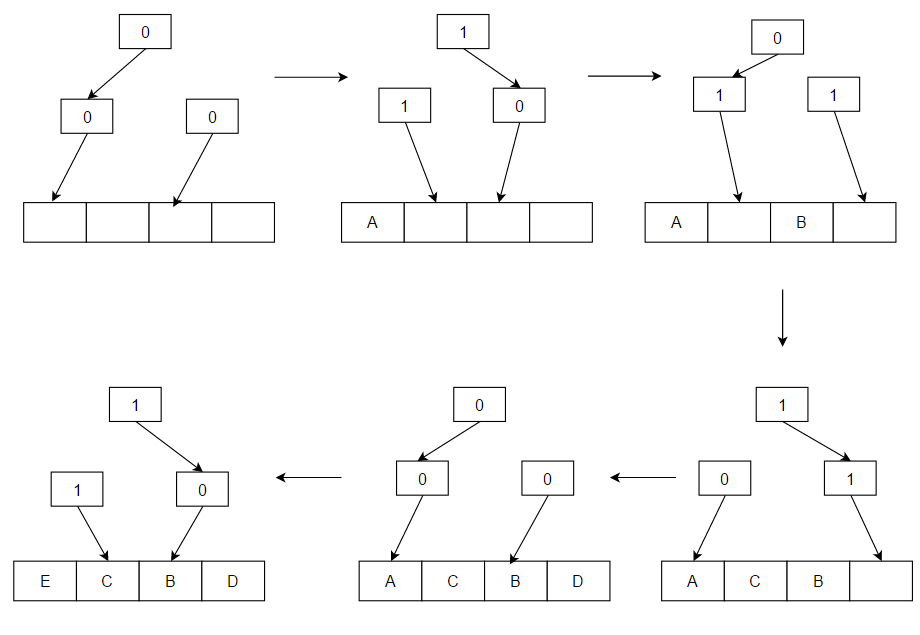
The hit ratio of a cache describes how often a searched-for item is found. More efficient replacement strategies track more usage information to improve the hit rate for a given cache size. The latency of a cache describes how long after requesting a desired item the cache can return that item when there is a hit. Faster replacement strategies typically track less usage information—or, with a direct-mapped cache, no information—to reduce the time required to update the information. Each replacement strategy is a compromise between hit rate and latency.
Hit-rate measurements are typically performed on benchmark applications, and the hit ratio varies by application. Video and audio streaming applications often have a hit ratio near zero, because each bit of data in the stream is read once (a compulsory miss), used, and then never read or written again. Many cache algorithms (particularly LRU) allow streaming data to fill the cache, pushing out information which will soon be used again (cache pollution). [2] Other factors may be size, length of time to obtain, and expiration. Depending on cache size, no further caching algorithm to discard items may be needed. Algorithms also maintain cache coherence when several caches are used for the same data, such as multiple database servers updating a shared data file.[ citation needed ]