In linguistics, Immediate Constituent Analysis (ICA) is a syntactic theory which focuses on the hierarchical structure of sentences by isolating and identifying the constituents. While the idea of breaking down sentences into smaller components can be traced back to early psychological and linguistic theories, ICA as a formal method was developed in the early 20th century. It was influenced by Wilhelm Wundt's psychological theories of sentence structure but was later refined and formalized within the framework of structural linguistics by Leonard Bloomfield. The method gained traction in the distributionalist tradition through the work of Zellig Harris and Charles F. Hockett, who expanded and applied it to sentence analysis. Additionally, ICA was further explored within the context of glossematics by Knud Togeby. These contributions helped ICA become a central tool in syntactic analysis, focusing on the hierarchical relationships between sentence constituents.
In its simplest form, ICA proposes that sentences can be divided into smaller, meaningful units, known as immediate constituents, which are further broken down until the atomic units are uncovered, like individual words. These immediate constituents are typically arranged in a binary branching structure, forming a hierarchical organization of the sentence. The process of ICA can vary based on the underlying syntactic framework being employed. In phrase structure grammars (or constituency grammars), the analysis is based on the idea that the fundamental units of syntax are phrases, and these phrases combine in a hierarchical way to form sentences. In contrast, dependency grammars focus on the relationships between individual words, treating words as nodes that are linked by dependency relations rather than phrasal constituents.
History and Development
Immediate Constituent Analysis (ICA) has played a crucial role in the evolution of syntactic theory, shaping our understanding of sentence structure from its early structuralist roots to contemporary linguistic applications. Emerging in the early 20th century, ICA was developed as a method for breaking down sentences into their smallest meaningful components, influencing key linguistic theories like generative grammar and distributionalism. Although no longer at the forefront of modern syntactic theory, ICA continues to be a valuable tool in both theoretical linguistics and practical applications, such as language teaching and computational syntax.
Origin of Structuralism (late 19th and early 20th century)
The work of early structuralist linguists, particularly in the early 20th century, resulted in the development of structural linguistics and subsequently the differentiation of the smallest units of meaning. Ferdinand de Saussure, a Swiss linguist who contributed groundwork to structural linguistics, which later contributed to the developments in syntactic analysis, even though his work focused more on the structural relationship between elements of a language rather than formal syntactic structures (Jensen 2002, pg. 24).
However, ICA as a formal method began to emerge in the United States in the 1930s, largely as a part of American Structuralism. Linguist Leonard Bloomfield, dubbed the father of distributionalism, introduced the distributional analysis method, which focused on providing a structure for syntax, which later influenced ICA's development. Wilhelm Wundt, a German psychologist, had earlier proposed a similar method of dividing sentences into components for psychological analysis, but it was Leonard Bloomfield, known as the father of distributionalism, who formally introduced distributional analysis as a linguistic methodology. Bloomfield’s work on syntactic structures laid the foundation for the ICA approach by emphasizing the identification and classification of linguistic elements in a sentence, which could then be analyzed for their distributional properties.
Early ICA: from Distributionalism to Generative Grammar (mid 20th century)
The method of Immediate Constituent Analysis is most closely associated with the work of Zellig Harris. Harris expanded on Bloomfield's distributional analysis by providing a more formal approach to syntactic structure, specifically in English sentence analysis. In the 1940s and 1950s, Harris introduced the concept of immediate constituents as the parts of a sentence that can be directly combined to form larger units, such as noun phrases (NPs) and verb phrases (VPs) (Harris 1951, pg. 52).
Harris's ICA method involved continuously dividing a sentence into two immediate constituents, which can then be further subdivided until reaching the smallest meaningful units. Harris's work was foundational in the development of syntactic theory, and his ICA approach set the stage for later advancements in generative grammar (Harris 1955, pg. 363).
Charles F. Hockett, another key figure in structural linguistics, also contributed to the development of ICA. He built upon Harris’s work, incorporating the idea of constituent structure and the distributional analysis of sentence components. Hockett’s contributions focused on the role of syntax in understanding language’s formal structure and its relationship to meaning.
