Related Research Articles

A self-organizing map (SOM) or self-organizing feature map (SOFM) is an unsupervised machine learning technique used to produce a low-dimensional representation of a higher dimensional data set while preserving the topological structure of the data. For example, a data set with variables measured in observations could be represented as clusters of observations with similar values for the variables. These clusters then could be visualized as a two-dimensional "map" such that observations in proximal clusters have more similar values than observations in distal clusters. This can make high-dimensional data easier to visualize and analyze.
Computational neuroscience is a branch of neuroscience which employs mathematical models, computer simulations, theoretical analysis and abstractions of the brain to understand the principles that govern the development, structure, physiology and cognitive abilities of the nervous system.

In computability theory, the theory of real computation deals with hypothetical computing machines using infinite-precision real numbers. They are given this name because they operate on the set of real numbers. Within this theory, it is possible to prove interesting statements such as "The complement of the Mandelbrot set is only partially decidable."

A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes can create a cycle, allowing output from some nodes to affect subsequent input to the same nodes. This allows it to exhibit temporal dynamic behavior. Derived from feedforward neural networks, RNNs can use their internal state (memory) to process variable length sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. Recurrent neural networks are theoretically Turing complete and can run arbitrary programs to process arbitrary sequences of inputs.

A feedforward neural network (FNN) is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from its descendant: recurrent neural networks.

A neural network can refer to either a neural circuit of biological neurons, or a network of artificial neurons or nodes in the case of an artificial neural network. Artificial neural networks are used for solving artificial intelligence (AI) problems; they model connections of biological neurons as weights between nodes. A positive weight reflects an excitatory connection, while negative values mean inhibitory connections. All inputs are modified by a weight and summed. This activity is referred to as a linear combination. Finally, an activation function controls the amplitude of the output. For example, an acceptable range of output is usually between 0 and 1, or it could be −1 and 1.
Winner-take-all is a computational principle applied in computational models of neural networks by which neurons compete with each other for activation. In the classical form, only the neuron with the highest activation stays active while all other neurons shut down; however, other variations allow more than one neuron to be active, for example the soft winner take-all, by which a power function is applied to the neurons.
Neurophilosophy or philosophy of neuroscience is the interdisciplinary study of neuroscience and philosophy that explores the relevance of neuroscientific studies to the arguments traditionally categorized as philosophy of mind. The philosophy of neuroscience attempts to clarify neuroscientific methods and results using the conceptual rigor and methods of philosophy of science.
Sensory neuroscience is a subfield of neuroscience which explores the anatomy and physiology of neurons that are part of sensory systems such as vision, hearing, and olfaction. Neurons in sensory regions of the brain respond to stimuli by firing one or more nerve impulses following stimulus presentation. How is information about the outside world encoded by the rate, timing, and pattern of action potentials? This so-called neural code is currently poorly understood and sensory neuroscience plays an important role in the attempt to decipher it. Looking at early sensory processing is advantageous since brain regions that are "higher up" contain neurons which encode more abstract representations. However, the hope is that there are unifying principles which govern how the brain encodes and processes information. Studying sensory systems is an important stepping stone in our understanding of brain function in general.
Leabra stands for local, error-driven and associative, biologically realistic algorithm. It is a model of learning which is a balance between Hebbian and error-driven learning with other network-derived characteristics. This model is used to mathematically predict outcomes based on inputs and previous learning influences. This model is heavily influenced by and contributes to neural network designs and models. This algorithm is the default algorithm in emergent when making a new project, and is extensively used in various simulations.

An echo state network (ESN) is a type of reservoir computer that uses a recurrent neural network with a sparsely connected hidden layer. The connectivity and weights of hidden neurons are fixed and randomly assigned. The weights of output neurons can be learned so that the network can produce or reproduce specific temporal patterns. The main interest of this network is that although its behaviour is non-linear, the only weights that are modified during training are for the synapses that connect the hidden neurons to output neurons. Thus, the error function is quadratic with respect to the parameter vector and can be differentiated easily to a linear system.

