Related Research Articles
Very long instruction word (VLIW) refers to instruction set architectures designed to exploit instruction level parallelism (ILP). Whereas conventional central processing units mostly allow programs to specify instructions to execute in sequence only, a VLIW processor allows programs to explicitly specify instructions to execute in parallel. This design is intended to allow higher performance without the complexity inherent in some other designs.
In computer science, predication is an architectural feature that provides an alternative to conditional transfer of control, as implemented by conditional branch machine instructions. Predication works by having conditional (predicated) non-branch instructions associated with a predicate, a Boolean value used by the instruction to control whether the instruction is allowed to modify the architectural state or not. If the predicate specified in the instruction is true, the instruction modifies the architectural state; otherwise, the architectural state is unchanged. For example, a predicated move instruction will only modify the destination if the predicate is true. Thus, instead of using a conditional branch to select an instruction or a sequence of instructions to execute based on the predicate that controls whether the branch occurs, the instructions to be executed are associated with that predicate, so that they will be executed, or not executed, based on whether that predicate is true or false.

Instruction-level parallelism (ILP) is the parallel or simultaneous execution of a sequence of instructions in a computer program. More specifically ILP refers to the average number of instructions run per step of this parallel execution.
Speculative execution is an optimization technique where a computer system performs some task that may not be needed. Work is done before it is known whether it is actually needed, so as to prevent a delay that would have to be incurred by doing the work after it is known that it is needed. If it turns out the work was not needed after all, most changes made by the work are reverted and the results are ignored.
A re-order buffer (ROB) is a hardware unit used in an extension to the Tomasulo algorithm to support out-of-order and speculative instruction execution. The extension forces instructions to be committed in-order.
Tomasulo's algorithm is a computer architecture hardware algorithm for dynamic scheduling of instructions that allows out-of-order execution and enables more efficient use of multiple execution units. It was developed by Robert Tomasulo at IBM in 1967 and was first implemented in the IBM System/360 Model 91’s floating point unit.
In the domain of central processing unit (CPU) design, hazards are problems with the instruction pipeline in CPU microarchitectures when the next instruction cannot execute in the following clock cycle, and can potentially lead to incorrect computation results. Three common types of hazards are data hazards, structural hazards, and control hazards.
In the history of computer hardware, some early reduced instruction set computer central processing units used a very similar architectural solution, now called a classic RISC pipeline. Those CPUs were: MIPS, SPARC, Motorola 88000, and later the notional CPU DLX invented for education.
In computer architecture, register renaming is a technique that abstracts logical registers from physical registers. Every logical register has a set of physical registers associated with it. When a machine language instruction refers to a particular logical register, the processor transposes this name to one specific physical register on the fly. The physical registers are opaque and cannot be referenced directly but only via the canonical names.
Explicitly parallel instruction computing (EPIC) is a term coined in 1997 by the HP–Intel alliance to describe a computing paradigm that researchers had been investigating since the early 1980s. This paradigm is also called Independence architectures. It was the basis for Intel and HP development of the Intel Itanium architecture, and HP later asserted that "EPIC" was merely an old term for the Itanium architecture. EPIC permits microprocessors to execute software instructions in parallel by using the compiler, rather than complex on-die circuitry, to control parallel instruction execution. This was intended to allow simple performance scaling without resorting to higher clock frequencies.
In computer engineering, out-of-order execution is a paradigm used in most high-performance central processing units to make use of instruction cycles that would otherwise be wasted. In this paradigm, a processor executes instructions in an order governed by the availability of input data and execution units, rather than by their original order in a program. In doing so, the processor can avoid being idle while waiting for the preceding instruction to complete and can, in the meantime, process the next instructions that are able to run immediately and independently.

