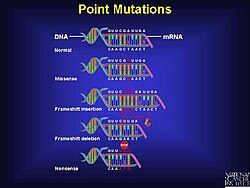
Different types of indel mutation. Panel C is simply a deletion and not a frameshift mutation.
A frameshift mutation (also called a framing error or a reading frame shift) is a genetic mutation caused by indels (insertions or deletions) of a number of nucleotides in a DNA sequence that is not divisible by three. Due to the triplet nature of gene expression by codons, the insertion or deletion can change the reading frame (the grouping of the codons), resulting in a completely different translation from the original. The earlier in the sequence the deletion or insertion occurs, the more altered the protein.[1] A frameshift mutation is not the same as a single-nucleotide polymorphism in which a nucleotide is replaced, rather than inserted or deleted. A frameshift mutation will in general cause the reading of the codons after the mutation to code for different amino acids. The frameshift mutation will also alter the first stop codon ("UAA", "UGA" or "UAG") encountered in the sequence. The polypeptide being created could be abnormally short or abnormally long, and will most likely not be functional.[2]
Frameshift mutations are apparent in severe genetic diseases such as Tay–Sachs disease; they increase susceptibility to certain cancers and classes of familial hypercholesterolaemia; in 1997,[3] a frameshift mutation was linked to resistance to infection by the HIV retrovirus. Frameshift mutations have been proposed as a source of biological novelty, as with the alleged creation of nylonase, however, this interpretation is controversial. A study by Negoro et al. (2006)[4] found that a frameshift mutation was unlikely to have been the cause and that rather a two amino acid substitution in the active site of an ancestral esterase resulted in nylonase.
Background
The information contained in DNA determines protein function in the cells of all organisms. Transcription and translation allow this information to be communicated into making proteins. However, an error in reading this communication can cause protein function to be incorrect and eventually cause disease even as the cell incorporates a variety of corrective measures.Genetic information is conveyed by DNA for protein synthesis within cells. Misinterpretation can lead to faulty function and disease, despite cellular correction mechanisms.
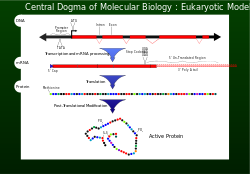
In 1956 Francis Crick described the flow of genetic information from DNA to a specific amino acid arrangement for making a protein as the central dogma.[1] For a cell to properly function, proteins are required to be produced accurately for structural and for catalytic activities. An incorrectly made protein can have detrimental effects on cell viability and in most cases cause the higher organism to become unhealthy by abnormal cellular functions. To ensure that the genome successfully passes the information on, proofreading mechanisms such as exonucleases and mismatch repair systems are incorporated in DNA replication.[1]
After DNA replication, the reading of a selected section of genetic information is accomplished by transcription.[1] Nucleotides containing the genetic information are now on a single strand messenger template called mRNA. The mRNA is incorporated with a subunit of the ribosome and interacts with an rRNA. The genetic information carried in the codons of the mRNA are now read (decoded) by anticodons of the tRNA. As each codon (triplet) is read, amino acids are being joined until a stop codon (UAG, UGA or UAA) is reached. At this point the polypeptide (protein) has been synthesised and is released.[1] For every 1000 amino acid incorporated into the protein, no more than one is incorrect. This fidelity of codon recognition, maintaining the importance of the proper reading frame, is accomplished by proper base pairing at the ribosome A site, GTP hydrolysis activity of EF-Tu a form of kinetic stability, and a proofreading mechanism as EF-Tu is released.[1]
Frameshifting may also occur during prophase translation, producing different proteins from overlapping open reading frames, such as the gag-pol-env retroviral proteins. This is fairly common in viruses and also occurs in bacteria and yeast (Farabaugh, 1996). Reverse transcriptase, as opposed to RNA Polymerase II, is thought to be a stronger cause of the occurrence of frameshift mutations. In experiments only 3–13% of all frameshift mutations occurred because of RNA Polymerase II. In prokaryotes the error rate inducing frameshift mutations is only somewhere in the range of .0001 and .00001.[5]