Spiking neural networks (SNNs) are artificial neural networks that more closely mimic natural neural networks. In addition to neuronal and synaptic state, SNNs incorporate the concept of time into their operating model. The idea is that neurons in the SNN do not transmit information at each propagation cycle, but rather transmit information only when a membrane potential – an intrinsic quality of the neuron related to its membrane electrical charge – reaches a specific value, called the threshold. When the membrane potential reaches the threshold, the neuron fires, and generates a signal that travels to other neurons which, in turn, increase or decrease their potentials in response to this signal. A neuron model that fires at the moment of threshold crossing is also called a spiking neuron model.
Reservoir computing is a framework for computation derived from recurrent neural network theory that maps input signals into higher dimensional computational spaces through the dynamics of a fixed, non-linear system called a reservoir. After the input signal is fed into the reservoir, which is treated as a "black box," a simple readout mechanism is trained to read the state of the reservoir and map it to the desired output. The first key benefit of this framework is that training is performed only at the readout stage, as the reservoir dynamics are fixed. The second is that the computational power of naturally available systems, both classical and quantum mechanical, can be used to reduce the effective computational cost.
Hierarchical temporal memory (HTM) is a biologically constrained machine intelligence technology developed by Numenta. Originally described in the 2004 book On Intelligence by Jeff Hawkins with Sandra Blakeslee, HTM is primarily used today for anomaly detection in streaming data. The technology is based on neuroscience and the physiology and interaction of pyramidal neurons in the neocortex of the mammalian brain.

Henry John Markram is a South African-born Israeli neuroscientist, professor at the École Polytechnique Fédérale de Lausanne (EPFL) in Switzerland and director of the Blue Brain Project and founder of the Human Brain Project.
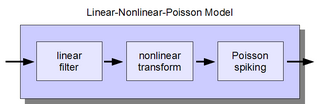
The linear-nonlinear-Poisson (LNP) cascade model is a simplified functional model of neural spike responses. It has been successfully used to describe the response characteristics of neurons in early sensory pathways, especially the visual system. The LNP model is generally implicit when using reverse correlation or the spike-triggered average to characterize neural responses with white-noise stimuli.
Models of neural computation are attempts to elucidate, in an abstract and mathematical fashion, the core principles that underlie information processing in biological nervous systems, or functional components thereof. This article aims to provide an overview of the most definitive models of neuro-biological computation as well as the tools commonly used to construct and analyze them.
There are many types of artificial neural networks (ANN).
Network of human nervous system comprises nodes that are connected by links. The connectivity may be viewed anatomically, functionally, or electrophysiologically. These are presented in several Wikipedia articles that include Connectionism, Biological neural network, Artificial neural network, Computational neuroscience, as well as in several books by Ascoli, G. A. (2002), Sterratt, D., Graham, B., Gillies, A., & Willshaw, D. (2011), Gerstner, W., & Kistler, W. (2002), and Rumelhart, J. L., McClelland, J. L., and PDP Research Group (1986) among others. The focus of this article is a comprehensive view of modeling a neural network. Once an approach based on the perspective and connectivity is chosen, the models are developed at microscopic, mesoscopic, or macroscopic (system) levels. Computational modeling refers to models that are developed using computing tools.
In deep learning, a convolutional neural network (CNN) is a class of artificial neural network most commonly applied to analyze visual imagery. CNNs use a mathematical operation called convolution in place of general matrix multiplication in at least one of their layers. They are specifically designed to process pixel data and are used in image recognition and processing. They have applications in image and video recognition, recommender systems, image classification, image segmentation, medical image analysis, natural language processing, brain–computer interfaces, and financial time series.
References
- ↑ Maass, Wolfgang; Markram, Henry (2004), "On the Computational Power of Recurrent Circuits of Spiking Neurons", Journal of Computer and System Sciences, 69 (4): 593–616, doi: 10.1016/j.jcss.2004.04.001
- ↑ Hananel, Hazan; Larry, M., Manevit (2012), "Topological constraints and robustness in liquid state machines", Expert Systems with Applications, 39 (2): 1597–1606, doi:10.1016/j.eswa.2011.06.052.
{{citation}}: CS1 maint: multiple names: authors list (link)
- Maass, Wolfgang; Natschläger, Thomas; Markram, Henry (November 2002), "Real-time computing without stable states: a new framework for neural computation based on perturbations" (PDF), Neural Comput, 14 (11): 2531–60, CiteSeerX 10.1.1.183.2874 , doi:10.1162/089976602760407955, PMID 12433288, S2CID 1045112, archived from the original on February 22, 2012.
{{citation}}: CS1 maint: unfit URL (link) - Wolfgang Maass; Thomas Natschläger; Henry Markram (2004), "Computational Models for Generic Cortical Microcircuits" (PDF), In Computational Neuroscience: A Comprehensive Approach, Ch 18, 18: 575–605