
A central processing unit (CPU), also called a central processor, main processor, or just processor, is the most important processor in a given computer. Its electronic circuitry executes instructions of a computer program, such as arithmetic, logic, controlling, and input/output (I/O) operations. This role contrasts with that of external components, such as main memory and I/O circuitry, and specialized coprocessors such as graphics processing units (GPUs).
In computer science, an instruction set architecture (ISA) is an abstract model that generally defines how software controls the CPU in a computer or a family of computers. A device or program that executes instructions described by that ISA, such as a central processing unit (CPU), is called an implementation of that ISA.

The Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data. It is often contrasted with the von Neumann architecture, where program instructions and data share the same memory and pathways. This architecture is often used in real-time processing or low-power applications.

The program counter (PC), commonly called the instruction pointer (IP) in Intel x86 and Itanium microprocessors, and sometimes called the instruction address register (IAR), the instruction counter, or just part of the instruction sequencer, is a processor register that indicates where a computer is in its program sequence.

AVR is a family of microcontrollers developed since 1996 by Atmel, acquired by Microchip Technology in 2016. These are modified Harvard architecture 8-bit RISC single-chip microcontrollers. AVR was one of the first microcontroller families to use on-chip flash memory for program storage, as opposed to one-time programmable ROM, EPROM, or EEPROM used by other microcontrollers at the time.
In computer science, self-modifying code is code that alters its own instructions while it is executing – usually to reduce the instruction path length and improve performance or simply to reduce otherwise repetitively similar code, thus simplifying maintenance. The term is usually only applied to code where the self-modification is intentional, not in situations where code accidentally modifies itself due to an error such as a buffer overflow.
In computer engineering, instruction pipelining is a technique for implementing instruction-level parallelism within a single processor. Pipelining attempts to keep every part of the processor busy with some instruction by dividing incoming instructions into a series of sequential steps performed by different processor units with different parts of instructions processed in parallel.
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
Fetching the instruction opcodes from program memory well in advance is known as prefetching and it is served by using a prefetch input queue (PIQ). The pre-fetched instructions are stored in a queue. The fetching of opcodes well in advance, prior to their need for execution, increases the overall efficiency of the processor boosting its speed. The processor no longer has to wait for the memory access operations for the subsequent instruction opcode to complete. This architecture was prominently used in the Intel 8086 microprocessor.
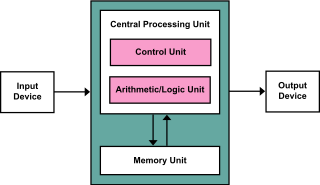
The von Neumann architecture—also known as the von Neumann model or Princeton architecture—is a computer architecture based on a 1945 description by John von Neumann, and by others, in the First Draft of a Report on the EDVAC. The document describes a design architecture for an electronic digital computer with these components:
A processor register is a quickly accessible location available to a computer's processor. Registers usually consist of a small amount of fast storage, although some registers have specific hardware functions, and may be read-only or write-only. In computer architecture, registers are typically addressed by mechanisms other than main memory, but may in some cases be assigned a memory address e.g. DEC PDP-10, ICT 1900.

The instruction cycle is the cycle that the central processing unit (CPU) follows from boot-up until the computer has shut down in order to process instructions. It is composed of three main stages: the fetch stage, the decode stage, and the execute stage.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.
A von Neumann language in computing is a programming language that is a high-level abstract isomorphic copy of a von Neumann architecture. As of 2009, most current programming languages fit into this description, likely as a consequence of the extensive domination of the von Neumann computer architecture during the past 50 years.

In electronics, computer science and computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as μarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
The Atmel AVR instruction set is the machine language for the Atmel AVR, a modified Harvard architecture 8-bit RISC single chip microcontroller which was developed by Atmel in 1996. The AVR was one of the first microcontroller families to use on-chip flash memory for program storage.

Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.
ARM9 is a group of 32-bit RISC ARM processor cores licensed by ARM Holdings for microcontroller use. The ARM9 core family consists of ARM9TDMI, ARM940T, ARM9E-S, ARM966E-S, ARM920T, ARM922T, ARM946E-S, ARM9EJ-S, ARM926EJ-S, ARM968E-S, ARM996HS. ARM9 cores were released from 1998 to 2006 and they are no longer recommended for new IC designs; recommended alternatives include ARM Cortex-A, ARM Cortex-M, and ARM Cortex-R cores.
Memory architecture describes the methods used to implement electronic computer data storage in a manner that is a combination of the fastest, most reliable, most durable, and least expensive way to store and retrieve information. Depending on the specific application, a compromise of one of these requirements may be necessary in order to improve another requirement. Memory architecture also explains how binary digits are converted into electric signals and then stored in the memory cells. And also the structure of a memory cell.
This glossary of computer hardware terms is a list of definitions of terms and concepts related to computer hardware, i.e. the physical and structural components of computers, architectural issues, and peripheral devices.