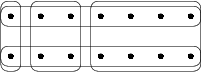
Given a set of elements {1, 2, …, n} (henceforth referred to as the universe, specifying all possible elements under consideration) and a collection, referred to as S, of a given m subsets whose union equals the universe, the set cover problem is to identify a smallest sub-collection of S whose union equals the universe.
For example, consider the universe, U = {1, 2, 3, 4, 5} and the collection of sets S = { {1, 2, 3}, {2, 4}, {3, 4}, {4, 5} }. In this example, m is equal to 4, as there are four subsets that comprise this collection. The union of S is equal to U. However, we can cover all elements with only two sets: { {1, 2, 3}, {4, 5} }, see picture, but not with only one set. Therefore, the solution to the set cover problem for this U and S has size 2.
More formally, given a universe and a family of subsets of , a set cover is a subfamily of sets whose union is .
In the set cover decision problem, the input is a pair and an integer ; the question is whether there is a set cover of size or less.
In the set cover optimization problem, the input is a pair , and the task is to find a set cover that uses the fewest sets.
In the weighted set cover problem, each set is assigned a positive weight (representing its cost), and the goal is to find a set cover with a smallest weight. The usual (unweighted) set cover corresponds to all sets having a weight of 1.
In the fractional set cover problem, it is allowed to select fractions of sets, rather than entire sets. A fractional set cover is an assignment of a fraction (a number in [0,1]) to each set in , such that for each element x in the universe, the sum of fractions of sets that contain x is at least 1. The goal is to find a fractional set cover in which the sum of fractions is as small as possible. Note that a (usual) set cover is equivalent to a fractional set cover in which all fractions are either 0 or 1; therefore, the size of the smallest fractional cover is at most the size of the smallest cover, but may be smaller. For example, consider the universe U = {1, 2, 3} and the collection of sets S = { {1, 2}, {2, 3}, {3, 1} }. The smallest set cover has a size of 2, e.g. { {1, 2}, {2, 3} }. But there is a fractional set cover of size 1.5, in which a 0.5 fraction of each set is taken.
In the capacitated set cover problem, each set is associated with a capacity which denotes the number of elements it can supply coverage. The goal is to determine the optimal way to select sets such that each element receives the coverage it requires.
For a more compact representation of the covering constraint, one can define an incidence matrix, where each row corresponds to an element and each column corresponds to a set, and if element e is in set s, and otherwise. Then, the covering constraint can be written as .
Weighted set cover is described by a program identical to the one given above, except that the objective function to minimize is , where is the weight of set .
Fractional set cover is described by a program identical to the one given above, except that can be non-integer, so the last constraint is replaced by .
This linear program belongs to the more general class of LPs for covering problems, as all the coefficients in the objective function and both sides of the constraints are non-negative. The integrality gap of the ILP is at most (where is the size of the universe). It has been shown that its relaxation indeed gives a factor-approximation algorithm for the minimum set cover problem.[4] See randomized rounding#setcover for a detailed explanation.
Hitting set formulation
The set cover problem is equivalent to the hitting set problem. A subset of is called a hitting set when for all (i.e., intersects or “hits” all subsets in ). The hitting set problem is to find a minimum hitting set for a given and .
To show that the problems are equivalent, for a universe of size and collection of sets of size , construct and . Then a set cover of is equivalent to a hitting set of where , and vice versa.
This equivalence can also be visualized by representing the problem as a bipartite graph of vertices, with vertices on the left representing elements of , and vertices on the right representing elements of , and edges representing set membership (i.e., there is an edge between the -th vertex on the left and the -th vertex of the right iff.). Then a set cover is a subset of right vertices such that each left vertex is adjacent to at least one member of , while a hitting set is a subset of left vertices such that each right vertex is adjacent to at least one member of . These definitions are exactly the same except that left and right are swapped. But there is nothing special about the sides in the bipartite graph; we could have put the elements of on the right side, and the elements of on the left side, creating a graph that is a mirror image of the one described above. This shows that set covers in the original graph are equivalent to hitting sets in the mirrored graph, and vice versa.
In the field of computational geometry, a hitting set for a collection of geometrical objects is also called a stabbing set or piercing set.[5]
Greedy algorithm
There is a greedy algorithm for polynomial time approximation of set covering that chooses sets according to one rule: at each stage, choose the set that contains the largest number of uncovered elements. This method can be implemented in time linear in the sum of sizes of the input sets, using a bucket queue to prioritize the sets.[6] It achieves an approximation ratio of , where is the size of the set to be covered.[7][8][9] In other words, it finds a covering that may be times as large as the minimum one, where is the -th harmonic number:
This greedy algorithm actually achieves an approximation ratio of where is the maximum cardinality set of . For dense instances, however, there exists a -approximation algorithm for every .[10]
There is a standard example on which the greedy algorithm achieves an approximation ratio of . The universe consists of elements. The set system consists of pairwise disjoint sets with sizes respectively, as well as two additional disjoint sets , each of which contains half of the elements from each . On this input, the greedy algorithm takes the sets , in that order, while the optimal solution consists only of and . An example of such an input for is pictured on the right.