In the 1960s, Noam Chomsky introduced generative grammar, which significantly expanded on the structuralist approaches like ICA. While Chomsky’s theories were more abstract and rule-based, ICA’s emphasis on constituent structure remained influential. Chomsky’s Transformational-Generative Grammar theorized that deep structures (abstract syntactic representations) could be transformed into surface structures (the actual sentences) using specific transformational rules. Though ICA was not directly incorporated into Chomsky's generative grammar, its focus on constituent analysis influenced Chomsky’s syntactic theory (Chomsky 1957, pg. 93).
Chomsky introduced more formalized syntactic structures, including phrase structure rules and X-bar theory, which were designed to explain the hierarchical structure of sentences in a more formal and rule-based manner. Even though ICA itself was not central to Chomsky’s theories, the core idea of breaking down sentences into hierarchical structures remained.
In the mid-20th century, ICA gained additional refinement through the work of Knud Togeby, who integrated structuralist principles into his own approach to sentence analysis. Togeby, working within the framework of glossematics, a European theory of structural linguistics, developed a more formalized version of ICA. His approach emphasized the importance of breaking down sentences into immediate constituents to reveal their hierarchical structure, thus contributing to the ongoing evolution of ICA.
Formalization (late 20th century)
As generative grammar evolved, linguists began to formalize structural analysis further, leading to the development of more sophisticated models like X-bar theory, binding theory, and later minimalist syntax. While ICA was criticized for being too simplistic in these later theoretical frameworks, its basic principles of constituent structure remained an important influence on syntactic theory (Chomsky 1981, pg. 96).
In addition, ICA found new relevance in the field of computational linguistics, particularly in the development of syntactic parsers and language-processing algorithms. ICA’s hierarchical decomposition proved useful for programming computers to analyze and generate syntactic structures automatically (Jurafsky & Martin, 2023).
Contemporary Applications
Today, ICA remains a useful method in both theoretical and applied linguistics. While it is no longer central to the major syntactic theories, ICA continues to be used in more practical, pedagogical contexts, such as teaching syntax and sentence parsing. ICA is still useful in explaining sentence structure in languages that do not rely on word order as heavily, such as languages with free word order or those that rely more on morphology.
Constituents and Application of ICA
A key aim of ICA is that it divides immediate constituents into smaller units. This process of breaking up sentences into smaller units until fully exhausted is seen in the hierarchical structure of syntax trees. When looking at a tree, a phrasal label, or node, lets us know that the set of substrings below that label behave in a distributionally coherent way. For example, within a sentence (S) a node that bears-the-label of a syntactic category, NP, dominates a set of substrings, and every string that precedes under this node NP, will behave similarly to an N.
Therefore, a constituent represents a dominance relationship where it includes a node and the sequence of symbols dominated by that node, forming a distributionally coherent unit. (See below for Constituent Tests). This means the symbols within the constituent function together as a single unit and behave in the same way as other elements of their category within the sentence structure. By following these relationships, it systematically breaks down the tree, starting from the root S and moving downward through its branches until all parts of the sentence are accounted for.
The Smallest Indivisible Units: Terminal Nodes
The units which no longer dominate anything else and cannot be further divided, are called terminal nodes. These are typically words or morphemes (the smallest meaningful unit), representing the final stage in a tree. A sentence, in turn, is formed as a sequence of symbols, beginning with a designated non-terminal symbol and culminating in a terminal string. Every terminal node is part of a constituent, as constituents form the interconnected structure leading from the root to the smallest, indivisible unit of the tree.
Harrisian's Structuralist Approach: Endocentric and Exocentric Constructions
Within Immediate Constituent Analysis, what has been described so far is that each node in a sentence dominates its preceding substrings, which are distributionally related to that node as a constituent. Within this framework, we have assumed that no node excludes another within the sentence; instead, all nodes are part of an interconnected hierarchical structure that extends to the terminal nodes. This configuration is referred to as an endocentric construction, where all sentence components are linked through dominance relations. The analysis concludes only when the tree has exhausted every unit.
However, Zellig Harris in his structuralist approach also allows for exocentric constructions where the category of the whole constituent is not the same as the category of its individual parts. In other words, the overall structure does not inherit the category of its components. To illustrate exocentric constructions, consider the rule S → NP VP. This rule states that when a NP and a VP are combined, the resulting structure is an S. However, S doesn't inherit the category of its components (NP and VP). In other words, the whole sentence is not categorized as a noun phrase or a verb phrase, but as a new unit—a sentence—which is an exocentric construction. The rule S → NP VP demonstrates how the combination of these parts creates a new structure that doesn’t directly reflect the properties of its individual components.
