
A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable length output. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.

In computing, a hash table, also known as a hash map, is a data structure that implements an associative array, also called a dictionary, which is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
In computing, Chord is a protocol and algorithm for a peer-to-peer distributed hash table. A distributed hash table stores key-value pairs by assigning keys to different computers ; a node will store the values for all the keys for which it is responsible. Chord specifies how keys are assigned to nodes, and how a node can discover the value for a given key by first locating the node responsible for that key.
In a computer operating system that uses paging for virtual memory management, page replacement algorithms decide which memory pages to page out, sometimes called swap out, or write to disk, when a page of memory needs to be allocated. Page replacement happens when a requested page is not in memory and a free page cannot be used to satisfy the allocation, either because there are none, or because the number of free pages is lower than some threshold.
A space–time trade-off, also known as time–memory trade-off or the algorithmic space-time continuum in computer science is a case where an algorithm or program trades increased space usage with decreased time. Here, space refers to the data storage consumed in performing a given task, and time refers to the time consumed in performing a given task.
The sort-merge join is a join algorithm and is used in the implementation of a relational database management system.
In cryptography, Optimal Asymmetric Encryption Padding (OAEP) is a padding scheme often used together with RSA encryption. OAEP was introduced by Bellare and Rogaway, and subsequently standardized in PKCS#1 v2 and RFC 2437.
In computing, a cache-oblivious algorithm is an algorithm designed to take advantage of a processor cache without having the size of the cache as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally. Thus, a cache-oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy with different levels of cache having different sizes. Cache-oblivious algorithms are contrasted with explicit loop tiling, which explicitly breaks a problem into blocks that are optimally sized for a given cache.

Linear probing is a scheme in computer programming for resolving collisions in hash tables, data structures for maintaining a collection of key–value pairs and looking up the value associated with a given key. It was invented in 1954 by Gene Amdahl, Elaine M. McGraw, and Arthur Samuel and first analyzed in 1963 by Donald Knuth.
The hash join is an example of a join algorithm and is used in the implementation of a relational database management system. All variants of hash join algorithms involve building hash tables from the tuples of one or both of the joined relations, and subsequently probing those tables so that only tuples with the same hash code need to be compared for equality in equijoins.
In computer science, consistent hashing is a special kind of hashing technique such that when a hash table is resized, only keys need to be remapped on average where is the number of keys and is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.

Cuckoo hashing is a scheme in computer programming for resolving hash collisions of values of hash functions in a table, with worst-case constant lookup time. The name derives from the behavior of some species of cuckoo, where the cuckoo chick pushes the other eggs or young out of the nest when it hatches in a variation of the behavior referred to as brood parasitism; analogously, inserting a new key into a cuckoo hashing table may push an older key to a different location in the table.
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:
A nested loop join is a naive algorithm that joins two relations by using two nested loops. Join operations are important for database management.
In computer science, locality-sensitive hashing (LSH) is a fuzzy hashing technique that hashes similar input items into the same "buckets" with high probability. Since similar items end up in the same buckets, this technique can be used for data clustering and nearest neighbor search. It differs from conventional hashing techniques in that hash collisions are maximized, not minimized. Alternatively, the technique can be seen as a way to reduce the dimensionality of high-dimensional data; high-dimensional input items can be reduced to low-dimensional versions while preserving relative distances between items.
In a SQL database query, a correlated subquery is a subquery that uses values from the outer query. Because the subquery may be evaluated once for each row processed by the outer query, it can be slow.
In computer science, streaming algorithms are algorithms for processing data streams in which the input is presented as a sequence of items and can be examined in only a few passes, typically just one. These algorithms are designed to operate with limited memory, generally logarithmic in the size of the stream and/or in the maximum value in the stream, and may also have limited processing time per item.
In computer science, tabulation hashing is a method for constructing universal families of hash functions by combining table lookup with exclusive or operations. It was first studied in the form of Zobrist hashing for computer games; later work by Carter and Wegman extended this method to arbitrary fixed-length keys. Generalizations of tabulation hashing have also been developed that can handle variable-length keys such as text strings.
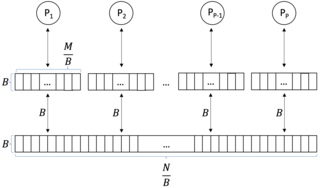
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine. It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.
Approximate Membership Query Filter (AMQ-Filter) is a group of space-efficient probabilistic data structures that supports approximate membership queries. An approximate membership query answers if an element is in a set or not with a false positive rate of .







