
A central processing unit (CPU)—also called a central processor or main processor—is the most important processor in a given computer. Its electronic circuitry executes instructions of a computer program, such as arithmetic, logic, controlling, and input/output (I/O) operations. This role contrasts with that of external components, such as main memory and I/O circuitry, and specialized coprocessors such as graphics processing units (GPUs).

In computing, a process is the instance of a computer program that is being executed by one or many threads. There are many different process models, some of which are light weight, but almost all processes are rooted in an operating system (OS) process which comprises the program code, assigned system resources, physical and logical access permissions, and data structures to initiate, control and coordinate execution activity. Depending on the OS, a process may be made up of multiple threads of execution that execute instructions concurrently.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. In many cases, a thread is a component of a process.

Symmetric multiprocessing or shared-memory multiprocessing (SMP) involves a multiprocessor computer hardware and software architecture where two or more identical processors are connected to a single, shared main memory, have full access to all input and output devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
Very long instruction word (VLIW) refers to instruction set architectures that are designed to exploit instruction level parallelism (ILP). A VLIW processor allows programs to explicitly specify instructions to execute in parallel, whereas conventional central processing units (CPUs) mostly allow programs to specify instructions to execute in sequence only. VLIW is intended to allow higher performance without the complexity inherent in some other designs.
Multiprocessing is the use of two or more central processing units (CPUs) within a single computer system. The term also refers to the ability of a system to support more than one processor or the ability to allocate tasks between them. There are many variations on this basic theme, and the definition of multiprocessing can vary with context, mostly as a function of how CPUs are defined.

Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.

Instruction-level parallelism (ILP) is the parallel or simultaneous execution of a sequence of instructions in a computer program. More specifically ILP refers to the average number of instructions run per step of this parallel execution.
Simultaneous multithreading (SMT) is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better use the resources provided by modern processor architectures.
In computing, single program, multiple data (SPMD) is a term that has been used to refer to computational models for exploiting parallelism where-by multiple processors cooperate in the execution of a program in order to obtain results faster.

Hardware acceleration is the use of computer hardware designed to perform specific functions more efficiently when compared to software running on a general-purpose central processing unit (CPU). Any transformation of data that can be calculated in software running on a generic CPU can also be calculated in custom-made hardware, or in some mix of both.

Binary Modular Dataflow Machine (BMDFM) is a software package that enables running an application in parallel on shared memory symmetric multiprocessing (SMP) computers using the multiple processors to speed up the execution of single applications. BMDFM automatically identifies and exploits parallelism due to the static and mainly dynamic scheduling of the dataflow instruction sequences derived from the formerly sequential program.
In computer science, stream processing is a programming paradigm which views streams, or sequences of events in time, as the central input and output objects of computation. Stream processing encompasses dataflow programming, reactive programming, and distributed data processing. Stream processing systems aim to expose parallel processing for data streams and rely on streaming algorithms for efficient implementation. The software stack for these systems includes components such as programming models and query languages, for expressing computation; stream management systems, for distribution and scheduling; and hardware components for acceleration including floating-point units, graphics processing units, and field-programmable gate arrays.

A multi-core processor is a microprocessor on a single integrated circuit with two or more separate processing units, called cores, each of which reads and executes program instructions. The instructions are ordinary CPU instructions but the single processor can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single integrated circuit die or onto multiple dies in a single chip package. The microprocessors currently used in almost all personal computers are multi-core.
In computer architecture, multithreading is the ability of a central processing unit (CPU) to provide multiple threads of execution concurrently, supported by the operating system. This approach differs from multiprocessing. In a multithreaded application, the threads share the resources of a single or multiple cores, which include the computing units, the CPU caches, and the translation lookaside buffer (TLB).
LynxSecure is a least privilege real-time separation kernel hypervisor from Lynx Software Technologies designed for safety and security critical applications found in military, avionic, industrial, and automotive markets.
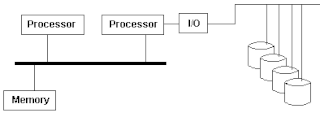
An asymmetric multiprocessing system is a multiprocessor computer system where not all of the multiple interconnected central processing units (CPUs) are treated equally. For example, a system might allow only one CPU to execute operating system code or might allow only one CPU to perform I/O operations. Other AMP systems might allow any CPU to execute operating system code and perform I/O operations, so that they were symmetric with regard to processor roles, but attached some or all peripherals to particular CPUs, so that they were asymmetric with respect to the peripheral attachment.
Heterogeneous System Architecture (HSA) is a cross-vendor set of specifications that allow for the integration of central processing units and graphics processors on the same bus, with shared memory and tasks. The HSA is being developed by the HSA Foundation, which includes AMD and ARM. The platform's stated aim is to reduce communication latency between CPUs, GPUs and other compute devices, and make these various devices more compatible from a programmer's perspective, relieving the programmer of the task of planning the moving of data between devices' disjoint memories.
Heterogeneous computing refers to systems that use more than one kind of processor or core. These systems gain performance or energy efficiency not just by adding the same type of processors, but by adding dissimilar coprocessors, usually incorporating specialized processing capabilities to handle particular tasks.
A domain-specific architecture (DSA) is a programmable computer architecture specifically tailored to operate very efficiently within the confines of a given application domain. The term is often used in contrast to general-purpose architectures, such as CPUs, that are designed to operate on any computer program.