ICA in phrase structure grammars
Given a phrase structure grammar (= constituency grammar), ICA divides up a sentence into major parts or immediate constituents, and these constituents are in turn divided into further immediate constituents.[1] The process continues until irreducible constituents are reached, i.e., until each constituent consists of only a word or a meaningful part of a word. The end result of ICA is often presented in a visual diagrammatic form that reveals the hierarchical immediate constituent structure of the sentence at hand. These diagrams are usually represented as trees. For example:
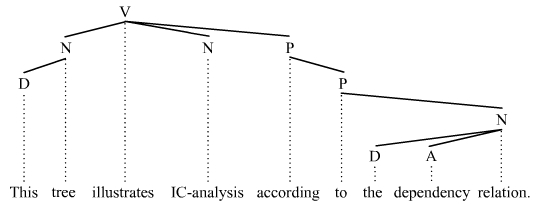
This tree illustrates the manner in which the entire sentence is divided first into the two immediate constituents this tree and illustrates ICA according to the constituency relation; these two constituents are further divided into the immediate constituents this and tree, and illustrates ICA and according to the constituency relation; and so on.
More recent literature has come forth with the argument that generative grammar applies an "array-based" structure which is derived from, but no longer a form of, ICA. More contemporary phrase structure grammar (a subset of generative grammar) models such as Bare Phrase Structure and X-Bar Theory appear to cause an inconsistent interpretation of a "constituent" as posited by ICA, moreover forsaking the distributional class properties so fundamental to ICA. This stands as the basis for the argument that generative grammar, though built upon the principles of ICA, has now developed in a different direction. It is important to note that contemporary theories and their labels are becoming incompatible with ICA, as opposed to ICA no longer driving their development; that is, while the ICA thought process is foundational to many theories, a hindsight comparison of the development of these theories over time indicates a deviation from original ICA ideas. As such, there may be a need to reconsider new foundational analyses on which to build future grammar models. Krivochen's (2024)[2] array-based analysis is one such suggestion.
A syntax tree example under bare phrase structure
This tree, represented by the more contemporary model Bare Phrase Structure, illustrates several arguments offered by Krivochen (2024) on the non-correspondence between modern generative grammar and ICA. According to ICA, the distributional properties of a category would apply to all nodes it dominates, creating supposed constituents. However, this would offer ill-formed predictions of constituents (e.g., the highest TP would, under IC-analysis, be able to select for The man has refused the present as a constituent, but this is intuitively an incorrect constituent label).
A syntax tree example under immediate constituent analysis
The third tree in this section illustrates the same sentence, “The man refused the present.”, but with an ICA correspondence. As theories have developed, it is argued that tree structures and their implications on categories and divisions have gradually moved away from models compatible with ICA. Although this tree structure is commonly used in computational linguistics, the model on which this tree is based has been considered outdated in syntax since the development of functional categories, phrasal heads, and X-Bar schema, among others, as fundamental grammar concepts.
However, because phrase structure trees and structurally simpler trees are always able to derive one another from each other and are both still used today, ICA is still relevant in many contemporary theories.
An important aspect of ICA in phrase structure grammars is that each individual word is a constituent by definition. The process of ICA always ends when the smallest constituents are reached, which are often words (although the analysis can also be extended into the words to acknowledge the manner in which words are structured). The process is, however, different in dependency grammars, since many individual words do not end up as constituents in dependency grammars.
As a rule, dependency grammars do not employ ICA, as the principle of syntactic ordering is not inclusion but, rather, asymmetrical dominance-dependency between words. When an attempt is made to incorporate ICA into a dependency-type grammar, the results are some kind of a hybrid system. In actuality, ICA is different in dependency grammars.[3] Since dependency grammars view the finite verb as the root of all sentence structure, they cannot and do not acknowledge the initial binary subject-predicate division of the clause associated with phrase structure grammars. What this means for the general understanding of constituent structure is that dependency grammars do not acknowledge a finite verb phrase (VP) constituent and many individual words also do not qualify as constituents, which means in turn that they will not show up as constituents in the ICA. Thus in the example sentence This tree illustrates ICA according to the dependency relation, many of the phrase structure grammar constituents do not qualify as dependency grammar constituents:
This ICA does not view the finite verb phrase illustrates ICA according to the dependency relation nor the individual words tree, illustrates, according, to, and relation as constituents.