There are several biological processes that help to prevent frameshift mutations. Reverse mutations occur which change the mutated sequence back to the original wild type sequence. Another possibility for mutation correction is the use of a suppressor mutation. This offsets the effect of the original mutation by creating a secondary mutation, shifting the sequence to allow for the correct amino acids to be read. Guide RNA can also be used to insert or delete Uridine into the mRNA after transcription, this allows for the correct reading frame.[1]
A codon is a set of three nucleotides, a triplet that codes for a certain amino acid. The first codon establishes the reading frame, whereby a new codon begins. A protein's amino acid backbone sequence is defined by contiguous triplets.[6] Codons are key to translation of genetic information for the synthesis of proteins. The reading frame is set when translating the mRNA begins and is maintained as it reads one triplet to the next. The reading of the genetic code is subject to three rules the monitor codons in mRNA. First, codons are read in a 5' to 3' direction. Second, codons are nonoverlapping and the message has no gaps. The last rule, as stated above, that the message is translated in a fixed reading frame.[1]
Example of different types of point mutations
Mechanism
Frameshift mutations can occur randomly or be caused by an external stimulus. The detection of frameshift mutations can occur via several different methods. Frameshifts are just one type of mutation that can lead to incomplete or incorrect proteins, but they account for a significant percentage of errors in DNA. In an unaltered gene, codons (triplets of nucleotides) are sequentially interpreted, with each codon encoding a specific amino acid. This is known as the standard reading frame. However, in cases of frameshift mutations, an extra nucleotide (or more) is inserted into the DNA sequence, disrupting the typical reading frame and causing a shift in the sequence.
This insertion prompts a shift in the reading frame due to the triplet nature of the genetic code. For instance, the addition of an extra "A" leads to a sequence shift, triggering the reading of an entirely different set of codons. This deviation in genetic information causes the ribosome, which reads the mRNA for protein synthesis, to misinterpret the genetic data. Consequently, an entirely different series of amino acids is generated, resulting in the generation of an altered protein sequence. In most instances, the new reading frame results in an early encounter with a stop codon, leading to the formation of a shortened and usually inactive protein. This form of mutation is termed an early stop codon or a nonsense mutation.
This is a genetic mutation at the level of nucleotide bases. Why and how frameshift mutations occur are continually being sought after. An environmental study, specifically the production of UV-induced frameshift mutations by DNA polymerases deficient in 3′ → 5′ exonuclease activity was done. The normal sequence 5′ GTC GTT TTA CAA 3′ was changed to GTC GTT T TTA CAA (MIDT) of GTC GTT C TTA CAA (MIDC) to study frameshifts. E. coli pol I Kf and T7 DNA polymerase mutant enzymes devoid of 3′ → 5′ exonuclease activity produce UV-induced revertants at higher frequency than did their exonuclease proficient counterparts. The data indicates that loss of proofreading activity increases the frequency of UV-induced frameshifts.[7]
Detection
Fluorescence
The effects of neighboring bases and secondary structure to detect the frequency of frameshift mutations has been investigated in depth using fluorescence. Fluorescently tagged DNA, by means of base analogues, permits one to study the local changes of a DNA sequence.[8] Studies on the effects of the length of the primer strand reveal that an equilibrium mixture of four hybridization conformations was observed when template bases looped-out as a bulge, i.e. a structure flanked on both sides by duplex DNA. In contrast, a double-loop structure with an unusual unstacked DNA conformation at its downstream edge was observed when the extruded bases were positioned at the primer–template junction, showing that misalignments can be modified by neighboring DNA secondary structure.[9]
Sequencing
A deletion mutation alters every codon following it, and can make protein synthesis stop prematurely by forming a stop codon.
