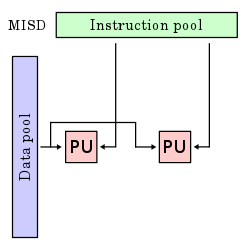
Systolic arrays
Systolic arrays (< wavefront processors), first described by H. T. Kung and Charles E. Leiserson are an example of MISD architecture. In a typical systolic array, parallel input data flows through a network of hard-wired processor nodes, resembling the human brain which combine, process, merge or sort the input data into a derived result.
Systolic arrays are often hard-wired for a specific operation, such as "multiply and accumulate", to perform massively parallel integration, convolution, correlation, matrix multiplication or data sorting tasks. A systolic array typically consists of a large monolithic network of primitive computing nodes, which can be hardwired or software-configured for a specific application. The nodes are usually fixed and identical, while the interconnect is programmable. More general wavefront processors, by contrast, employ sophisticated and individually programmable nodes which may or may not be monolithic, depending on the array size and design parameters. Because the wave-like propagation of data through a systolic array resembles the pulse of the human circulatory system, the name systolic was coined from medical terminology.
A significant benefit of systolic arrays is that all operand data and partial results are contained within (passing through) the processor array. There is no need to access external buses, main memory, or internal caches during each operation, as with standard sequential machines. The sequential limits on parallel performance dictated by Amdahl's law also do not apply in the same way because data dependencies are implicitly handled by the programmable node interconnect.
Therefore, systolic arrays are extremely good at artificial intelligence, image processing, pattern recognition, computer vision, and other tasks that animal brains do exceptionally well. Wavefront processors, in general, can also be very good at machine learning by implementing self-configuring neural nets in hardware.
Classification controversy
While systolic arrays are officially classified as MISD, their classification is somewhat problematic. Because the input is typically a vector of independent values, the systolic array is not SISD. Since these input values are merged and combined into the result(s) and do not maintain their independence as they would in a SIMD vector processing unit, the array cannot be classified as such. Consequently, the array cannot be classified as a MIMD either, since MIMD can be viewed as a mere collection of smaller SISD and SIMD machines.
Finally, because the data swarm is transformed as it passes through the array from node to node, the multiple nodes are not operating on the same data, which makes the MISD classification a misnomer. The other reason why a systolic array should not qualify as a MISD is the same as the one which disqualifies it from the SISD category: The input data is typically a vector, not a single data value, although one could argue that any given input vector is a single dataset.
The above notwithstanding, systolic arrays are often offered as a classic example of MISD architecture in textbooks on parallel computing and in the engineering class. If the array is viewed from the outside as atomic it should perhaps be classified as SFMuDMeR = single function, multiple data, merged result(s). [3] [4] [5] [6]
This page is based on this
Wikipedia article Text is available under the
CC BY-SA 4.0 license; additional terms may apply.
Images, videos and audio are available under their respective licenses.