While the structures that ICA identifies for dependency and constituency grammars differ in significant ways, as the two trees just produced illustrate, both views of sentence structure acknowledge constituents. The constituent is defined in a theory-neutral manner:
Constituent
A given word/node plus all the words/nodes that that word/node dominates
This definition is neutral with respect to the dependency vs. constituency distinction. It allows one to compare the ICA across the two types of structure. A constituent is always a complete tree or a complete subtree of a tree, regardless of whether the tree at hand is a constituency or a dependency tree.
Constituency tests
The ICA for a given sentence is arrived at usually by way of constituency tests. Constituency tests (e.g. topicalization, clefting, pseudoclefting, pro-form substitution, answer ellipsis, passivization, omission, coordination, etc.) identify the constituents, large and small, of English sentences. Two illustrations of the manner in which constituency tests deliver clues about constituent structure and thus about the correct ICA of a given sentence are now given. Consider the phrase The girl in the following trees:
The acronym BPS stands for "bare phrase structure", which is an indication that the words are used as the node labels in the tree. Again, focusing on the phrase The girl, the tests unanimously confirm that it is a constituent as both trees show:
...the girl is happy - Topicalization (invalid test because test constituent is already at front of sentence)
It is the girl who is happy. - Clefting
(The one)Who is happy is the girl. - Pseudoclefting
She is happy. - Pro-form substitution
Who is happy? -The girl. - Answer ellipsis
Based on these results, one can safely assume that the noun phrase The girl in the example sentence is a constituent and should therefore be shown as one in the corresponding IC-representation, which it is in both trees. Consider next what these tests tell us about the verb string is happy:
The star * indicates that the sentence is not acceptable English. Based on data like these, one might conclude that the finite verb string is happy in the example sentence is not a constituent and should therefore not be shown as a constituent in the corresponding IC-representation. Hence this result supports the ICA in the dependency tree over the one in the constituency tree, since the dependency tree does not view is happy as a constituent.
Notes
↑ The basic concept of immediate constituents is widely employed in phrase structure grammars. See for instance Akmajian and Heny (1980:64), Chisholm (1981:59), Culicover (1982:21), Huddleston (1988:7), Haegeman and Guéron (1999:51).
↑ Krivochen, D. (2024). Constituents, arrays, and trees: two (more) models of grammatical description. Folia Linguistica, 58(3), 699-727. https://doi.org/10.1515/flin-2024-2025
↑ Concerning dependency grammars, see Ágel et al. (2003/6).
References
Akmajian, A. and F. Heny. 1980. An introduction to the principles of transformational syntax. Cambridge, MA: The MIT Press.
Ágel, V., L. Eichinger, H.-W. Eroms, P. Hellwig, H. Heringer, and H. Lobin (eds.) 2003/6. Dependency and valency: An international handbook of contemporary research. Berlin: Walter de Gruyter.
Chisholm, W. 1981. Elements of English linguistics. New York: Longman.
Culicover, P. 1982. Syntax, 2nd edition. New York: Academic Press.
Chomsky, Noam. (1962). “A Transformation Approach to Syntax” in A. A. Hill. Proceedings of the Third Texas Conference on Problems of Linguistic Analysis in English, 1958. U of Texas.
Chomsky, Noam. (1981). Lectures on Government and Binding. Dordrecht: Foris.
Chomsky, Noam 1957. Syntactic Structures. The Hague/Paris: Mouton.
Haegeman, L. and J. Guéron. 1999. English grammar: A generative perspective. Oxford, UK: Blackwell Publishers.
Huddleston, R. 1988. English grammar: An outline. Cambridge, UK: Cambridge University Press.
Jensen, Klaus Bruhn (2002). A Handbook of Media and Communication Research: Qualitative and Quantitative Methodologies. London: Routledge.
Jurafsky, D., & Martin, J. H. (2023). Speech and Language Processing (3rd ed.). Pearson.
Krivochen, D. (2024). Constituents, arrays, and trees: two (more) models of grammatical description. Folia Linguistica, 58(3), 699-727. https://doi.org/10.1515/flin-2024-2025
Wells, Rulon S. 1947. "Immediate Constituents." Language: 23. pp.81–117.
Zellig, Harris. 1951. Methods in Structural Linguistics. Chicago: University of Chicago Press, xvi, 384.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.