Sanger sequencing and pyrosequencing are two methods that have been used to detect frameshift mutations, however, it is likely that data generated will not be of the highest quality. Even still, 1.96 million indels have been identified through Sanger sequencing that do not overlap with other databases. When a frameshift mutation is observed it is compared against the Human Genome Mutation Database (HGMD) to determine if the mutation has a damaging effect. This is done by looking at four features. First, the ratio between the affected and conserved DNA, second the location of the mutation relative to the transcript, third the ratio of conserved and affected amino acids and finally the distance of the indel to the end of the exon.[10]
Massively Parallel Sequencing is a newer method that can be used to detect mutations. Using this method, up to 17 gigabases can be sequenced at once, as opposed to limited ranges for Sanger sequencing of only about 1 kilobase. Several technologies are available to perform this test and it is being looked at to be used in clinical applications.[11] When testing for different carcinomas, current methods only allow for looking at one gene at a time. Massively Parallel Sequencing can test for a variety of cancer causing mutations at once as opposed to several specific tests.[12] An experiment to determine the accuracy of this newer sequencing method tested for 21 genes and had no false positive calls for frameshift mutations.[13]
Diagnosis
A US patent (5,958,684) in 1999 by Leeuwen, details the methods and reagents for diagnosis of diseases caused by or associated with a gene having a somatic mutation giving rise to a frameshift mutation. The methods include providing a tissue or fluid sample and conducting gene analysis for frameshift mutation or a protein from this type of mutation. The nucleotide sequence of the suspected gene is provided from published gene sequences or from cloning and sequencing of the suspect gene. The amino acid sequence encoded by the gene is then predicted.[14] NA Sequencing: Sanger sequencing or Next-Generation Sequencing (NGS) can be used to directly sequence the DNA and identify insertions or deletions.Polymerase Chain Reaction (PCR): PCR can be used to amplify the specific region containing the mutation for subsequent analysis.Multiplex Ligation-dependent Probe Amplification (MLPA): MLPA is a technique used to detect copy number variations and small insertions or deletions.Comparative Genomic Hybridization (CGH): CGH is used to detect chromosomal imbalances, which may include large insertions or deletions.
Frequency
Despite the rules that govern the genetic code and the various mechanisms present in a cell to ensure the correct transfer of genetic information during the process of DNA replication as well as during translation, mutations do occur; frameshift mutation is not the only type. There are at least two other types of recognized point mutations, specifically missense mutation and nonsense mutation.[1] A frameshift mutation can drastically change the coding capacity (genetic information) of the message.[1] Small insertions or deletions (those less than 20 base pairs) make up 24% of mutations that manifest in currently recognized genetic disease.[10]
Frameshift mutations are found to be more common in repeat regions of DNA. A reason for this is because of slipping of the polymerase enzyme in repeat regions, allowing for mutations to enter the sequence.[15]Experiments can be run to determine the frequency of the frameshift mutation by adding or removing a pre-set number of nucleotides. Experiments have been run by adding four basepairs, called the +4 experiments, but a team from Emory University looked at the difference in frequency of the mutation by both adding and deleting a base pair. It was shown that there was no difference in the frequency between the addition and deletion of a base pair. There is however, a difference in the result of the protein.[15]
Huntington's disease is one of the nine codon reiteration disorders caused by polyglutamine expansion mutations that include spino-cerebellar ataxia (SCA) 1, 2, 6, 7 and 3, spinobulbar muscular atrophy and dentatorubal-pallidoluysianatrophy. There may be a link between diseases caused by polyglutamine and polyalanine expansion mutations, as frame shifting of the original SCA3 gene product encoding CAG/polyglutamines to GCA/polyalanines. Ribosomal slippage during translation of the SCA3 protein has been proposed as the mechanism resulting in shifting from the polyglutamine to the polyalanine-encoding frame. A dinucleotide deletion or single nucleotide insertion within the polyglutamine tract of huntingtin exon 1 would shift the CAG, polyglutamineen coding frame by +1 (+1 frame shift) to the GCA, polyalanine-encoding frame and introduce a novel epitope to the C terminus of Htt exon 1 (APAAAPAATRPGCG).[16]
Diseases
Several diseases have frameshift mutations as at least part of the cause. Knowing prevalent mutations can also aid in the diagnosis of the disease. Currently there are attempts to use frameshift mutations beneficially in the treatment of diseases, changing the reading frame of the amino acids.
