In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the relative order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
In linear algebra, the Strassen algorithm, named after Volker Strassen, is an algorithm for matrix multiplication. It is faster than the standard matrix multiplication algorithm for large matrices, with a better asymptotic complexity, although the naive algorithm is often better for smaller matrices. The Strassen algorithm is slower than the fastest known algorithms for extremely large matrices, but such galactic algorithms are not useful in practice, as they are much slower for matrices of practical size. For small matrices even faster algorithms exist.
In computing, external memory algorithms or out-of-core algorithms are algorithms that are designed to process data that are too large to fit into a computer's main memory at once. Such algorithms must be optimized to efficiently fetch and access data stored in slow bulk memory such as hard drives or tape drives, or when memory is on a computer network. External memory algorithms are analyzed in the external memory model.

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:
Discrepancy of hypergraphs is an area of discrepancy theory.
In computer science, locality-sensitive hashing (LSH) is an algorithmic technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
Because matrix multiplication is such a central operation in many numerical algorithms, much work has been invested in making matrix multiplication algorithms efficient. Applications of matrix multiplication in computational problems are found in many fields including scientific computing and pattern recognition and in seemingly unrelated problems such as counting the paths through a graph. Many different algorithms have been designed for multiplying matrices on different types of hardware, including parallel and distributed systems, where the computational work is spread over multiple processors.
Samplesort is a sorting algorithm that is a divide and conquer algorithm often used in parallel processing systems. Conventional divide and conquer sorting algorithms partitions the array into sub-intervals or buckets. The buckets are then sorted individually and then concatenated together. However, if the array is non-uniformly distributed, the performance of these sorting algorithms can be significantly throttled. Samplesort addresses this issue by selecting a sample of size s from the n-element sequence, and determining the range of the buckets by sorting the sample and choosing p−1 < s elements from the result. These elements then divide the array into p approximately equal-sized buckets. Samplesort is described in the 1970 paper, "Samplesort: A Sampling Approach to Minimal Storage Tree Sorting", by W. D. Frazer and A. C. McKellar.
In computer science, a fractal tree index is a tree data structure that keeps data sorted and allows searches and sequential access in the same time as a B-tree but with insertions and deletions that are asymptotically faster than a B-tree. Like a B-tree, a fractal tree index is a generalization of a binary search tree in that a node can have more than two children. Furthermore, unlike a B-tree, a fractal tree index has buffers at each node, which allow insertions, deletions and other changes to be stored in intermediate locations. The goal of the buffers is to schedule disk writes so that each write performs a large amount of useful work, thereby avoiding the worst-case performance of B-trees, in which each disk write may change a small amount of data on disk. Like a B-tree, fractal tree indexes are optimized for systems that read and write large blocks of data. The fractal tree index has been commercialized in databases by Tokutek. Originally, it was implemented as a cache-oblivious lookahead array, but the current implementation is an extension of the Bε tree. The Bε is related to the Buffered Repository Tree. The Buffered Repository Tree has degree 2, whereas the Bε tree has degree Bε. The fractal tree index has also been used in a prototype filesystem. An open source implementation of the fractal tree index is available, which demonstrates the implementation details outlined below.
In computational geometry, a maximum disjoint set (MDS) is a largest set of non-overlapping geometric shapes selected from a given set of candidate shapes.
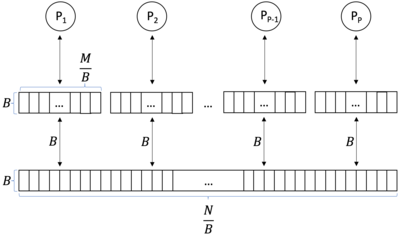
The cache-oblivious distribution sort is a comparison-based sorting algorithm. It is similar to quicksort, but it is a cache-oblivious algorithm, designed for a setting where the number of elements to sort is too large to fit in a cache where operations are done. In the external memory model, the number of memory transfers it needs to perform a sort of items on a machine with cache of size and cache lines of length is , under the tall cache assumption that . This number of memory transfers has been shown to be asymptotically optimal for comparison sorts. This distribution sort also achieves the asymptotically optimal runtime complexity of .
Communication-avoiding algorithms minimize movement of data within a memory hierarchy for improving its running-time and energy consumption. These minimize the total of two costs : arithmetic and communication. Communication, in this context refers to moving data, either between levels of memory or between multiple processors over a network. It is much more expensive than arithmetic.
In computer science, the reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result. Reduction operators are associative and often commutative. The reduction of sets of elements is an integral part of programming models such as Map Reduce, where a reduction operator is applied (mapped) to all elements before they are reduced. Other parallel algorithms use reduction operators as primary operations to solve more complex problems. Many reduction operators can be used for broadcasting to distribute data to all processors.
A central problem in algorithmic graph theory is the shortest path problem. Hereby, the problem of finding the shortest path between every pair of nodes is known as all-pair-shortest-paths (APSP) problem. As sequential algorithms for this problem often yield long runtimes, parallelization has shown to be beneficial in this field. In this article two efficient algorithms solving this problem are introduced.
In graph theory a minimum spanning tree (MST) of a graph with and is a tree subgraph of that contains all of its vertices and is of minimum weight.
External memory graph traversal is a type of graph traversal optimized for accessing externally stored memory.
A central problem in algorithmic graph theory is the shortest path problem. One of the generalizations of the shortest path problem is known as the single-source-shortest-paths (SSSP) problem, which consists of finding the shortest paths from a source vertex to all other vertices in the graph. There are classical sequential algorithms which solve this problem, such as Dijkstra's algorithm. In this article, however, we present two parallel algorithms solving this problem.