Inapproximability results show that the greedy algorithm is essentially the best-possible polynomial time approximation algorithm for set cover up to lower order terms (see Inapproximability results below), under plausible complexity assumptions. A tighter analysis for the greedy algorithm shows that the approximation ratio is exactly .[11]
Low-frequency systems
If each element occurs in at most f sets, then a solution can be found in polynomial time that approximates the optimum to within a factor of f using LP relaxation.
If the constraint is replaced by for all S in in the integer linear program shown above, then it becomes a (non-integer) linear program L. The algorithm can be described as follows:
Find an optimal solution O for the program L using some polynomial-time method of solving linear programs.
Pick all sets S for which the corresponding variable xS has value at least 1/f in the solution O.[12]
Inapproximability results
When refers to the size of the universe, Lund & Yannakakis (1994) showed that set covering cannot be approximated in polynomial time to within a factor of , unless NP has quasi-polynomial time algorithms. Feige (1998) improved this lower bound to under the same assumptions, which essentially matches the approximation ratio achieved by the greedy algorithm. Raz & Safra (1997) established a lower bound of , where is a certain constant, under the weaker assumption that PNP. A similar result with a higher value of was recently proved by Alon, Moshkovitz & Safra (2006). Dinur & Steurer (2013) showed optimal inapproximability by proving that it cannot be approximated to unless PNP.
Trevisan (2001) proves that set cover instances with sets of size at most cannot be approximated to a factor better than unless PNP, thus making the approximation of of the greedy algorithm essentially tight in this case.
Weighted set cover
The greedy algorithm for the weighted set cover problem[7] directly generalizes the unweighted version. Given a universe and a family of subsets of , where each set is assigned a non-negative weight (cost), the algorithm maintains the subset of elements that are not yet covered. Initially, all elements of are uncovered. At each iteration, the algorithm selects a set that minimizes the ratio between its weight and the number of currently uncovered elements it contains. The selected set is added to the solution, and all elements contained in it are marked as covered. This process is repeated until all elements of are covered. The greedy algorithm is known to produce a solution whose total weight is at most a factor of times the optimal solution, where denotes the -th harmonic number and .
For low frequency systems, where every element is contained in at most sets, the deterministic LP rounding algorithm gets an -approximation.[13] It starts with the optimal solution to the linear programming relaxation of the problem stated above. Sets whose fractional value exceeds are selected to form an integer solution.
The primal-dual algorithm for the set cover problem is an iterative method that constructs feasible solutions to both the primal and dual linear programs simultaneously. Starting with all dual variables set to zero, the algorithm repeatedly increases the dual variables corresponding to uncovered elements uniformly, until some set’s dual constraint becomes tight (i.e., the sum of the dual variables for elements in the set equals its cost). This tight set is then added to the primal solution, covering the corresponding elements. The process continues until all elements are covered. The algorithm guarantees an approximation ratio of , where is the maximum number of sets that any element belongs to.[14]
Randomized rounding is an approximation technique for the weighted set cover problem that uses the solution of the linear programming relaxation. Let be an optimal fractional solution to the LP relaxation. Each set is independently included in the cover with probability . By linearity of expectation, the expected cost of the chosen sets equals the LP optimum. The probability that any element remains uncovered can be made arbitrarily small by scaling probabilities or repeating the rounding. Using standard concentration bounds, this produces a feasible set cover whose expected cost is within an factor of the optimal solution, where is the size of the universe.
Geometric set cover is a special case of Set Cover when the universe is a set of points in and the sets are induced by the intersection of the universe and geometric shapes (e.g., disks, rectangles).
Set packing is the problem of selecting the maximum number of sets that are pairwise disjoint.
Dominating set is the problem of selecting a set of vertices (the dominating set) in a graph such that all other vertices are adjacent to at least one vertex in the dominating set. The Dominating set problem was shown to be NP complete through a reduction from Set cover.
Exact cover problem is to choose a set cover with no element included in more than one covering set.
Red-blue set cover is a generalization of Set Cover where elements in the universe are colored either red or blue, and the goal is to select a sub-collection of the given sets that covers all of the blue elements while covering the minimum number of red elements.[17]
Set-cover abduction is a related problem where, given a set of observations and a set of hypotheses, the goal is to select a subset of the hypotheses whose effects include all of the observations.
Monotone dualization is a computational problem equivalent to either listing all minimal hitting sets or listing all minimal set covers of a given set family.[18]
↑Information., Sandia National Laboratories. United States. Department of Energy. United States. Department of Energy. Office of Scientific and Technical (1999). On the Red-Blue Set Cover Problem. United States. Dept. of Energy. OCLC68396743.
Raz, Ran; Safra, Shmuel (1997), "A sub-constant error-probability low-degree test, and a sub-constant error-probability PCP characterization of NP", STOC '97: Proceedings of the twenty-ninth annual ACM symposium on Theory of computing, ACM, pp.475–484, ISBN978-0-89791-888-6 .
Dinur, Irit; Steurer, David (2013), "Analytical approach to parallel repetition", STOC '14: Proceedings of the forty-sixth annual ACM symposium on Theory of computing, ACM, pp.624–633.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.