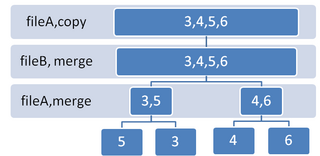
In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
In computer science, locality of reference, also known as the principle of locality, is the tendency of a processor to access the same set of memory locations repetitively over a short period of time. There are two basic types of reference locality – temporal and spatial locality. Temporal locality refers to the reuse of specific data and/or resources within a relatively small time duration. Spatial locality refers to the use of data elements within relatively close storage locations. Sequential locality, a special case of spatial locality, occurs when data elements are arranged and accessed linearly, such as traversing the elements in a one-dimensional array.

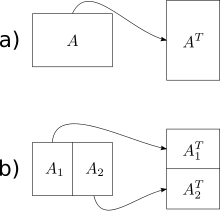
In mathematics, particularly in linear algebra, matrix multiplication is a binary operation that produces a matrix from two matrices. For matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix. The resulting matrix, known as the matrix product, has the number of rows of the first and the number of columns of the second matrix. The product of matrices A and B is denoted as AB.

Dynamic programming is both a mathematical optimization method and an algorithmic paradigm. The method was developed by Richard Bellman in the 1950s and has found applications in numerous fields, from aerospace engineering to economics.
In computer science, divide and conquer is an algorithm design paradigm. A divide-and-conquer algorithm recursively breaks down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.

A longest common subsequence (LCS) is the longest subsequence common to all sequences in a set of sequences. It differs from the longest common substring: unlike substrings, subsequences are not required to occupy consecutive positions within the original sequences. The problem of computing longest common subsequences is a classic computer science problem, the basis of data comparison programs such as the diff utility, and has applications in computational linguistics and bioinformatics. It is also widely used by revision control systems such as Git for reconciling multiple changes made to a revision-controlled collection of files.
The Cooley–Tukey algorithm, named after J. W. Cooley and John Tukey, is the most common fast Fourier transform (FFT) algorithm. It re-expresses the discrete Fourier transform (DFT) of an arbitrary composite size in terms of N1 smaller DFTs of sizes N2, recursively, to reduce the computation time to O(N log N) for highly composite N (smooth numbers). Because of the algorithm's importance, specific variants and implementation styles have become known by their own names, as described below.
In linear algebra, the Strassen algorithm, named after Volker Strassen, is an algorithm for matrix multiplication. It is faster than the standard matrix multiplication algorithm for large matrices, with a better asymptotic complexity, although the naive algorithm is often better for smaller matrices. The Strassen algorithm is slower than the fastest known algorithms for extremely large matrices, but such galactic algorithms are not useful in practice, as they are much slower for matrices of practical size. For small matrices even faster algorithms exist.
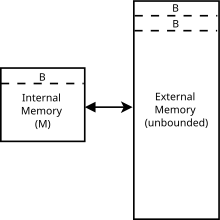
External sorting is a class of sorting algorithms that can handle massive amounts of data. External sorting is required when the data being sorted do not fit into the main memory of a computing device and instead they must reside in the slower external memory, usually a disk drive. Thus, external sorting algorithms are external memory algorithms and thus applicable in the external memory model of computation.
In computing, external memory algorithms or out-of-core algorithms are algorithms that are designed to process data that are too large to fit into a computer's main memory at once. Such algorithms must be optimized to efficiently fetch and access data stored in slow bulk memory such as hard drives or tape drives, or when memory is on a computer network. External memory algorithms are analyzed in the external memory model.
Automatically Tuned Linear Algebra Software (ATLAS) is a software library for linear algebra. It provides a mature open source implementation of BLAS APIs for C and FORTRAN 77.

Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
In-place matrix transposition, also called in-situ matrix transposition, is the problem of transposing an N×M matrix in-place in computer memory, ideally with O(1) (bounded) additional storage, or at most with additional storage much less than NM. Typically, the matrix is assumed to be stored in row-major or column-major order.
Because matrix multiplication is such a central operation in many numerical algorithms, much work has been invested in making matrix multiplication algorithms efficient. Applications of matrix multiplication in computational problems are found in many fields including scientific computing and pattern recognition and in seemingly unrelated problems such as counting the paths through a graph. Many different algorithms have been designed for multiplying matrices on different types of hardware, including parallel and distributed systems, where the computational work is spread over multiple processors.
In theoretical computer science, the computational complexity of matrix multiplication dictates how quickly the operation of matrix multiplication can be performed. Matrix multiplication algorithms are a central subroutine in theoretical and numerical algorithms for numerical linear algebra and optimization, so finding the fastest algorithm for matrix multiplication is of major practical relevance.
Funnelsort is a comparison-based sorting algorithm. It is similar to mergesort, but it is a cache-oblivious algorithm, designed for a setting where the number of elements to sort is too large to fit in a cache where operations are done. It was introduced by Matteo Frigo, Charles Leiserson, Harald Prokop, and Sridhar Ramachandran in 1999 in the context of the cache oblivious model.
The cache-oblivious distribution sort is a comparison-based sorting algorithm. It is similar to quicksort, but it is a cache-oblivious algorithm, designed for a setting where the number of elements to sort is too large to fit in a cache where operations are done. In the external memory model, the number of memory transfers it needs to perform a sort of items on a machine with cache of size and cache lines of length is , under the tall cache assumption that . This number of memory transfers has been shown to be asymptotically optimal for comparison sorts. This distribution sort also achieves the asymptotically optimal runtime complexity of .
Communication-avoiding algorithms minimize movement of data within a memory hierarchy for improving its running-time and energy consumption. These minimize the total of two costs : arithmetic and communication. Communication, in this context refers to moving data, either between levels of memory or between multiple processors over a network. It is much more expensive than arithmetic.
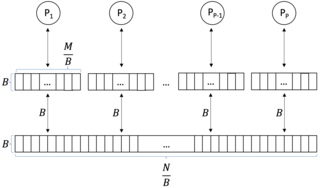
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.