In computer science, an array is a data structure consisting of a collection of elements, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains: data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that access time is linear. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.

In computer science, a trie, also called digital tree or prefix tree, is a type of k-ary search tree, a tree data structure used for locating specific keys from within a set. These keys are most often strings, with links between nodes defined not by the entire key, but by individual characters. In order to access a key, the trie is traversed depth-first, following the links between nodes, which represent each character in the key.

The Scalable Coherent Interface or Scalable Coherent Interconnect (SCI), is a high-speed interconnect standard for shared memory multiprocessing and message passing. The goal was to scale well, provide system-wide memory coherence and a simple interface; i.e. a standard to replace existing buses in multiprocessor systems with one with no inherent scalability and performance limitations.

In computer architecture, cache coherence is the uniformity of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with incoherent data, which is particularly the case with CPUs in a multiprocessing system.
The MESI protocol is an Invalidate-based cache coherence protocol, and is one of the most common protocols that support write-back caches. It is also known as the Illinois protocol. Write back caches can save a lot of bandwidth that is generally wasted on a write through cache. There is always a dirty state present in write back caches that indicates that the data in the cache is different from that in main memory. The Illinois Protocol requires a cache to cache transfer on a miss if the block resides in another cache. This protocol reduces the number of main memory transactions with respect to the MSI protocol. This marks a significant improvement in performance.
Bus snooping or bus sniffing is a scheme by which a coherency controller (snooper) in a cache monitors or snoops the bus transactions, and its goal is to maintain a cache coherency in distributed shared memory systems. A cache containing a coherency controller (snooper) is called a snoopy cache. This scheme was introduced by Ravishankar and Goodman in 1983.
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as a single shared address space. The term "shared" does not mean that there is a single centralized memory, but that the address space is shared—i.e., the same physical address on two processors refers to the same location in memory. Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's private memory.
In computer science, dynamic dispatch is the process of selecting which implementation of a polymorphic operation to call at run time. It is commonly employed in, and considered a prime characteristic of, object-oriented programming (OOP) languages and systems.
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost to access data from the main memory. A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels, with different instruction-specific and data-specific caches at level 1. The cache memory is typically implemented with static random-access memory (SRAM), in modern CPUs by far the largest part of them by chip area, but SRAM is not always used for all levels, or even any level, sometimes some latter or all levels are implemented with eDRAM.

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
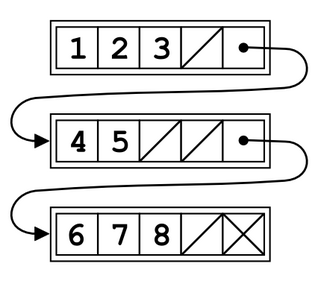
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can dramatically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references. It is related to the B-tree.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.

In computer science a T-tree is a type of binary tree data structure that is used by main-memory databases, such as Datablitz, eXtremeDB, MySQL Cluster, Oracle TimesTen and MobileLite.
Lustre is a type of parallel distributed file system, generally used for large-scale cluster computing. The name Lustre is a portmanteau word derived from Linux and cluster. Lustre file system software is available under the GNU General Public License and provides high performance file systems for computer clusters ranging in size from small workgroup clusters to large-scale, multi-site systems. Since June 2005, Lustre has consistently been used by at least half of the top ten, and more than 60 of the top 100 fastest supercomputers in the world, including the world's No. 1 ranked TOP500 supercomputer in November 2022, Frontier, as well as previous top supercomputers such as Fugaku, Titan and Sequoia.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
In computer science, persistent memory is any method or apparatus for efficiently storing data structures such that they can continue to be accessed using memory instructions or memory APIs even after the end of the process that created or last modified them.
A CPU cache is a piece of hardware that reduces access time to data in memory by keeping some part of the frequently used data of the main memory in a 'cache' of smaller and faster memory.
Directory-based coherence is a mechanism to handle Cache coherence problem in Distributed shared memory (DSM) a.k.a. Non-Uniform Memory Access (NUMA). Another popular way is to use a special type of computer bus between all the nodes as a "shared bus". Directory-based coherence uses a special directory to serve instead of the shared bus in the bus-based coherence protocols. Both of these designs use the corresponding medium as a tool to facilitate the communication between different nodes, and to guarantee that the coherence protocol is working properly along all the communicating nodes. In directory based cache coherence, this is done by using this directory to keep track of the status of all cache blocks, the status of each block includes in which cache coherence "state" that block is, and which nodes are sharing that block at that time, which can be used to eliminate the need to broadcast all the signals to all nodes, and only send it to the nodes that are interested in this single block.

