Related Research Articles
Routing is the process of selecting a path for traffic in a network or between or across multiple networks. Broadly, routing is performed in many types of networks, including circuit-switched networks, such as the public switched telephone network (PSTN), and computer networks, such as the Internet.

In computer science, a tree is a widely used abstract data type that represents a hierarchical tree structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent. These constraints mean there are no cycles or "loops", and also that each child can be treated like the root node of its own subtree, making recursion a useful technique for tree traversal. In contrast to linear data structures, many trees cannot be represented by relationships between neighboring nodes in a single straight line.

A minimum spanning tree (MST) or minimum weight spanning tree is a subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight. That is, it is a spanning tree whose sum of edge weights is as small as possible. More generally, any edge-weighted undirected graph has a minimum spanning forest, which is a union of the minimum spanning trees for its connected components.

In graph theory, the shortest path problem is the problem of finding a path between two vertices in a graph such that the sum of the weights of its constituent edges is minimized.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.

Breadth-first search (BFS) is an algorithm for searching a tree data structure for a node that satisfies a given property. It starts at the tree root and explores all nodes at the present depth prior to moving on to the nodes at the next depth level. Extra memory, usually a queue, is needed to keep track of the child nodes that were encountered but not yet explored.
Link-state routing protocols are one of the two main classes of routing protocols used in packet switching networks for computer communications, the others being distance-vector routing protocols. Examples of link-state routing protocols include Open Shortest Path First (OSPF) and Intermediate System to Intermediate System (IS-IS).

The Bellman–Ford algorithm is an algorithm that computes shortest paths from a single source vertex to all of the other vertices in a weighted digraph. It is slower than Dijkstra's algorithm for the same problem, but more versatile, as it is capable of handling graphs in which some of the edge weights are negative numbers. The algorithm was first proposed by Alfonso Shimbel, but is instead named after Richard Bellman and Lester Ford Jr., who published it in 1958 and 1956, respectively. Edward F. Moore also published a variation of the algorithm in 1959, and for this reason it is also sometimes called the Bellman–Ford–Moore algorithm.
In mathematics, computer science and especially graph theory, a distance matrix is a square matrix containing the distances, taken pairwise, between the elements of a set. Depending upon the application involved, the distance being used to define this matrix may or may not be a metric. If there are N elements, this matrix will have size N×N. In graph-theoretic applications, the elements are more often referred to as points, nodes or vertices.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge (u,v) from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications, especially in ranking problems such as feedback arc set. Topological sorting is possible even when the DAG has disconnected components.
Johnson's algorithm is a way to find the shortest paths between all pairs of vertices in an edge-weighted directed graph. It allows some of the edge weights to be negative numbers, but no negative-weight cycles may exist. It works by using the Bellman–Ford algorithm to compute a transformation of the input graph that removes all negative weights, allowing Dijkstra's algorithm to be used on the transformed graph. It is named after Donald B. Johnson, who first published the technique in 1977.
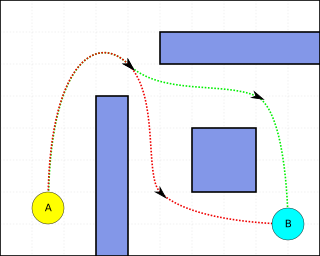
Pathfinding or pathing is the plotting, by a computer application, of the shortest route between two points. It is a more practical variant on solving mazes. This field of research is based heavily on Dijkstra's algorithm for finding the shortest path on a weighted graph.

A method for pruning dense networks to highlight key links
In graph theory, the planar separator theorem is a form of isoperimetric inequality for planar graphs, that states that any planar graph can be split into smaller pieces by removing a small number of vertices. Specifically, the removal of vertices from an n-vertex graph can partition the graph into disjoint subgraphs each of which has at most vertices.
In computer science, the method of contraction hierarchies is a speed-up technique for finding the shortest-path in a graph. The most intuitive applications are car-navigation systems: a user wants to drive from to using the quickest possible route. The metric optimized here is the travel time. Intersections are represented by vertices, the road sections connecting them by edges. The edge weights represent the time it takes to drive along this segment of the road. A path from to is a sequence of edges ; the shortest path is the one with the minimal sum of edge weights among all possible paths. The shortest path in a graph can be computed using Dijkstra's algorithm but, given that road networks consist of tens of millions of vertices, this is impractical. Contraction hierarchies is a speed-up method optimized to exploit properties of graphs representing road networks. The speed-up is achieved by creating shortcuts in a preprocessing phase which are then used during a shortest-path query to skip over "unimportant" vertices. This is based on the observation that road networks are highly hierarchical. Some intersections, for example highway junctions, are "more important" and higher up in the hierarchy than for example a junction leading into a dead end. Shortcuts can be used to save the precomputed distance between two important junctions such that the algorithm doesn't have to consider the full path between these junctions at query time. Contraction hierarchies do not know about which roads humans consider "important", but they are provided with the graph as input and are able to assign importance to vertices using heuristics.

In graph algorithms, the widest path problem is the problem of finding a path between two designated vertices in a weighted graph, maximizing the weight of the minimum-weight edge in the path. The widest path problem is also known as the maximum capacity path problem. It is possible to adapt most shortest path algorithms to compute widest paths, by modifying them to use the bottleneck distance instead of path length. However, in many cases even faster algorithms are possible.
The k shortest path routing problem is a generalization of the shortest path routing problem in a given network. It asks not only about a shortest path but also about next k−1 shortest paths. A variation of the problem is the loopless k shortest paths.
In applied mathematics, transit node routing can be used to speed up shortest-path routing by pre-computing connections between common access nodes to a sub-network relevant to long-distance travel.
References
- ↑ Ittai Abraham, Daniel Delling, Andrew V. Goldberg, Renato F. Werneck, « A Hub-Based Labeling Algorithm for Shortest Paths on Road Networks », Microsoft Research Silicon Valley, 1065 La Avenida, Mountain View, CA 94043, USA, 2010.