Related Research Articles

The genetic code is the set of rules used by living cells to translate information encoded within genetic material into proteins. Translation is accomplished by the ribosome, which links proteinogenic amino acids in an order specified by messenger RNA (mRNA), using transfer RNA (tRNA) molecules to carry amino acids and to read the mRNA three nucleotides at a time. The genetic code is highly similar among all organisms and can be expressed in a simple table with 64 entries.

In biology, a mutation is an alteration in the nucleotide sequence of the genome of an organism, virus, or extrachromosomal DNA. Viral genomes contain either DNA or RNA. Mutations result from errors during DNA or viral replication, mitosis, or meiosis or other types of damage to DNA, which then may undergo error-prone repair, cause an error during other forms of repair, or cause an error during replication. Mutations may also result from insertion or deletion of segments of DNA due to mobile genetic elements.

In molecular biology, a stop codon is a codon that signals the termination of the translation process of the current protein. Most codons in messenger RNA correspond to the addition of an amino acid to a growing polypeptide chain, which may ultimately become a protein; stop codons signal the termination of this process by binding release factors, which cause the ribosomal subunits to disassociate, releasing the amino acid chain.

In genetics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome. Although certain definitions require the substitution to be present in a sufficiently large fraction of the population, many publications do not apply such a frequency threshold.
Site-directed mutagenesis is a molecular biology method that is used to make specific and intentional changes to the DNA sequence of a gene and any gene products. Also called site-specific mutagenesis or oligonucleotide-directed mutagenesis, it is used for investigating the structure and biological activity of DNA, RNA, and protein molecules, and for protein engineering.

A frameshift mutation is a genetic mutation caused by indels of a number of nucleotides in a DNA sequence that is not divisible by three. Due to the triplet nature of gene expression by codons, the insertion or deletion can change the reading frame, resulting in a completely different translation from the original. The earlier in the sequence the deletion or insertion occurs, the more altered the protein. A frameshift mutation is not the same as a single-nucleotide polymorphism in which a nucleotide is replaced, rather than inserted or deleted. A frameshift mutation will in general cause the reading of the codons after the mutation to code for different amino acids. The frameshift mutation will also alter the first stop codon encountered in the sequence. The polypeptide being created could be abnormally short or abnormally long, and will most likely not be functional.

A point mutation or substitution is a genetic mutation where a single nucleotide base is changed, inserted or deleted from a DNA or RNA sequence of an organism's genome. Point mutations have a variety of effects on the downstream protein product—consequences that are moderately predictable based upon the specifics of the mutation. These consequences can range from no effect to deleterious effects, with regard to protein production, composition, and function.
An aminoacyl-tRNA synthetase, also called tRNA-ligase, is an enzyme that attaches the appropriate amino acid onto its corresponding tRNA. It does so by catalyzing the transesterification of a specific cognate amino acid or its precursor to one of all its compatible cognate tRNAs to form an aminoacyl-tRNA. In humans, the 20 different types of aa-tRNA are made by the 20 different aminoacyl-tRNA synthetases, one for each amino acid of the genetic code.

Silent mutations are mutations in DNA that do not have an observable effect on the organism's phenotype. They are a specific type of neutral mutation. The phrase silent mutation is often used interchangeably with the phrase synonymous mutation; however, synonymous mutations are not always silent, nor vice versa. Synonymous mutations can affect transcription, splicing, mRNA transport, and translation, any of which could alter phenotype, rendering the synonymous mutation non-silent. The substrate specificity of the tRNA to the rare codon can affect the timing of translation, and in turn the co-translational folding of the protein. This is reflected in the codon usage bias that is observed in many species. Mutations that cause the altered codon to produce an amino acid with similar functionality are often classified as silent; if the properties of the amino acid are conserved, this mutation does not usually significantly affect protein function.
In genetics, a missense mutation is a point mutation in which a single nucleotide change results in a codon that codes for a different amino acid. It is a type of nonsynonymous substitution.
A synonymous substitution is the evolutionary substitution of one base for another in an exon of a gene coding for a protein, such that the produced amino acid sequence is not modified. This is possible because the genetic code is "degenerate", meaning that some amino acids are coded for by more than one three-base-pair codon; since some of the codons for a given amino acid differ by just one base pair from others coding for the same amino acid, a mutation that replaces the "normal" base by one of the alternatives will result in incorporation of the same amino acid into the growing polypeptide chain when the gene is translated. Synonymous substitutions and mutations affecting noncoding DNA are often considered silent mutations; however, it is not always the case that the mutation is silent.

