
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.

In computing, a hash table is a data structure that implements an associative array, also called a dictionary or simply map, which is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.

In computer science, a heap is a tree-based data structure that satisfies the heap property: In a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, a priority queue is an abstract data type similar to a regular queue or stack abstract data type. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order in which they were enqueued. In other implementations, the order of elements with the same priority is undefined.
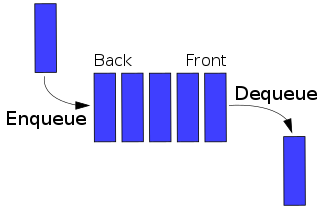
In computer science, a queue is a collection of entities that are maintained in a sequence and can be modified by the addition of entities at one end of the sequence and the removal of entities from the other end of the sequence. By convention, the end of the sequence at which elements are added is called the back, tail, or rear of the queue, and the end at which elements are removed is called the head or front of the queue, analogously to the words used when people line up to wait for goods or services.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.

In computer science, Prim's algorithm is a greedy algorithm that finds a minimum spanning tree for a weighted undirected graph. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. The algorithm operates by building this tree one vertex at a time, from an arbitrary starting vertex, at each step adding the cheapest possible connection from the tree to another vertex.

Bucket sort, or bin sort, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. It is a distribution sort, a generalization of pigeonhole sort that allows multiple keys per bucket, and is a cousin of radix sort in the most-to-least significant digit flavor. Bucket sort can be implemented with comparisons and therefore can also be considered a comparison sort algorithm. The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
In computer science, a Fibonacci heap is a data structure for priority queue operations, consisting of a collection of heap-ordered trees. It has a better amortized running time than many other priority queue data structures including the binary heap and binomial heap. Michael L. Fredman and Robert E. Tarjan developed Fibonacci heaps in 1984 and published them in a scientific journal in 1987. Fibonacci heaps are named after the Fibonacci numbers, which are used in their running time analysis.
In computational complexity theory, the 3SUM problem asks if a given set of real numbers contains three elements that sum to zero. A generalized version, k-SUM, asks the same question on k elements, rather than simply 3. 3SUM can be easily solved in time, and matching lower bounds are known in some specialized models of computation.
In mathematics, in the areas of order theory and combinatorics, Dilworth's theorem characterizes the width of any finite partially ordered set in terms of a partition of the order into a minimum number of chains. It is named for the mathematician Robert P. Dilworth.
A van Emde Boas tree, also known as a vEB tree or van Emde Boas priority queue, is a tree data structure which implements an associative array with m-bit integer keys. It was invented by a team led by Dutch computer scientist Peter van Emde Boas in 1975. It performs all operations in O(log m) time, or equivalently in time, where is the largest element that can be stored in the tree. The parameter is not to be confused with the actual number of elements stored in the tree, by which the performance of other tree data-structures is often measured.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
An oriented matroid is a mathematical structure that abstracts the properties of directed graphs, vector arrangements over ordered fields, and hyperplane arrangements over ordered fields. In comparison, an ordinary matroid abstracts the dependence properties that are common both to graphs, which are not necessarily directed, and to arrangements of vectors over fields, which are not necessarily ordered.

In computer science, a queap is a priority queue data structure. The data structure allows insertions and deletions of arbitrary elements, as well as retrieval of the highest-priority element. Each deletion takes amortized time logarithmic in the number of items that have been in the structure for a longer time than the removed item. Insertions take constant amortized time.
In computer science, a monotone priority queue is a variant of the priority queue abstract data type in which the priorities of extracted items are required to form a monotonic sequence. That is, for a priority queue in which each successively extracted item is the one with the minimum priority, the minimum priority should be monotonically increasing. Conversely for a max-heap the maximum priority should be monotonically decreasing. The assumption of monotonicity arises naturally in several applications of priority queues, and can be used as a simplifying assumption to speed up certain types of priority queues.
A radix heap is a data structure for realizing the operations of a monotone priority queue. A set of elements to which a key is assigned can then be managed. The run time of the operations depends on the difference between the largest and smallest key or constant. The data structure consists mainly of a series of buckets, the size of which increases exponentially.





















