
Proteomics is the large-scale study of proteins. Proteins are vital parts of living organisms, with many functions such as the formation of structural fibers of muscle tissue, enzymatic digestion of food, or synthesis and replication of DNA. In addition, other kinds of proteins include antibodies that protect an organism from infection, and hormones that send important signals throughout the body.

Tandem mass spectrometry, also known as MS/MS or MS2, is a technique in instrumental analysis where two or more stages of analysis using one or more mass analyzer are performed with an additional reaction step in between these analyses to increase their abilities to analyse chemical samples. A common use of tandem MS is the analysis of biomolecules, such as proteins and peptides.
Protein sequencing is the practical process of determining the amino acid sequence of all or part of a protein or peptide. This may serve to identify the protein or characterize its post-translational modifications. Typically, partial sequencing of a protein provides sufficient information to identify it with reference to databases of protein sequences derived from the conceptual translation of genes.

Peptide mass fingerprinting (PMF), also known as protein fingerprinting, is an analytical technique for protein identification in which the unknown protein of interest is first cleaved into smaller peptides, whose absolute masses can be accurately measured with a mass spectrometer such as MALDI-TOF or ESI-TOF. The method was developed in 1993 by several groups independently. The peptide masses are compared to either a database containing known protein sequences or even the genome. This is achieved by using computer programs that translate the known genome of the organism into proteins, then theoretically cut the proteins into peptides, and calculate the absolute masses of the peptides from each protein. They then compare the masses of the peptides of the unknown protein to the theoretical peptide masses of each protein encoded in the genome. The results are statistically analyzed to find the best match.

In mass spectrometry, matrix-assisted laser desorption/ionization (MALDI) is an ionization technique that uses a laser energy-absorbing matrix to create ions from large molecules with minimal fragmentation. It has been applied to the analysis of biomolecules and various organic molecules, which tend to be fragile and fragment when ionized by more conventional ionization methods. It is similar in character to electrospray ionization (ESI) in that both techniques are relatively soft ways of obtaining ions of large molecules in the gas phase, though MALDI typically produces far fewer multi-charged ions.
Sequest is a tandem mass spectrometry data analysis program used for protein identification. Sequest identifies collections of tandem mass spectra to peptide sequences that have been generated from databases of protein sequences.
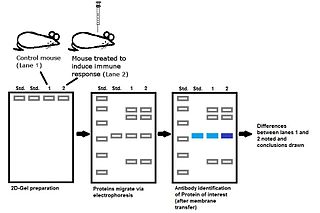
Immunoproteomics is the study of large sets of proteins (proteomics) involved in the immune response.
Genome-based peptide fingerprint scanning (GFS) is a system in bioinformatics analysis that attempts to identify the genomic origin of sample proteins by scanning their peptide-mass fingerprint against the theoretical translation and proteolytic digest of an entire genome. This method is an improvement from previous methods because it compares the peptide fingerprints to an entire genome instead of comparing it to an already annotated genome. This improvement has the potential to improve genome annotation and identify proteins with incorrect or missing annotations.
The Trans-Proteomic Pipeline (TPP) is an open-source data analysis software for proteomics developed at the Institute for Systems Biology (ISB) by the Ruedi Aebersold group under the Seattle Proteome Center. The TPP includes PeptideProphet, ProteinProphet, ASAPRatio, XPRESS and Libra.
Mascot is a software search engine that uses mass spectrometry data to identify proteins from peptide sequence databases. Mascot is widely used by research facilities around the world. Mascot uses a probabilistic scoring algorithm for protein identification that was adapted from the MOWSE algorithm. Mascot is freely available to use on the website of Matrix Science. A license is required for in-house use where more features can be incorporated.
PEAKS is a proteomics software program for tandem mass spectrometry designed for peptide sequencing, protein identification and quantification.
A tandem mass tag (TMT) is a chemical label that facilitates sample multiplexing in mass spectrometry (MS)-based quantification and identification of biological macromolecules such as proteins, peptides and nucleic acids. TMT belongs to a family of reagents referred to as isobaric mass tags which are a set of molecules with the same mass, but yield reporter ions of differing mass after fragmentation. The relative ratio of the measured reporter ions represents the relative abundance of the tagged molecule, although ion suppression has a detrimental effect on accuracy. Despite these complications, TMT-based proteomics has been shown to afford higher precision than Label-free quantification. In addition to aiding in protein quantification, TMT tags can also increase the detection sensitivity of certain highly hydrophilic analytes, such as phosphopeptides, in RPLC-MS analyses.

