
In formal language theory, a context-free grammar (CFG) is a formal grammar in which every production rule is of the form
In mathematics, computer science, and linguistics, a formal language consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules.
In computer science, LR parsers are a type of bottom-up parser that analyses deterministic context-free languages in linear time. There are several variants of LR parsers: SLR parsers, LALR parsers, Canonical LR(1) parsers, Minimal LR(1) parsers, GLR parsers. LR parsers can be generated by a parser generator from a formal grammar defining the syntax of the language to be parsed. They are widely used for the processing of computer languages.
In computer science, the Cocke–Younger–Kasami algorithm is a parsing algorithm for context-free grammars, named after its inventors, John Cocke, Daniel Younger and Tadao Kasami. It employs bottom-up parsing and dynamic programming.
In computer science, an LL parser is a top-down parser for a subset of context-free languages. It parses the input from Left to right, performing Leftmost derivation of the sentence.
In computer science, Backus–Naur form or Backus normal form (BNF) is a notation technique for context-free grammars, often used to describe the syntax of languages used in computing, such as computer programming languages, document formats, instruction sets and communication protocols. They are applied wherever exact descriptions of languages are needed: for instance, in official language specifications, in manuals, and in textbooks on programming language theory.
In computer science, a compiler-compiler or compiler generator is a programming tool that creates a parser, interpreter, or compiler from some form of formal description of a programming language and machine.
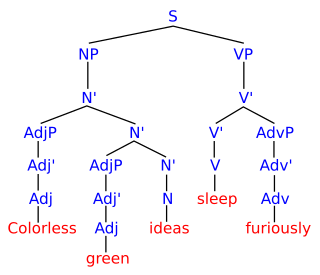
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Top-down parsing in computer science is a parsing strategy where one first looks at the highest level of the parse tree and works down the parse tree by using the rewriting rules of a formal grammar. LL parsers are a type of parser that uses a top-down parsing strategy.
An attribute grammar is a formal way to define attributes for the productions of a formal grammar, associating these attributes with values. The evaluation occurs in the nodes of the abstract syntax tree, when the language is processed by some parser or compiler.
Categorial grammar is a term used for a family of formalisms in natural language syntax motivated by the principle of compositionality and organized according to the view that syntactic constituents should generally combine as functions or according to a function-argument relationship. Most versions of categorial grammar analyze sentence structure in terms of constituencies and are therefore phrase structure grammars.
In computer science, a parsing expression grammar (PEG), is a type of analytic formal grammar, i.e. it describes a formal language in terms of a set of rules for recognizing strings in the language. The formalism was introduced by Bryan Ford in 2004 and is closely related to the family of top-down parsing languages introduced in the early 1970s. Syntactically, PEGs also look similar to context-free grammars (CFGs), but they have a different interpretation: the choice operator selects the first match in PEG, while it is ambiguous in CFG. This is closer to how string recognition tends to be done in practice, e.g. by a recursive descent parser.
In the formal language theory of computer science, left recursion is a special case of recursion where a string is recognized as part of a language by the fact that it decomposes into a string from that same language and a suffix. For instance, can be recognized as a sum because it can be broken into , also a sum, and , a suitable suffix.
A simple precedence grammar is a context-free formal grammar that can be parsed with a simple precedence parser. The concept was first created in 1964 by Claude Pair, and was later rediscovered, from ideas due to Robert Floyd, by Niklaus Wirth and Helmut Weber who published a paper, entitled EULER: a generalization of ALGOL, and its formal definition, published in 1966 in the Communications of the ACM.
Syntax-directed translation refers to a method of compiler implementation where the source language translation is completely driven by the parser.

In computer science, the syntax of a computer language is the set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in that language. This applies both to programming languages, where the document represents source code, and to markup languages, where the document represents data.
LR-attributed grammars are a special type of attribute grammars. They allow the attributes to be evaluated on LR parsing. As a result, attribute evaluation in LR-attributed grammars can be incorporated conveniently in bottom-up parsing. zyacc is based on LR-attributed grammars. They are a subset of the L-attributed grammars, where the attributes can be evaluated in one left-to-right traversal of the abstract syntax tree. They are a superset of the S-attributed grammars, which allow only synthesized attributes. In yacc, a common hack is to use global variables to simulate some kind of inherited attributes and thus LR-attribution.
A syntactic predicate specifies the syntactic validity of applying a production in a formal grammar and is analogous to a semantic predicate that specifies the semantic validity of applying a production. It is a simple and effective means of dramatically improving the recognition strength of an LL parser by providing arbitrary lookahead. In their original implementation, syntactic predicates had the form “( α )?” and could only appear on the left edge of a production. The required syntactic condition α could be any valid context-free grammar fragment.
In formal language theory, a grammar describes how to form strings from a language's alphabet that are valid according to the language's syntax. A grammar does not describe the meaning of the strings or what can be done with them in whatever context—only their form. A formal grammar is defined as a set of production rules for strings in a formal language.
A shift-reduce parser is a class of efficient, table-driven bottom-up parsing methods for computer languages and other notations formally defined by a grammar. The parsing methods most commonly used for parsing programming languages, LR parsing and its variations, are shift-reduce methods. The precedence parsers used before the invention of LR parsing are also shift-reduce methods. All shift-reduce parsers have similar outward effects, in the incremental order in which they build a parse tree or call specific output actions.