DNA polymerase II is a prokaryotic DNA-Dependent DNA polymerase encoded by the PolB gene.

ASL is an enzyme that catalyzes the reversible breakdown of argininosuccinate (ASA) producing the amino acid arginine and dicarboxylic acid fumarate. Located in liver cytosol, ASL is the fourth enzyme of the urea cycle and involved in the biosynthesis of arginine in all species and the production of urea in ureotelic species. Mutations in ASL, resulting low activity of the enzyme, increase levels of urea in the body and result in various side effects.

Directed evolution (DE) is a method used in protein engineering that mimics the process of natural selection to steer proteins or nucleic acids toward a user-defined goal. It consists of subjecting a gene to iterative rounds of mutagenesis, selection and amplification. It can be performed in vivo, or in vitro. Directed evolution is used both for protein engineering as an alternative to rationally designing modified proteins, as well as for experimental evolution studies of fundamental evolutionary principles in a controlled, laboratory environment.
HindIII (pronounced "Hin D Three") is a type II site-specific deoxyribonuclease restriction enzyme isolated from Haemophilus influenzae that cleaves the DNA palindromic sequence AAGCTT in the presence of the cofactor Mg2+ via hydrolysis.
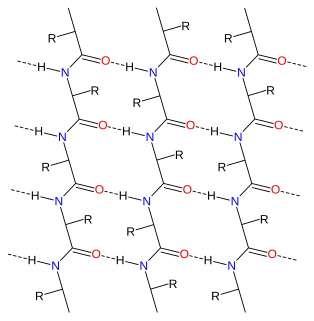
Alpha sheet is an atypical secondary structure in proteins, first proposed by Linus Pauling and Robert Corey in 1951. The hydrogen bonding pattern in an alpha sheet is similar to that of a beta sheet, but the orientation of the carbonyl and amino groups in the peptide bond units is distinctive; in a single strand, all the carbonyl groups are oriented in the same direction on one side of the pleat, and all the amino groups are oriented in the same direction on the opposite side of the sheet. Thus the alpha sheet accumulates an inherent separation of electrostatic charge, with one edge of the sheet exposing negatively charged carbonyl groups and the opposite edge exposing positively charged amino groups. Unlike the alpha helix and beta sheet, the alpha sheet configuration does not require all component amino acid residues to lie within a single region of dihedral angles; instead, the alpha sheet contains residues of alternating dihedrals in the traditional right-handed (αR) and left-handed (αL) helical regions of Ramachandran space. Although the alpha sheet is only rarely observed in natural protein structures, it has been speculated to play a role in amyloid disease and it was found to be a stable form for amyloidogenic proteins in molecular dynamics simulations. Alpha sheets have also been observed in X-ray crystallography structures of designed peptides.
In enzymology, an alpha-tubulin N-acetyltransferase is an enzyme which is encoded by the ATAT1 gene.

Y+L amino acid transporter 1 is a protein that in humans is encoded by the SLC7A7 gene.

In molecular biology, mutagenesis is an important laboratory technique whereby DNA mutations are deliberately engineered to produce libraries of mutant genes, proteins, strains of bacteria, or other genetically modified organisms. The various constituents of a gene, as well as its regulatory elements and its gene products, may be mutated so that the functioning of a genetic locus, process, or product can be examined in detail. The mutation may produce mutant proteins with interesting properties or enhanced or novel functions that may be of commercial use. Mutant strains may also be produced that have practical application or allow the molecular basis of a particular cell function to be investigated.

In evolutionary biology, sequence space is a way of representing all possible sequences. The sequence space has one dimension per amino acid or nucleotide in the sequence leading to highly dimensional spaces.
References
- ↑ Wang, Qing; Chaerkady, Raghothama; Wu, Jian; Hwang, Hee Jung; Papadopoulos, Nick; Kopelovich, Levy; Maitra, Anirban; Matthaei, Hanno; et al. (2011). "Mutant proteins as cancer-specific biomarkers". Proceedings of the National Academy of Sciences. 108 (6): 2444–9. Bibcode:2011PNAS..108.2444W. doi: 10.1073/pnas.1019203108 . PMC 3038743 . PMID 21248225.
| | This protein-related article is a stub. You can help Wikipedia by expanding it. |