In coding theory, an erasure code is a forward error correction (FEC) code under the assumption of bit erasures (rather than bit errors), which transforms a message of k symbols into a longer message (code word) with n symbols such that the original message can be recovered from a subset of the n symbols. The fraction r=k/n is called the code rate. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception efficiency. The recovery algorithm expects that it is known which of the n symbols are lost.
As of 2023, modern data storage systems can be designed to tolerate the complete failure of a few disks without data loss, using one of 3 approaches:[2][3][4]
Replication
RAID
Erasure Coding
While technically RAID can be seen as a kind of erasure code,[5] "RAID" is generally applied to an array attached to a single host computer (which is a single point of failure), while "erasure coding" generally implies multiple hosts,[3] sometimes called a Redundant Array of Inexpensive Servers (RAIS). The erasure code allows operations to continue when any one of those hosts stops.[4][6]
Compared to block-level RAID systems, object storage erasure coding has some significant differences that make it more resilient.[7][8][9][10][11]
Optimal erasure codes have the property that any k out of the n code word symbols are sufficient to recover the original message (i.e., they have optimal reception efficiency). Optimal erasure codes are maximum distance separable codes (MDS codes).
Parity check is the special case where n=k+1. From a set of k values , a checksum is computed and appended to the k source values:
The set of k+1 values is now consistent with regard to the checksum. If one of these values, , is erased, it can be easily recovered by summing the remaining variables:
RAID 5 is a widely used application of the parity check erasure code using XOR.[1]
Polynomial oversampling
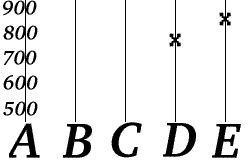
Example: Err-mail (k=2)
In the simple case where k=2, redundancy symbols may be created by sampling different points along the line between the two original symbols. This is pictured with a simple example, called err-mail:
Alice wants to send her telephone number (555629) to Bob using err-mail. Err-mail works just like e-mail, except
About half of all the mail gets lost.
Messages longer than 5 characters are illegal.
It is very expensive (similar to air-mail).
Instead of asking Bob to acknowledge the messages she sends, Alice devises the following scheme.
She breaks her telephone number up into two parts a = 555, b = 629, and sends 2 messages – "A=555" and "B=629" – to Bob.
She constructs a linear function, , in this case , such that and .
She computes the values f(3), f(4), and f(5), and then transmits three redundant messages: "C=703", "D=777" and "E=851".
Bob knows that the form of f(k) is , where a and b are the two parts of the telephone number. Now suppose Bob receives "D=777" and "E=851".
Bob can reconstruct Alice's phone number by computing the values of a and b from the values (f(4) and f(5)) he has received. Bob can perform this procedure using any two err-mails, so the erasure code in this example has a rate of 40%.
Note that Alice cannot encode her telephone number in just one err-mail, because it contains six characters, and that the maximum length of one err-mail message is five characters. If she sent her phone number in pieces, asking Bob to acknowledge receipt of each piece, at least four messages would have to be sent anyway (two from Alice, and two acknowledgments from Bob). So the erasure code in this example, which requires five messages, is quite economical.
This example is a little bit contrived. For truly generic erasure codes that work over any data set, we would need something other than the f(i) given.
First we choose a finite field F with order of at least n, but usually a power of 2. The sender numbers the data symbols from 0 to k−1 and sends them. He then constructs a (Lagrange) polynomialp(x) of order k such that p(i) is equal to data symbol i. He then sends p(k), ..., p(n−1). The receiver can now also use polynomial interpolation to recover the lost packets, provided he receives k symbols successfully. If the order of F is less than 2b, where b is the number of bits in a symbol, then multiple polynomials can be used.
The sender can construct symbols k to n−1 'on the fly', i.e., distribute the workload evenly between transmission of the symbols. If the receiver wants to do his calculations 'on the fly', he can construct a new polynomial q, such that q(i) = p(i) if symbol i < k was received successfully and q(i)=0 when symbol i<k was not received. Now let r(i) = p(i)−q(i). Firstly we know that r(i)=0 if symbol i < k has been received successfully. Secondly, if symbol i≥k has been received successfully, then r(i)=p(i)−q(i) can be calculated. So we have enough data points to construct r and evaluate it to find the lost packets. So both the sender and the receiver require O(n (n−k)) operations and only O(n−k) space for operating 'on the fly'.
Most practical erasure codes are systematic codes—each one of the original k symbols can be found copied, unencoded, as one of the n message symbols.[12] (Erasure codes that support secret sharing never use a systematic code).
Near-optimal erasure codes
Near-optimal erasure codes require (1+ε)k symbols to recover the message (where ε>0). Reducing ε can be done at the cost of CPU time. Near-optimal erasure codes trade correction capabilities for computational complexity: practical algorithms can encode and decode with linear time complexity.
