
The polymerase chain reaction (PCR) is a method widely used to rapidly make millions to billions of copies of a specific DNA sample, allowing scientists to take a very small sample of DNA and amplify it to a large enough amount to study in detail. PCR was invented in 1983 by the American biochemist Kary Mullis at Cetus Corporation; Mullis and biochemist Michael Smith, who had developed other essential ways of manipulating DNA, were jointly awarded the Nobel Prize in Chemistry in 1993.
In molecular biology, restriction fragment length polymorphism (RFLP) is a technique that exploits variations in homologous DNA sequences, known as polymorphisms, in order to distinguish individuals, populations, or species or to pinpoint the locations of genes within a sequence. The term may refer to a polymorphism itself, as detected through the differing locations of restriction enzyme sites, or to a related laboratory technique by which such differences can be illustrated. In RFLP analysis, a DNA sample is digested into fragments by one or more restriction enzymes, and the resulting restriction fragments are then separated by gel electrophoresis according to their size.
This is a list of topics in molecular biology. See also index of biochemistry articles.

Sanger sequencing is a method of DNA sequencing that involves electrophoresis and is based on the random incorporation of chain-terminating dideoxynucleotides by DNA polymerase during in vitro DNA replication. After first being developed by Frederick Sanger and colleagues in 1977, it became the most widely used sequencing method for approximately 40 years. It was first commercialized by Applied Biosystems in 1986. More recently, higher volume Sanger sequencing has been replaced by next generation sequencing methods, especially for large-scale, automated genome analyses. However, the Sanger method remains in wide use for smaller-scale projects and for validation of deep sequencing results. It still has the advantage over short-read sequencing technologies in that it can produce DNA sequence reads of > 500 nucleotides and maintains a very low error rate with accuracies around 99.99%. Sanger sequencing is still actively being used in efforts for public health initiatives such as sequencing the spike protein from SARS-CoV-2 as well as for the surveillance of norovirus outbreaks through the Center for Disease Control and Prevention's (CDC) CaliciNet surveillance network.
Genotyping is the process of determining differences in the genetic make-up (genotype) of an individual by examining the individual's DNA sequence using biological assays and comparing it to another individual's sequence or a reference sequence. It reveals the alleles an individual has inherited from their parents. Traditionally genotyping is the use of DNA sequences to define biological populations by use of molecular tools. It does not usually involve defining the genes of an individual.
SNP genotyping is the measurement of genetic variations of single nucleotide polymorphisms (SNPs) between members of a species. It is a form of genotyping, which is the measurement of more general genetic variation. SNPs are one of the most common types of genetic variation. An SNP is a single base pair mutation at a specific locus, usually consisting of two alleles. SNPs are found to be involved in the etiology of many human diseases and are becoming of particular interest in pharmacogenetics. Because SNPs are conserved during evolution, they have been proposed as markers for use in quantitative trait loci (QTL) analysis and in association studies in place of microsatellites. The use of SNPs is being extended in the HapMap project, which aims to provide the minimal set of SNPs needed to genotype the human genome. SNPs can also provide a genetic fingerprint for use in identity testing. The increase of interest in SNPs has been reflected by the furious development of a diverse range of SNP genotyping methods.

Bisulfitesequencing (also known as bisulphite sequencing) is the use of bisulfite treatment of DNA before routine sequencing to determine the pattern of methylation. DNA methylation was the first discovered epigenetic mark, and remains the most studied. In animals it predominantly involves the addition of a methyl group to the carbon-5 position of cytosine residues of the dinucleotide CpG, and is implicated in repression of transcriptional activity.
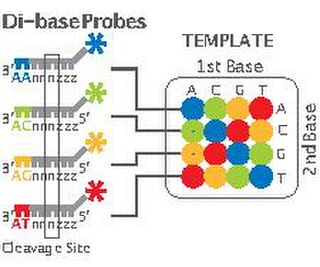
2 Base Encoding, also called SOLiD, is a next-generation sequencing technology developed by Applied Biosystems and has been commercially available since 2008. These technologies generate hundreds of thousands of small sequence reads at one time. Well-known examples of such DNA sequencing methods include 454 pyrosequencing, the Solexa system and the SOLiD system. These methods have reduced the cost from $0.01/base in 2004 to nearly $0.0001/base in 2006 and increased the sequencing capacity from 1,000,000 bases/machine/day in 2004 to more than 100,000,000 bases/machine/day in 2006.

