
In computer science, heapsort is a comparison-based sorting algorithm. Heapsort can be thought of as an improved selection sort: like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to more quickly find the largest element in each step.

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, a priority queue is an abstract data type similar to a regular queue or stack data structure in which each element additionally has a "priority" associated with it. In a priority queue, an element with high priority is served before an element with low priority. In some implementations, if two elements have the same priority, they are served according to the order in which they were enqueued, while in other implementations, ordering of elements with the same priority is undefined.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.

In computer science, Prim'salgorithm is a greedy algorithm that finds a minimum spanning tree for a weighted undirected graph. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. The algorithm operates by building this tree one vertex at a time, from an arbitrary starting vertex, at each step adding the cheapest possible connection from the tree to another vertex.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
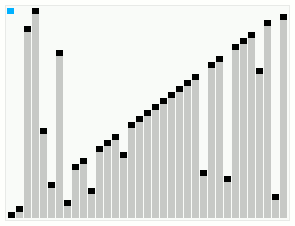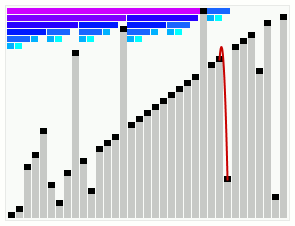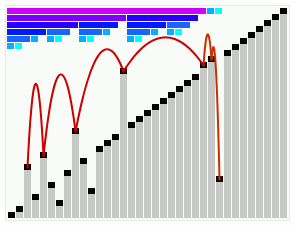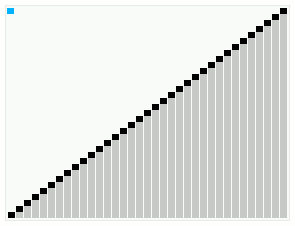
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.
In computer science, a binomial heap is a data structure that acts as a priority queue but also allows pairs of heaps to be merged. It is important as an implementation of the mergeable heap abstract data type, which is a priority queue supporting merge operation. It is implemented as a heap similar to a binary heap but using a special tree structure that is different from the complete binary trees used by binary heaps. Binomial heaps were invented in 1978 by Jean Vuillemin.
In computer science, a Fibonacci heap is a data structure for priority queue operations, consisting of a collection of heap-ordered trees. It has a better amortized running time than many other priority queue data structures including the binary heap and binomial heap. Michael L. Fredman and Robert E. Tarjan developed Fibonacci heaps in 1984 and published them in a scientific journal in 1987. Fibonacci heaps are named after the Fibonacci numbers, which are used in their running time analysis.
In computer science, the AF-heap is a type of priority queue for integer data, an extension of the fusion tree using an atomic heap proposed by M. L. Fredman and D. E. Willard.
In computer science, a leftist tree or leftist heap is a priority queue implemented with a variant of a binary heap. Every node x has an s-value which is the distance to the nearest leaf in subtree rooted at x. In contrast to a binary heap, a leftist tree attempts to be very unbalanced. In addition to the heap property, leftist trees are maintained so the right descendant of each node has the lower s-value.
A pairing heap is a type of heap data structure with relatively simple implementation and excellent practical amortized performance, introduced by Michael Fredman, Robert Sedgewick, Daniel Sleator, and Robert Tarjan in 1986. Pairing heaps are heap-ordered multiway tree structures, and can be considered simplified Fibonacci heaps. They are considered a "robust choice" for implementing such algorithms as Prim's MST algorithm, and support the following operations :
The d-ary heap or d-heap is a priority queue data structure, a generalization of the binary heap in which the nodes have d children instead of 2. Thus, a binary heap is a 2-heap, and a ternary heap is a 3-heap. According to Tarjan and Jensen et al., d-ary heaps were invented by Donald B. Johnson in 1975.
Reservoir sampling is a family of randomized algorithms for choosing a simple random sample, without replacement, of k items from a population of unknown size n in a single pass over the items. The size of the population n is not known to the algorithm and is typically too large for all n items to fit into main memory. The population is revealed to the algorithm over time, and the algorithm cannot look back at previous items. At any point, the current state of the algorithm must permit extraction of a simple random sample without replacement of size k over the part of the population seen so far.
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by integer keys. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers, rational numbers, or text strings. The ability to perform integer arithmetic on the keys allows integer sorting algorithms to be faster than comparison sorting algorithms in many cases, depending on the details of which operations are allowed in the model of computing and how large the integers to be sorted are.
In computer science, the Brodal queue is a heap/priority queue structure with very low worst case time bounds: for insertion, find-minimum, meld and decrease-key and for delete-minimum and general deletion. They are the first heap variant to achieve these bounds without resorting to amortization of operational costs. Brodal queues are named after their inventor Gerth Stølting Brodal.
In computer science, a shadow heap is a mergeable heap data structure which supports efficient heap merging in the amortized sense. More specifically, shadow heaps make use of the shadow merge algorithm to achieve insertion in O(f ) amortized time and deletion in O( /f ) amortized time, for any choice of 1 ≤ f(n) ≤ log log n.
A radix heap is a data structure for realizing the operations of a monotone priority queue. A set of elements to which a key is assigned can then be managed. The run time of the operations depends on the difference between the largest and smallest key or constant. The data structure consists mainly of a series of buckets, the size of which increases exponentially.

In the design and analysis of data structures, a bucket queue is a priority queue for prioritizing elements whose priorities are small integers. It has the form of an array of buckets: an array data structure, indexed by the priorities, whose cells contain buckets of items with the same priority as each other. With this data structure, insertion or removal of elements takes constant time. Searches for the minimum-priority element take time proportional to the number of buckets or, by maintaining a pointer to the most recently found bucket, in time proportional to the difference in priorities between the results of successive searches.