Fountain codes (also known as rateless erasure codes) are notable examples of near-optimal erasure codes. They can transform a k symbol message into a practically infinite encoded form, i.e., they can generate an arbitrary amount of redundancy symbols that can all be used for error correction. Receivers can start decoding after they have received slightly more than k encoded symbols.
Regenerating codes address the issue of rebuilding (also called repairing) lost encoded fragments from existing encoded fragments. This issue occurs in distributed storage systems where communication to maintain encoded redundancy is a problem.[12]
Applications of erasure coding in storage systems
Erasure coding is now standard practice for reliable data storage.[13][14][15] In particular, various implementations of Reed-Solomon erasure coding are used by Apache Hadoop, the RAID-6 built into Linux, Microsoft Azure, Facebook cold storage, and Backblaze Vaults.[15][12]
The classical way to recover from failures in storage systems was to use replication. However, replication incurs significant overhead in terms of wasted bytes. Therefore, increasingly large storage systems, such as those used in data centers use erasure-coded storage. The most common form of erasure coding used in storage systems is Reed-Solomon (RS) code, an advanced mathematics formula used to enable regeneration of missing data from pieces of known data, called parity blocks. In a (k,r) RS code, a given set of '' data blocks, called "chunks", are encoded into (k+r) chunks. The total set of chunks comprises a stripe. The coding is done such that as long as at least k out of (k+r) chunks are available, one can recover the entire data. This means a (k,mr') RS-encoded storage can tolerate up to m failures. (This is different from the standard RS(n,k) notation, with n=k+r.)
RS(10,4)
Example: In RS(10,4) code, which is used in Facebook for their HDFS (now part of Apache Hadoop), 10 MB of user data is divided into ten 1MB blocks. Then, four additional 1 MB parity blocks are created to provide redundancy. This can tolerate up to 4 concurrent failures. The storage overhead here is 14/10 = 1.4×.[16]
In the case of a fully replicated system, the 10 MB of user data will have to be replicated 4 times to tolerate up to 4 concurrent failures. The storage overhead in that case will be 50/10=5 times.
This gives an idea of the lower storage overhead of erasure-coded storage compared to full replication and thus the attraction in today's storage systems.
The Hitchhiker scheme can be combined with RS-coding to reduce the amount of computation and data-transfer required for data block reconstruction. It is also implemented as an HDFS codec, though a policy will need to be manually defined for it to be used.[12]
Hot data
Initially, erasure codes were used to reduce the cost of storing "cold" (rarely-accessed) data efficiently; but erasure codes can also be used to improve performance serving "hot" (more-frequently-accessed) data compared to simpler redundancy schemes (mirroring).[12]
The classic example of erasing coding improving performance is RAID 5, which provides the same single-drive failure protection while requiring fewer hard drives compared to RAID 1. The extra hard drives may then be used to store more data and make use of the improved read/write-speed multiplier on RAID 5. This also applies to RAID 6 (double-redundancy: one parity and one erasure code), assuming processing power is sufficient.[1] Generalized RAID can work with any number of redundancy drives. There are two notations for generalized RAID: RAID7.x refers to a system with x redundancy drives, allowing recovery when as many as x drives fail.[17] Alternatively, RAID N+M refers to N regular data drives with M redundancy drives, being able to recover all the data when any M drives fail.[1]
A more advanced example is EC-Cache, a cluster cache, i.e. a cache distributed among several nodes. Such systems can suffer from load imbalance when one node happens to host more popular items and a common method to address this issue is selective replication, i.e. create more replicas for more popular objects. However, this method is limited by the available amount of memory. By individually dividing every object into k splits and r redundancy units, perfect load balancing can instead be achieved with minimal waste of memory.[12]
Examples
Here are some examples of implementations of the various codes:
XOR Parity, adding one erasable symbol. Used in RAID4, RAID5.
Reed–Solomon codes. It is optimal when used in erasure mode, allowing k erasures for k added symbols. When used in error-correction mode, it is also optimal, allowing floor(k/2) errors.
Parchive file format 1.0, 2.0, and (open) 3.0 uses RS. 3.0 also supports other linear codes.
RAID6 uses a variety of optimal erasure codes, but RS is a common choice.
Tahoe-LAFS includes zfec, an implementation of Classic RS.
↑ Dimitri Pertin, Alexandre van Kempen, Benoît Parrein, Nicolas Normand. "Comparison of RAID-6 Erasure Codes". The third Sino-French Workshop on Information and Communication Technologies, SIFWICT 2015, Jun 2015, Nantes, France. ffhal-01162047f
↑ Leventhal, Adam (December 2009). "Triple-Parity RAID and Beyond: As hard-drive capacities continue to outpace their throughput, the time has come for a new level of RAID". ACM Queue. 7 (11): 30–39. doi:10.1145/1661785.1670144.
Feclib is a near optimal extension to Luigi Rizzo's work that uses band matrices. Many parameters can be set, like the size of the width of the band and size of the finite field. It also successfully exploits the large register size of modern CPUs. How it compares to the near optimal codes mentioned above is unknown.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.