
Independence is a fundamental notion in probability theory, as in statistics and the theory of stochastic processes. Two events are independent, statistically independent, or stochastically independent if, informally speaking, the occurrence of one does not affect the probability of occurrence of the other or, equivalently, does not affect the odds. Similarly, two random variables are independent if the realization of one does not affect the probability distribution of the other.

A Markov chain or Markov process is a stochastic process describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. Informally, this may be thought of as, "What happens next depends only on the state of affairs now." A countably infinite sequence, in which the chain moves state at discrete time steps, gives a discrete-time Markov chain (DTMC). A continuous-time process is called a continuous-time Markov chain (CTMC). Markov processes are named in honor of the Russian mathematician Andrey Markov.
A hidden Markov model (HMM) is a Markov model in which the observations are dependent on a latent Markov process. An HMM requires that there be an observable process whose outcomes depend on the outcomes of in a known way. Since cannot be observed directly, the goal is to learn about state of by observing By definition of being a Markov model, an HMM has an additional requirement that the outcome of at time must be "influenced" exclusively by the outcome of at and that the outcomes of and at must be conditionally independent of at given at time Estimation of the parameters in an HMM can be performed using maximum likelihood. For linear chain HMMs, the Baum–Welch algorithm can be used to estimate the parameters.
A Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). While it is one of several forms of causal notation, causal networks are special cases of Bayesian networks. Bayesian networks are ideal for taking an event that occurred and predicting the likelihood that any one of several possible known causes was the contributing factor. For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases.

In probability theory and statistics, the term Markov property refers to the memoryless property of a stochastic process, which means that its future evolution is independent of its history. It is named after the Russian mathematician Andrey Markov. The term strong Markov property is similar to the Markov property, except that the meaning of "present" is defined in terms of a random variable known as a stopping time.

In probability theory and information theory, the mutual information (MI) of two random variables is a measure of the mutual dependence between the two variables. More specifically, it quantifies the "amount of information" obtained about one random variable by observing the other random variable. The concept of mutual information is intimately linked to that of entropy of a random variable, a fundamental notion in information theory that quantifies the expected "amount of information" held in a random variable.
In probability theory, the conditional expectation, conditional expected value, or conditional mean of a random variable is its expected value evaluated with respect to the conditional probability distribution. If the random variable can take on only a finite number of values, the "conditions" are that the variable can only take on a subset of those values. More formally, in the case when the random variable is defined over a discrete probability space, the "conditions" are a partition of this probability space.
In statistics, Gibbs sampling or a Gibbs sampler is a Markov chain Monte Carlo (MCMC) algorithm for sampling from a specified multivariate probability distribution when direct sampling from the joint distribution is difficult, but sampling from the conditional distribution is more practical. This sequence can be used to approximate the joint distribution ; to approximate the marginal distribution of one of the variables, or some subset of the variables ; or to compute an integral. Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
A continuous-time Markov chain (CTMC) is a continuous stochastic process in which, for each state, the process will change state according to an exponential random variable and then move to a different state as specified by the probabilities of a stochastic matrix. An equivalent formulation describes the process as changing state according to the least value of a set of exponential random variables, one for each possible state it can move to, with the parameters determined by the current state.
In the domain of physics and probability, a Markov random field (MRF), Markov network or undirected graphical model is a set of random variables having a Markov property described by an undirected graph. In other words, a random field is said to be a Markov random field if it satisfies Markov properties. The concept originates from the Sherrington–Kirkpatrick model.
In probability, a discrete-time Markov chain (DTMC) is a sequence of random variables, known as a stochastic process, in which the value of the next variable depends only on the value of the current variable, and not any variables in the past. For instance, a machine may have two states, A and E. When it is in state A, there is a 40% chance of it moving to state E and a 60% chance of it remaining in state A. When it is in state E, there is a 70% chance of it moving to A and a 30% chance of it staying in E. The sequence of states of the machine is a Markov chain. If we denote the chain by then is the state which the machine starts in and is the random variable describing its state after 10 transitions. The process continues forever, indexed by the natural numbers.
In information theory, Fano's inequality relates the average information lost in a noisy channel to the probability of the categorization error. It was derived by Robert Fano in the early 1950s while teaching a Ph.D. seminar in information theory at MIT, and later recorded in his 1961 textbook.
In the mathematical theory of stochastic processes, variable-order Markov (VOM) models are an important class of models that extend the well known Markov chain models. In contrast to the Markov chain models, where each random variable in a sequence with a Markov property depends on a fixed number of random variables, in VOM models this number of conditioning random variables may vary based on the specific observed realization.
In the mathematical theory of probability, the entropy rate or source information rate is a function assigning an entropy to a stochastic process.
Inequalities are very important in the study of information theory. There are a number of different contexts in which these inequalities appear.
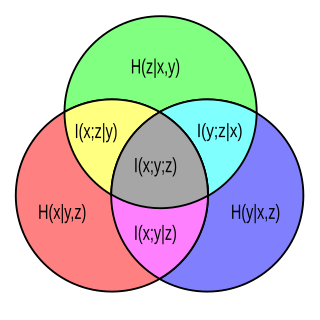
In probability theory, particularly information theory, the conditional mutual information is, in its most basic form, the expected value of the mutual information of two random variables given the value of a third.
In the mathematical study of stochastic processes, a Harris chain is a Markov chain where the chain returns to a particular part of the state space an unbounded number of times. Harris chains are regenerative processes and are named after Theodore Harris. The theory of Harris chains and Harris recurrence is useful for treating Markov chains on general state spaces.
In mathematics, specifically in the theory of Markovian stochastic processes in probability theory, the Chapman–Kolmogorov equation (CKE) is an identity relating the joint probability distributions of different sets of coordinates on a stochastic process. The equation was derived independently by both the British mathematician Sydney Chapman and the Russian mathematician Andrey Kolmogorov. The CKE is prominently used in recent Variational Bayesian methods.
Stochastic chains with memory of variable length are a family of stochastic chains of finite order in a finite alphabet, such as, for every time pass, only one finite suffix of the past, called context, is necessary to predict the next symbol. These models were introduced in the information theory literature by Jorma Rissanen in 1983, as a universal tool to data compression, but recently have been used to model data in different areas such as biology, linguistics and music.
Dependency networks (DNs) are graphical models, similar to Markov networks, wherein each vertex (node) corresponds to a random variable and each edge captures dependencies among variables. Unlike Bayesian networks, DNs may contain cycles. Each node is associated to a conditional probability table, which determines the realization of the random variable given its parents.












