A block diagram of the CMAC system for a single joint. The vector S is presented as input to all joints. Each joint separately computes an S -> A* mapping and a joint actuator signal pi. The adjustable weights for all joints may reside in the same physical memory.
The cerebellar model arithmetic computer (CMAC) is a type of neural network based on a model of the mammalian cerebellum. It is also known as the cerebellar model articulation controller. It is a type of associativememory.[2]
The CMAC was first proposed as a function modeler for robotic controllers by James Albus in 1975[1] (hence the name), but has been extensively used in reinforcement learning and also as for automated classification in the machine learning community. The CMAC is an extension of the perceptron model. It computes a function for input dimensions. The input space is divided up into hyper-rectangles, each of which is associated with a memory cell. The contents of the memory cells are the weights, which are adjusted during training. Usually, more than one quantisation of input space is used, so that any point in input space is associated with a number of hyper-rectangles, and therefore with a number of memory cells. The output of a CMAC is the algebraic sum of the weights in all the memory cells activated by the input point.
A change of value of the input point results in a change in the set of activated hyper-rectangles, and therefore a change in the set of memory cells participating in the CMAC output. The CMAC output is therefore stored in a distributed fashion, such that the output corresponding to any point in input space is derived from the value stored in a number of memory cells (hence the name associative memory). This provides generalisation.
Building blocks
CMAC, represented as a 2D space
In the adjacent image, there are two inputs to the CMAC, represented as a 2D space. Two quantising functions have been used to divide this space with two overlapping grids (one shown in heavier lines). A single input is shown near the middle, and this has activated two memory cells, corresponding to the shaded area. If another point occurs close to the one shown, it will share some of the same memory cells, providing generalisation.
The CMAC is trained by presenting pairs of input points and output values, and adjusting the weights in the activated cells by a proportion of the error observed at the output. This simple training algorithm has a proof of convergence.[3]
It is normal to add a kernel function to the hyper-rectangle, so that points falling towards the edge of a hyper-rectangle have a smaller activation than those falling near the centre.[4]
One of the major problems cited in practical use of CMAC is the memory size required, which is directly related to the number of cells used. This is usually ameliorated by using a hash function, and only providing memory storage for the actual cells that are activated by inputs.
One-step convergent algorithm
Initially least mean square (LMS) method is employed to update the weights of CMAC. The convergence of using LMS for training CMAC is sensitive to the learning rate and could lead to divergence. In 2004,[5] a recursive least squares (RLS) algorithm was introduced to train CMAC online. It does not need to tune a learning rate. Its convergence has been proved theoretically and can be guaranteed to converge in one step. The computational complexity of this RLS algorithm is O(N3).
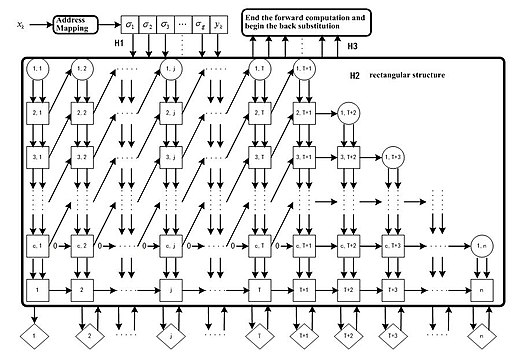
Parallel pipeline structure of CMAC neural network Left panel: real functions; right panel: CMAC approximation with derivatives
Hardware implementation infrastructure
Based on QR decomposition, an algorithm (QRLS) has been further simplified to have an O(N) complexity. Consequently, this reduces memory usage and time cost significantly. A parallel pipeline array structure on implementing this algorithm has been introduced.[6]
Overall by utilizing QRLS algorithm, the CMAC neural network convergence can be guaranteed, and the weights of the nodes can be updated using one step of training. Its parallel pipeline array structure offers its great potential to be implemented in hardware for large-scale industry usage.
Continuous CMAC
Since the rectangular shape of CMAC receptive field functions produce discontinuous staircase function approximation, by integrating CMAC with B-splines functions, continuous CMAC offers the capability of obtaining any order of derivatives of the approximate functions.
Deep CMAC
In recent years, numerous studies have confirmed that by stacking several shallow structures into a single deep structure, the overall system could achieve better data representation, and, thus, more effectively deal with nonlinear and high complexity tasks. In 2018,[7] a deep CMAC (DCMAC) framework was proposed and a backpropagation algorithm was derived to estimate the DCMAC parameters. Experimental results of an adaptive noise cancellation task showed that the proposed DCMAC can achieve better noise cancellation performance when compared with that from the conventional single-layer CMAC.
Summary
Scalability
Straightforward to extend to millions of neurons or further
Convergence
The training can always converge in one step
Function derivatives
Straightforward to obtain by employing B-splines interpolation
↑ Wong, Y.; Sideris, A. (January 1992). "Learning convergence in the cerebellar model articulation controller". IEEE Transactions on Neural Networks. 3 (1): 115–121. doi:10.1109/72.105424. PMID18276412.
↑ P.C.E. An, W.T. Miller, and P.C. Parks, Design Improvements in Associative Memories for Cerebellar Model Articulation Controllers, Proc. ICANN, pp. 1207–10, 1991.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.