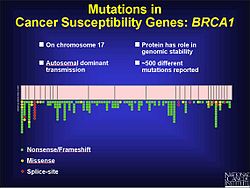
Frequency of mutations on BRCA1 gene on chromosome 17Frequency of mutations on BRCA2 gene on chromosome 13
Frameshift mutations are known to be a factor in colorectal cancer as well as other cancers with microsatellite instability. As stated previously, frameshift mutations are more likely to occur in a region of repeat sequence. When DNA mismatch repair does not fix the addition or deletion of bases, these mutations are more likely to be pathogenic. This may be in part because the tumor is not told to stop growing. Experiments in yeast and bacteria help to show characteristics of microsatellites that may contribute to defective DNA mismatch repair. These include the length of the microsatellite, the makeup of the genetic material and how pure the repeats are. Based on experimental results longer microsatellites have a higher rate of frameshift mutations. The flanking DNA can also contribute to frameshift mutations.[17] In prostate cancer a frameshift mutation changes the open reading frame (ORF) and prevents apoptosis from occurring. This leads to an unregulated growth of the tumor. While there are environmental factors that contribute to the progression of prostate cancer, there is also a genetic component. During testing of coding regions to identify mutations, 116 genetic variants were discovered, including 61 frameshift mutations.[18] There are over 500 mutations on chromosome 17 that seem to play a role in the development of breast and ovarian cancer in the BRCA1 gene, many of which are frameshift.[19]
Crohn's disease
Crohn's disease has an association with the NOD2 gene. The mutation is an insertion of a Cytosine at position 3020. This leads to a premature stop codon, shortening the protein that is supposed to be transcribed. When the protein is able to form normally, it responds to bacterial liposaccharides, where the 3020insC mutation prevents the protein from being responsive.[20]
Cystic fibrosis
Cystic fibrosis (CF) is a disease based on mutations in the CF transmembrane conductance regulator (CFTR) gene. There are over 1500 mutations identified, but not all cause the disease.[21] Most cases of cystic fibrosis are a result of the ∆F508 mutation, which deletes the entire amino acid. Two frameshift mutations are of interest in diagnosing CF, CF1213delT and CF1154-insTC. Both of these mutations commonly occur in tandem with at least one other mutation. They both lead to a small decrease in the function of the lungs and occur in about 1% of patients tested. These mutations were identified through Sanger sequencing.[22]
CCR5 is one of the cell entry co-factors associated with HIV, most frequently involved with nonsyncytium-inducing strains, is most apparent in HIV patients as opposed to AIDS patients. A 32 base pair deletion in CCR5 has been identified as a mutation that negates the likelihood of an HIV infection. This region on the open reading frame ORF contains a frameshift mutation leading to a premature stop codon. This leads to the loss of the HIV-coreceptor function in vitro. CCR5-1 is considered the wild type and CCR5-2 is considered to be the mutant allele. Those with a heterozygous mutation for the CCR5 were less susceptible to the development of HIV. In a study, despite high exposure to the HIV virus, there was no one homozygous for the CCR5 mutation that tested positive for HIV.[3]
Tay–Sachs disease
Tay–Sachs disease is a fatal disease affecting the central nervous system. It is most frequently found in infants and small children. Disease progression begins in the womb but symptoms do not appear until approximately 6 months of age. There is no cure for the disease.[23] Mutations in the β-hexosaminidase A (Hex A) gene are known to affect the onset of Tay-Sachs, with 78 mutations of different types being described, 67 of which are known to cause disease. Most of the mutations observed (65/78) are single base substitutions or SNPs, 11 deletions, 1 large and 10 small, and 2 insertions. 8 of the observed mutations are frameshift, 6 deletions and 2 insertions. A 4 base pair insertion in exon 11 is observed in 80% of Tay-Sachs disease presence in the Ashkenazi Jewish population. The frameshift mutations lead to an early stop codon which is known to play a role in the disease in infants. Delayed onset disease appears to be caused by 4 different mutations, one being a 3 base pair deletion.[24]