The history of the polymerase chain reaction (PCR) has variously been described as a classic "Eureka!" moment, or as an example of cooperative teamwork between disparate researchers. Following is a list of events before, during, and after its development:
The versatility of polymerase chain reaction (PCR) has led to a large number of variants of PCR.
Multiple displacement amplification (MDA) is a DNA amplification technique. This method can rapidly amplify minute amounts of DNA samples to a reasonable quantity for genomic analysis. The reaction starts by annealing random hexamer primers to the template: DNA synthesis is carried out by a high fidelity enzyme, preferentially Φ29 DNA polymerase. Compared with conventional PCR amplification techniques, MDA does not employ sequence-specific primers but amplifies all DNA, generates larger-sized products with a lower error frequency, and works at a constant temperature. MDA has been actively used in whole genome amplification (WGA) and is a promising method for application to single cell genome sequencing and sequencing-based genetic studies.
Multiplex polymerase chain reaction refers to the use of polymerase chain reaction to amplify several different DNA sequences simultaneously. This process amplifies DNA in samples using multiple primers and a temperature-mediated DNA polymerase in a thermal cycler. The primer design for all primers pairs has to be optimized so that all primer pairs can work at the same annealing temperature during PCR.
COLD-PCR is a modified polymerase chain reaction (PCR) protocol that enriches variant alleles from a mixture of wildtype and mutation-containing DNA. The ability to preferentially amplify and identify minority alleles and low-level somatic DNA mutations in the presence of excess wildtype alleles is useful for the detection of mutations. Detection of mutations is important in the case of early cancer detection from tissue biopsies and body fluids such as blood plasma or serum, assessment of residual disease after surgery or chemotherapy, disease staging and molecular profiling for prognosis or tailoring therapy to individual patients, and monitoring of therapy outcome and cancer remission or relapse. Common PCR will amplify both the major (wildtype) and minor (mutant) alleles with the same efficiency, occluding the ability to easily detect the presence of low-level mutations. The capacity to detect a mutation in a mixture of variant/wildtype DNA is valuable because this mixture of variant DNAs can occur when provided with a heterogeneous sample – as is often the case with cancer biopsies. Currently, traditional PCR is used in tandem with a number of different downstream assays for genotyping or the detection of somatic mutations. These can include the use of amplified DNA for RFLP analysis, MALDI-TOF genotyping, or direct sequencing for detection of mutations by Sanger sequencing or pyrosequencing. Replacing traditional PCR with COLD-PCR for these downstream assays will increase the reliability in detecting mutations from mixed samples, including tumors and body fluids.

DNA nanoball sequencing is a high throughput sequencing technology that is used to determine the entire genomic sequence of an organism. The method uses rolling circle replication to amplify small fragments of genomic DNA into DNA nanoballs. Fluorescent nucleotides bind to complementary nucleotides and are then polymerized to anchor sequences bound to known sequences on the DNA template. The base order is determined via the fluorescence of the bound nucleotides This DNA sequencing method allows large numbers of DNA nanoballs to be sequenced per run at lower reagent costs compared to other next generation sequencing platforms. However, a limitation of this method is that it generates only short sequences of DNA, which presents challenges to mapping its reads to a reference genome. After purchasing Complete Genomics, the Beijing Genomics Institute (BGI) refined DNA nanoball sequencing to sequence nucleotide samples on their own platform.
Massive parallel sequencing or massively parallel sequencing is any of several high-throughput approaches to DNA sequencing using the concept of massively parallel processing; it is also called next-generation sequencing (NGS) or second-generation sequencing. Some of these technologies emerged between 1994 and 1998 and have been commercially available since 2005. These technologies use miniaturized and parallelized platforms for sequencing of 1 million to 43 billion short reads per instrument run.

Illumina dye sequencing is a technique used to determine the series of base pairs in DNA, also known as DNA sequencing. The reversible terminated chemistry concept was invented by Bruno Canard and Simon Sarfati at the Pasteur Institute in Paris. It was developed by Shankar Balasubramanian and David Klenerman of Cambridge University, who subsequently founded Solexa, a company later acquired by Illumina. This sequencing method is based on reversible dye-terminators that enable the identification of single nucleotides as they are washed over DNA strands. It can also be used for whole-genome and region sequencing, transcriptome analysis, metagenomics, small RNA discovery, methylation profiling, and genome-wide protein-nucleic acid interaction analysis.
Single-cell DNA template strand sequencing, or Strand-seq, is a technique for the selective sequencing of a daughter cell's parental template strands. This technique offers a wide variety of applications, including the identification of sister chromatid exchanges in the parental cell prior to segregation, the assessment of non-random segregation of sister chromatids, the identification of misoriented contigs in genome assemblies, de novo genome assembly of both haplotypes in diploid organisms including humans, whole-chromosome haplotyping, and the identification of germline and somatic genomic structural variation, the latter of which can be detected robustly even in single cells.
G&T-seq is a novel form of single cell sequencing technique allowing one to simultaneously obtain both transcriptomic and genomic data from single cells, allowing for direct comparison of gene expression data to its corresponding genomic data in the same cell...

Duplex sequencing is a library preparation and analysis method for next-generation sequencing (NGS) platforms that employs random tagging of double-stranded DNA to detect mutations with higher accuracy and lower error rates.

Linear Amplification via Transposon Insertion (LIANTI) is a linear whole genome amplification (WGA) method. To analyze or sequence very small amount of DNA, i.e. genomic DNA from a single cell, the picograms of DNA is subject to WGA to amplify at least thousands of times into nanogram scale, before DNA analysis or sequencing can be carried out. Previous WGA methods use exponential/nonlinear amplification schemes, leading to bias accumulation and error propagation. LIANTI achieved linear amplification of the whole genome for the first time, enabling more uniform and accurate amplification.