Protein mass spectrometry refers to the application of mass spectrometry to the study of proteins. Mass spectrometry is an important method for the accurate mass determination and characterization of proteins, and a variety of methods and instrumentations have been developed for its many uses. Its applications include the identification of proteins and their post-translational modifications, the elucidation of protein complexes, their subunits and functional interactions, as well as the global measurement of proteins in proteomics. It can also be used to localize proteins to the various organelles, and determine the interactions between different proteins as well as with membrane lipids.
Shotgun proteomics refers to the use of bottom-up proteomics techniques in identifying proteins in complex mixtures using a combination of high performance liquid chromatography combined with mass spectrometry. The name is derived from shotgun sequencing of DNA which is itself named after the rapidly expanding, quasi-random firing pattern of a shotgun. The most common method of shotgun proteomics starts with the proteins in the mixture being digested and the resulting peptides are separated by liquid chromatography. Tandem mass spectrometry is then used to identify the peptides.
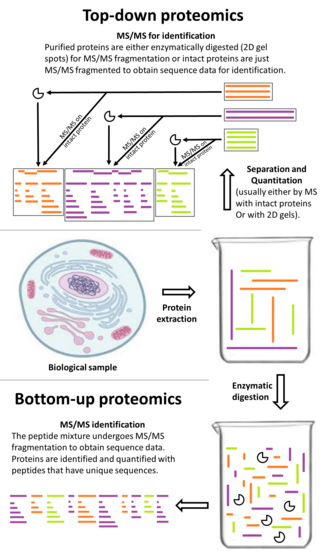
Bottom-up proteomics is a common method to identify proteins and characterize their amino acid sequences and post-translational modifications by proteolytic digestion of proteins prior to analysis by mass spectrometry. The major alternative workflow used in proteomics is called top-down proteomics where intact proteins are purified prior to digestion and/or fragmentation either within the mass spectrometer or by 2D electrophoresis. Essentially, bottom-up proteomics is a relatively simple and reliable means of determining the protein make-up of a given sample of cells, tissues, etc.

Isobaric tags for relative and absolute quantitation (iTRAQ) is an isobaric labeling method used in quantitative proteomics by tandem mass spectrometry to determine the amount of proteins from different sources in a single experiment. It uses stable isotope labeled molecules that can be covalent bonded to the N-terminus and side chain amines of proteins.

Isobaric labeling is a mass spectrometry strategy used in quantitative proteomics. Peptides or proteins are labeled with chemical groups that have identical mass (isobaric), but vary in terms of distribution of heavy isotopes in their structure. These tags, commonly referred to as tandem mass tags, are designed so that the mass tag is cleaved at a specific linker region upon high-energy CID (HCD) during tandem mass spectrometry yielding reporter ions of different masses. The most common isobaric tags are amine-reactive tags. However, tags that react with cysteine residues and carbonyl groups have also been described. These amine-reactive groups go through N-hydroxysuccinimide (NHS) reactions, which are based around three types of functional groups. Isobaric labeling methods include tandem mass tags (TMT), isobaric tags for relative and absolute quantification (iTRAQ), mass differential tags for absolute and relative quantification, and dimethyl labeling. TMTs and iTRAQ methods are most common and developed of these methods. Tandem mass tags have a mass reporter region, a cleavable linker region, a mass normalization region, and a protein reactive group and have the same total mass.
In bio-informatics, a peptide-mass fingerprint or peptide-mass map is a mass spectrum of a mixture of peptides that comes from a digested protein being analyzed. The mass spectrum serves as a fingerprint in the sense that it is a pattern that can serve to identify the protein. The method for forming a peptide-mass fingerprint, developed in 1993, consists of isolating a protein, breaking it down into individual peptides, and determining the masses of the peptides through some form of mass spectrometry. Once formed, a peptide-mass fingerprint can be used to search in databases for related protein or even genomic sequences, making it a powerful tool for annotation of protein-coding genes.