Smith–Magenis syndrome
Smith–Magenis syndrome (SMS) is a complex syndrome involving intellectual disabilities, sleep disturbance, behavioural problems, and a variety of craniofacial, skeletal, and visceral anomalies. The majority of SMS cases harbor an ~3.5 Mb common deletion that encompasses the retinoic acid induced-1 (RAI1) gene. Other cases illustrate variability in the SMS phenotype not previously shown for RAI1 mutation, including hearing loss, self-abusive behaviours, and mild global delays. Sequencing of RAI1 revealed mutation of a heptamericC-tract (CCCCCCC) in exon 3 resulting in frameshift mutations. Of the seven reported frameshift mutations occurring in poly C-tracts in RAI1, four cases (~57%) occur at this heptameric C-tract. The results indicate that this heptameric C-tract is a preferential recombination hotspot insertion/deletions (SNindels) and therefore a primary target for analysis in patients suspected for mutations in RAI1.[25]
Hypertrophic cardiomyopathy
Hypertrophic cardiomyopathy is the most common cause of sudden death in young people, including trained athletes, and is caused by mutations in genes encoding proteins of the cardiac sarcomere. Mutations in the Troponin C gene (TNNC1) are a rare genetic cause of hypertrophic cardiomyopathy. A recent study has indicated that a frameshift mutation (c.363dupG or p.Gln122AlafsX30) in Troponin C was the cause of hypertrophic cardiomyopathy (and sudden cardiac death) in a 19-year-old male.[26]
Cures
Finding a cure for the diseases caused by frameshift mutations is rare. Research into this is ongoing. One example is a primary immunodeficiency (PID), an inherited condition which can lead to an increase in infections. There are 120 genes and 150 mutations that play a role in primary immunodeficiencies. The standard treatment is currently gene therapy, but this is a highly risky treatment and can often lead to other diseases, such as leukemia. Gene therapy procedures include modifying the zinc fringer nuclease fusion protein, cleaving both ends of the mutation, which in turn removes it from the sequence. Antisense-oligonucleotide mediated exon skipping is another possibility for Duchenne muscular dystrophy. This process allows for passing over the mutation so that the rest of the sequence remains in frame and the function of the protein stays intact. This, however, does not cure the disease, just treats symptoms, and is only practical in structural proteins or other repetitive genes. A third form of repair is revertant mosaicism, which is naturally occurring by creating a reverse mutation or a mutation at a second site that corrects the reading frame. This reversion may happen by intragenic recombination, mitotic gene conversion, second site DNA slipping or site-specific reversion. This is possible in several diseases, such as X-linked severe combined immunodeficiency (SCID), Wiskott–Aldrich syndrome, and Bloom syndrome. There are no drugs or other pharmacogenomic methods that help with PIDs.[27]
A European patent (EP1369126A1) in 2003 by Bork records a method used for prevention of cancers and for the curative treatment of cancers and precancers such as DNA-mismatch repair deficient (MMR) sporadic tumours and HNPCC associated tumours. The idea is to use immunotherapy with combinatorial mixtures of tumour-specific frameshift mutation-derived peptides to elicit a cytotoxic T-cell response specifically directed against tumour cells.[28]
↑ Xu, XiaoLin; Zhu, KaiChang; Liu, Feng; Wang, Yue; Shen, JianGuo; Jin, Jizhong; Wang, Zhong; Chen, Lin; Li, Jiadong; Xu, Min (May 2013). "Identification of somatic mutations in human prostate cancer by RNA-Seq". Gene. 519 (2): 343–7. doi:10.1016/j.gene.2013.01.046. PMID23434521.
↑ "Cancer Genomics". National Cancer Institute at the National Institute of Health. Archived from the original on 18 March 2013. Retrieved 24 March 2013.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.