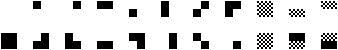Box-drawing characters, also known as line-drawing characters, are a form of semigraphics widely used in text user interfaces to draw various geometric frames and boxes. These characters are characterized by being designed to be connected horizontally and/or vertically with adjacent characters, which requires proper alignment. Box-drawing characters therefore typically only work well with monospaced fonts.
Some recent embedded systems also use proprietary character sets, usually extensions to ISO 8859 character sets, which include box-drawing characters or other special symbols.
Other types of box-drawing characters are block elements, shade characters, and terminal graphic characters; these can be used for filling regions of the screen and portraying drop shadows.
Unicode
Box Drawing
Unicode includes 128 such characters in the Box Drawing block.[1] In many Unicode fonts, only the subset that is also available in the IBM PC character set (see below) will exist, due to it being defined as part of the WGL4 character set.
In version 13.0, Unicode was extended with another block containing many graphics characters, Symbols for Legacy Computing, which includes a few box-drawing characters and other symbols used by obsolete operating systems (mostly from the 1980s). Few fonts support these characters (one is Noto Sans Symbols 2), but the table of symbols is provided here:
The image below is provided as a quick reference for these symbols on systems that are unable to display them directly:
Symbols for Legacy Computing Supplement
In version 16.0 (September 2024), Unicode was extended with another block containing many graphics characters, Symbols for Legacy Computing Supplement, which includes a few box-drawing characters and other symbols used by obsolete operating systems (mostly from the 1970s and 1980s).
Various different platforms defined their own unique set of box-drawing characters.
DOS
The hardware code page of the original IBM PC supplied the following box-drawing characters, in what DOS now calls code page 437. This subset of the Unicode box-drawing characters is thus included in WGL4 and is far more popular and likely to be rendered correctly:
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
B
░
▒
▓
│
┤
╡
╢
╖
╕
╣
║
╗
╝
╜
╛
┐
C
└
┴
┬
├
─
┼
╞
╟
╚
╔
╩
╦
╠
═
╬
╧
D
╨
╤
╥
╙
╘
╒
╓
╫
╪
┘
┌
█
▄
▌
▐
▀
The integral halves are also box drawing as they are used alongside 0xB3:
4
5
F
⌠
⌡
Their number is further limited to 28 on those code pages that replace the 18 characters that combine single and double lines, the left and right half blocks, as well as integral halves with other, usually alphabetic, characters (such as code page 850):
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
B
░
▒
▓
│
┤
╣
║
╗
╝
┐
C
└
┴
┬
├
─
┼
╚
╔
╩
╦
╠
═
╬
D
┘
┌
█
▄
▀
Note: The non-double characters are the thin (light) characters (U+2500, U+2502), not the bold (heavy) characters (U+2501, U+2503).
On many Unix systems and early dial-up bulletin board systems the only common standard for box-drawing characters was the VT100 alternate character set (see also: DEC Special Graphics). The escape sequenceEsc(0 switched the codes for lower-case ASCII letters to draw this set, and the sequence Esc(B switched back:
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
6
┘
┐
┌
└
┼
7
─
├
┤
┴
┬
│
On some terminals, these characters are not available at all, and the complexity of the escape sequences discouraged their use, so often only ASCII characters that approximate box-drawing characters are used, such as -(hyphen-minus), |(vertical bar), _(underscore), =(equal sign) and +(plus sign) in a kind of ASCII art fashion.
Modern Unix terminal emulators use Unicode and thus have access to the line-drawing characters listed above.
Teletext
The World System Teletext (WST) uses pixel-drawing characters for some graphics. A character cell is divided in 2×3 regions, and 26=64 code positions are allocated for all possible combinations of pixels.[4] These characters were added to the Unicode standard in Version 13.[5]
Historical
Many microcomputers of the 1970s and 1980s had their own proprietary character sets, which also included box-drawing characters. Many of these were added to Unicode as Symbols for Legacy Computing.
Commodore machines, such as the Commodore PET and the Commodore 64, included a set of text semigraphics with block elements and dithering patterns in the PETSCII character set.
PET 2001 keyboard layout, illustrating PETSCII graphics characters
The Sinclair ZX80, ZX81, and ZX Spectrum included a set of text semigraphics with quadrant-based block elements. The ZX80 and ZX81 also included a set of text semigraphics with dithering patterns.
BBC and Acorn
The BBC Micro could utilize the Teletext 7-bit character set, which had 128 box-drawing characters, whose code points were shared with the regular alphanumeric and punctuation characters. Control characters were used to switch between regular text and box drawing.[6]
However, DOS line- and box-drawing characters are not ordered in any programmatic manner, so calculating a particular character shape needs to use a look-up table.
Examples
Sample diagrams made out of the standard box-drawing characters, using a monospaced font:
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.