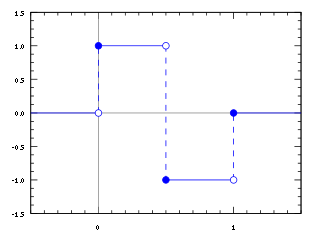
In mathematics, the Haar wavelet is a sequence of rescaled "square-shaped" functions which together form a wavelet family or basis. Wavelet analysis is similar to Fourier analysis in that it allows a target function over an interval to be represented in terms of an orthonormal basis. The Haar sequence is now recognised as the first known wavelet basis and is extensively used as a teaching example.
In machine learning (ML), boosting is an ensemble metaheuristic for primarily reducing bias. It can also improve the stability and accuracy of ML classification and regression algorithms. Hence, it is prevalent in supervised learning for converting weak learners to strong learners.
Image analysis or imagery analysis is the extraction of meaningful information from images; mainly from digital images by means of digital image processing techniques. Image analysis tasks can be as simple as reading bar coded tags or as sophisticated as identifying a person from their face.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.

Content-based image retrieval, also known as query by image content and content-based visual information retrieval (CBVIR), is the application of computer vision techniques to the image retrieval problem, that is, the problem of searching for digital images in large databases. Content-based image retrieval is opposed to traditional concept-based approaches.
Template matching is a technique in digital image processing for finding small parts of an image which match a template image. It can be used for quality control in manufacturing, navigation of mobile robots, or edge detection in images.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.

In mathematics, a wavelet series is a representation of a square-integrable function by a certain orthonormal series generated by a wavelet. This article provides a formal, mathematical definition of an orthonormal wavelet and of the integral wavelet transform.
A co-occurrence matrix or co-occurrence distribution is a matrix that is defined over an image to be the distribution of co-occurring pixel values at a given offset. It is used as an approach to texture analysis with various applications especially in medical image analysis.
In computer vision, speeded up robust features (SURF) is a local feature detector and descriptor, with patented applications. It can be used for tasks such as object recognition, image registration, classification, or 3D reconstruction. It is partly inspired by the scale-invariant feature transform (SIFT) descriptor. The standard version of SURF is several times faster than SIFT and claimed by its authors to be more robust against different image transformations than SIFT.
The histogram of oriented gradients (HOG) is a feature descriptor used in computer vision and image processing for the purpose of object detection. The technique counts occurrences of gradient orientation in localized portions of an image. This method is similar to that of edge orientation histograms, scale-invariant feature transform descriptors, and shape contexts, but differs in that it is computed on a dense grid of uniformly spaced cells and uses overlapping local contrast normalization for improved accuracy.
Object recognition – technology in the field of computer vision for finding and identifying objects in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes and scales or even when they are translated or rotated. Objects can even be recognized when they are partially obstructed from view. This task is still a challenge for computer vision systems. Many approaches to the task have been implemented over multiple decades.
The Viola–Jones object detection framework is a machine learning object detection framework proposed in 2001 by Paul Viola and Michael Jones. It was motivated primarily by the problem of face detection, although it can be adapted to the detection of other object classes.
One-shot learning is an object categorization problem, found mostly in computer vision. Whereas most machine learning-based object categorization algorithms require training on hundreds or thousands of examples, one-shot learning aims to classify objects from one, or only a few, examples. The term few-shot learning is also used for these problems, especially when more than one example is needed.

Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.

A summed-area table is a data structure and algorithm for quickly and efficiently generating the sum of values in a rectangular subset of a grid. In the image processing domain, it is also known as an integral image. It was introduced to computer graphics in 1984 by Frank Crow for use with mipmaps. In computer vision it was popularized by Lewis and then given the name "integral image" and prominently used within the Viola–Jones object detection framework in 2001. Historically, this principle is very well known in the study of multi-dimensional probability distribution functions, namely in computing 2D probabilities from the respective cumulative distribution functions.
Cascading is a particular case of ensemble learning based on the concatenation of several classifiers, using all information collected from the output from a given classifier as additional information for the next classifier in the cascade. Unlike voting or stacking ensembles, which are multiexpert systems, cascading is a multistage one.
In statistics, a ranklet is an orientation-selective non-parametric feature which is based on the computation of Mann–Whitney–Wilcoxon (MWW) rank-sum test statistics. Ranklets achieve similar response to Haar wavelets as they share the same pattern of orientation-selectivity, multi-scale nature and a suitable notion of completeness. There were invented by Fabrizio Smeralhi in 2002.
In computer vision, rigid motion segmentation is the process of separating regions, features, or trajectories from a video sequence into coherent subsets of space and time. These subsets correspond to independent rigidly moving objects in the scene. The goal of this segmentation is to differentiate and extract the meaningful rigid motion from the background and analyze it. Image segmentation techniques labels the pixels to be a part of pixels with certain characteristics at a particular time. Here, the pixels are segmented depending on its relative movement over a period of time i.e. the time of the video sequence.
Integral Channel Features (ICF), also known as ChnFtrs, is a method for object detection in computer vision. It uses integral images to extract features such as local sums, histograms and Haar-like features from multiple registered image channels. This method was highly exploited by Dollár et al. in their work for pedestrian detection, that was first described at the BMVC in 2009.





