Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).

The Scalable Coherent Interface or Scalable Coherent Interconnect (SCI), is a high-speed interconnect standard for shared memory multiprocessing and message passing. The goal was to scale well, provide system-wide memory coherence and a simple interface; i.e. a standard to replace existing buses in multiprocessor systems with one with no inherent scalability and performance limitations.
The MESI protocol is an invalidate-based cache coherence protocol, and is one of the most common protocols that support write-back caches. It is also known as the Illinois protocol due to its development at the University of Illinois at Urbana-Champaign. Write back caches can save considerable bandwidth generally wasted on a write through cache. There is always a dirty state present in write-back caches that indicates that the data in the cache is different from that in the main memory. The Illinois Protocol requires a cache-to-cache transfer on a miss if the block resides in another cache. This protocol reduces the number of main memory transactions with respect to the MSI protocol. This marks a significant improvement in performance.
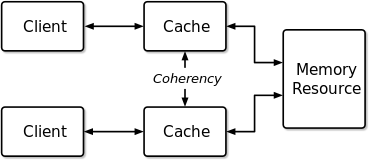
In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable. Consistency models are used in distributed systems like distributed shared memory systems or distributed data stores. Consistency is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
Bus snooping or bus sniffing is a scheme by which a coherency controller (snooper) in a cache monitors or snoops the bus transactions, and its goal is to maintain a cache coherency in distributed shared memory systems. This scheme was introduced by Ravishankar and Goodman in 1983, under the name "write-once" cache coherency. A cache containing a coherency controller (snooper) is called a snoopy cache.
Memory coherence is an issue that affects the design of computer systems in which two or more processors or cores share a common area of memory.
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as a single shared address space. The term "shared" does not mean that there is a single centralized memory, but that the address space is shared—i.e., the same physical address on two processors refers to the same location in memory. Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's private memory.
Release consistency is one of the synchronization-based consistency models used in concurrent programming.
In computing, the MSI protocol - a basic cache-coherence protocol - operates in multiprocessor systems. As with other cache coherency protocols, the letters of the protocol name identify the possible states in which a cache line can be.
The MOSI protocol is an extension of the basic MSI cache coherency protocol. It adds the Owned state, which indicates that the current processor owns this block, and will service requests from other processors for the block.
(For a detailed description see Cache coherency protocols )
In cache coherency protocol literature, Write-Once was the first MESI protocol defined. It has the optimization of executing write-through on the first write and a write-back on all subsequent writes, reducing the overall bus traffic in consecutive writes to the computer memory. It was first described by James R. Goodman in (1983). Cache coherence protocols are an important issue in Symmetric multiprocessing systems, where each CPU maintains a cache of the memory.
The Firefly cache coherence protocol is the schema used in the DEC Firefly multiprocessor workstation, developed by DEC Systems Research Center. This protocol is a 3 State Write Update Cache Coherence Protocol. Unlike the Dragon protocol, the Firefly protocol updates the Main Memory as well as the Local caches on Write Update Bus Transition. Thus the Shared Clean and Shared Modified States present in case of Dragon Protocol, are not distinguished between in case of Firefly Protocol.
The Dragon Protocol is an update based cache coherence protocol used in multi-processor systems. Write propagation is performed by directly updating all the cached values across multiple processors. Update based protocols such as the Dragon protocol perform efficiently when a write to a cache block is followed by several reads made by other processors, since the updated cache block is readily available across caches associated with all the processors.
The MESIF protocol is a cache coherency and memory coherence protocol developed by Intel for cache coherent non-uniform memory architectures. The protocol consists of five states, Modified (M), Exclusive (E), Shared (S), Invalid (I) and Forward (F).

In computer science, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Shared memory is an efficient means of passing data between programs. Depending on context, programs may run on a single processor or on multiple separate processors.
Processor consistency is one of the consistency models used in the domain of concurrent computing.
In computer engineering, directory-based cache coherence is a type of cache coherence mechanism, where directories are used to manage caches in place of bus snooping. Bus snooping methods scale poorly due to the use of broadcasting. These methods can be used to target both performance and scalability of directory systems.
Directory-based coherence is a mechanism to handle cache coherence problem in distributed shared memory (DSM) a.k.a. non-uniform memory access (NUMA). Another popular way is to use a special type of computer bus between all the nodes as a "shared bus". Directory-based coherence uses a special directory to serve instead of the shared bus in the bus-based coherence protocols. Both of these designs use the corresponding medium as a tool to facilitate the communication between different nodes, and to guarantee that the coherence protocol is working properly along all the communicating nodes. In directory based cache coherence, this is done by using this directory to keep track of the status of all cache blocks, the status of each block includes in which cache coherence "state" that block is, and which nodes are sharing that block at that time, which can be used to eliminate the need to broadcast all the signals to all nodes, and only send it to the nodes that are interested in this single block.
Examples of coherency protocols for cache memory are listed here. For simplicity, all "miss" Read and Write status transactions which obviously come from state "I", in the diagrams are not shown. They are shown directly on the new state. Many of the following protocols have only historical value. At the moment the main protocols used are the R-MESI type / MESIF protocols and the HRT-ST-MESI or a subset or an extension of these.