In computer engineering, microarchitecture, also called computer organization and sometimes abbreviated as µarch or uarch, is the way a given instruction set architecture (ISA) is implemented in a particular processor. A given ISA may be implemented with different microarchitectures; implementations may vary due to different goals of a given design or due to shifts in technology.
Automatic parallelization, also auto parallelization, or autoparallelization refers to converting sequential code into multi-threaded and/or vectorized code in order to use multiple processors simultaneously in a shared-memory multiprocessor (SMP) machine. Fully automatic parallelization of sequential programs is a challenge because it requires complex program analysis and the best approach may depend upon parameter values that are not known at compilation time.
Memory disambiguation is a set of techniques employed by high-performance out-of-order execution microprocessors that execute memory access instructions out of program order. The mechanisms for performing memory disambiguation, implemented using digital logic inside the microprocessor core, detect true dependencies between memory operations at execution time and allow the processor to recover when a dependence has been violated. They also eliminate spurious memory dependencies and allow for greater instruction-level parallelism by allowing safe out-of-order execution of loads and stores.
Runahead is a technique that allows a microprocessor to pre-process instructions during cache miss cycles instead of stalling. The pre-processed instructions are used to generate instruction and data stream prefetches by detecting cache misses before they would otherwise occur by using the idle execution resources to calculate instruction and data stream fetch addresses using the available information that is independent of the cache miss.
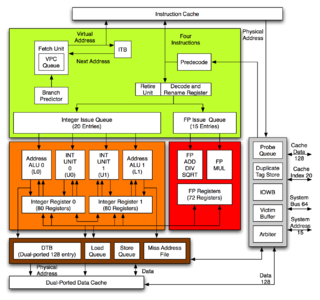
The Alpha 21264 is a Digital Equipment Corporation RISC microprocessor launched on 19 October 1998. The 21264 implemented the Alpha instruction set architecture (ISA).
The Power Processing Element (PPE) comprises a Power Processing Unit (PPU) and a 512 KB L2 cache. In most instances the PPU is used in a PPE. The PPU is a 64-bit dual-threaded in-order PowerPC 2.02 microprocessor core designed by IBM for use primarily in the game consoles PlayStation 3 and Xbox 360, but has also found applications in high performance computing in supercomputers such as the record setting IBM Roadrunner.
Processor Consistency is one of the consistency models used in the domain of concurrent computing.
Latency oriented processor architecture is the microarchitecture of a microprocessor designed to serve a serial computing thread with a low latency. This is typical of most central processing units (CPU) being developed since the 1970s. These architectures, in general, aim to execute as many instructions as possible belonging to a single serial thread, in a given window of time; however, the time to execute a single instruction completely from fetch to retire stages may vary from a few cycles to even a few hundred cycles in some cases. Latency oriented processor architectures are the opposite of throughput-oriented processors which concern themselves more with the total throughput of the system, rather than the service latencies for all individual threads that they work on.

In computer architecture, a trace cache or execution trace cache is a specialized instruction cache which stores the dynamic stream of instructions known as trace. It helps in increasing the instruction fetch bandwidth and decreasing power consumption by storing traces of instructions that have already been fetched and decoded. A trace processor is an architecture designed around the trace cache and processes the instructions at trace level granularity. The formal mathematical theory of traces is described by trace monoids.
References
- 1 2 3 4 Moshovos, A.; Sohi, G. S. (1997). "Streamlining Inter-Operation Memory Communication via Data Dependence Prediction". Proceedings of 30th Annual International Symposium on Microarchitecture. MICRO'97. pp. 235–245. doi:10.1109/MICRO.1997.645814.
- 1 2 3 Moshovos, Andreas; Breach, Scott E.; Vijaykumar, T. N.; Sohi, Gurindar S. (1997). "Dynamic Speculation and Synchronization of Data Dependences". Proceedings of the 24th annual international symposium on Computer architecture. ISCA'97. pp. 181–193. doi:10.1145/264107.264189. Also as technical report, Computer Sciences Department, University of Wisconsin–Madison, March 1996.
- 1 2 Memory Dependence Prediction, Moshovos, Ph.D. Thesis, Computer Sciences Department, University of Wisconsin–Madison, Dec. 1998.
- ↑ Chrysos, G. Z.; Emer, J. S. (1998). "Memory Dependence Prediction Using Store Sets". Proceedings 25th Annual International Symposium on Computer Architecture. ISCA'98. pp. 142–153. doi:10.1109/ISCA.1998.694770.
- ↑ Apparatus to dynamically control the out-of-order execution of load-store instructions in a processor capable of dispatching, issuing and executing multiple instructions in a single processor cycle, Hesson, LeBlanc and Ciavaglia, IBM, US Patent 5,615,350, March 1997.