Divide-and-conquer eigenvalue algorithms are a class of eigenvalue algorithms for Hermitian or realsymmetric matrices that have recently (circa 1990s) become competitive in terms of stability and efficiency with more traditional algorithms such as the QR algorithm. The basic concept behind these algorithms is the divide-and-conquer approach from computer science. An eigenvalue problem is divided into two problems of roughly half the size, each of these are solved recursively, and the eigenvalues of the original problem are computed from the results of these smaller problems.
This article covers the basic idea of the algorithm as originally proposed by Cuppen in 1981, which is not numerically stable without additional refinements.
Background
As with most eigenvalue algorithms for Hermitian matrices, divide-and-conquer begins with a reduction to tridiagonal form. For an matrix, the standard method for this, via Householder reflections, takes floating point operations, or if eigenvectors are needed as well. There are other algorithms, such as the Arnoldi iteration, which may do better for certain classes of matrices; we will not consider this further here.
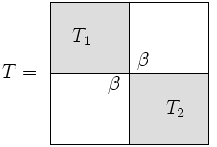
In certain cases, it is possible to deflate an eigenvalue problem into smaller problems. Consider a block diagonal matrix
The eigenvalues and eigenvectors of are simply those of and , and it will almost always be faster to solve these two smaller problems than to solve the original problem all at once. This technique can be used to improve the efficiency of many eigenvalue algorithms, but it has special significance to divide-and-conquer.
For the rest of this article, we will assume the input to the divide-and-conquer algorithm is an real symmetric tridiagonal matrix . The algorithm can be modified for Hermitian matrices.
Divide
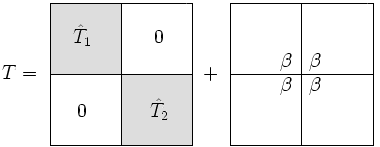
The divide part of the divide-and-conquer algorithm comes from the realization that a tridiagonal matrix is "almost" block diagonal.
The size of submatrix we will call , and then is . is almost block diagonal regardless of how is chosen. For efficiency we typically choose .
We write as a block diagonal matrix, plus a rank-1 correction:
The only difference between and is that the lower right entry in has been replaced with and similarly, in the top left entry has been replaced with .
The remainder of the divide step is to solve for the eigenvalues (and if desired the eigenvectors) of and , that is to find the diagonalizations and . This can be accomplished with recursive calls to the divide-and-conquer algorithm, although practical implementations often switch to the implicitly shifted QR algorithm for small enough submatrices.[1]
Conquer
The conquer part of the algorithm is the unintuitive part. Given the diagonalizations of the submatrices, calculated above, how do we find the diagonalization of the original matrix?
First, define , where is the last row of and is the first row of . It is now elementary to show that
The remaining task has been reduced to finding the eigenvalues of a diagonal matrix plus a rank-one correction. Before showing how to do this, let us simplify the notation. We are looking for the eigenvalues of the matrix , where is diagonal with distinct entries and is any vector with nonzero entries. In this case .
The case of a zero entry is simple, since if wi is zero, (,di) is an eigenpair ( is in the standard basis) of since .
If is an eigenvalue, we have:
where is the corresponding eigenvector. Now
Keep in mind that is a nonzero scalar. Neither nor are zero. If were to be zero, would be an eigenvector of by . If that were the case, would contain only one nonzero position since is distinct diagonal and thus the inner product can not be zero after all. Therefore, we have:
or written as a scalar equation,
This equation is known as the secular equation. The problem has therefore been reduced to finding the roots of the rational function defined by the left-hand side of this equation.
Solving the nonlinear secular equation can be done using an iterative technique, such as the Newton–Raphson method. However, each root can be found in O(1) iterations, each of which requires flops (for an -degree rational function), making the cost of the iterative part of this algorithm . The fast multipole method has also been employed to solve the secular equation in operations.[2][1]
In the notation of the Master theorem, and thus . Clearly, , so we have
Above, we pointed out that reducing a Hermitian matrix to tridiagonal form takes flops. This dwarfs the running time of the divide-and-conquer part, and at this point it is not clear what advantage the divide-and-conquer algorithm offers over the QR algorithm (which also takes flops for tridiagonal matrices).
The advantage of divide-and-conquer comes when eigenvectors are needed as well. If this is the case, reduction to tridiagonal form takes , but the second part of the algorithm takes as well. For the QR algorithm with a reasonable target precision, this is , whereas for divide-and-conquer it is . The reason for this improvement is that in divide-and-conquer, the part of the algorithm (multiplying matrices) is separate from the iteration, whereas in QR, this must occur in every iterative step. Adding the flops for the reduction, the total improvement is from to flops.
Practical use of the divide-and-conquer algorithm has shown that in most realistic eigenvalue problems, the algorithm actually does better than this. The reason is that very often the matrices and the vectors tend to be numerically sparse, meaning that they have many entries with values smaller than the floating point precision, allowing for numerical deflation, i.e. breaking the problem into uncoupled subproblems.
Variants and implementation
The algorithm presented here is the simplest version. In many practical implementations, more complicated rank-1 corrections are used to guarantee stability; some variants even use rank-2 corrections.[citation needed]
There exist specialized root-finding techniques for rational functions that may do better than the Newton-Raphson method in terms of both performance and stability. These can be used to improve the iterative part of the divide-and-conquer algorithm.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.