Cells were discovered by Robert Hooke in 1665, who named them after their resemblance to cells in a monastery. Cell theory, developed in 1839 by Matthias Jakob Schleiden and Theodor Schwann, states that all organisms are composed of one or more cells, that cells are the fundamental unit of structure and function in all organisms, and that all cells come from pre-existing cells.
Most prokaryotes are the smallest of all organisms, ranging from 0.5 to 2.0μm in diameter.[11] The largest bacterium known, Thiomargarita magnifica, is visible to the naked eye with an average length of 1cm, but can be as much as 2cm[12][13]
Bacteria are enclosed in a cell envelope, that protects the interior from the exterior.[14] It generally consists of a plasma membrane covered by a cell wall which, for some bacteria, is covered by a third gelatinous layer called a bacterial capsule. The capsule may be polysaccharide as in pneumococci, meningococci or polypeptide as Bacillus anthracis or hyaluronic acid as in streptococci. Mycoplasma only possess the cell membrane.[15] The cell envelope gives rigidity to the cell and separates the interior of the cell from its environment, serving as a protective mechanical and chemical filter.[16] The cell wall consists of peptidoglycan and acts as an additional barrier against exterior forces.[17][16] The cell wall acts to protect the cell mechanically and chemically from its environment, and is an additional layer of protection to the cell membrane. It also prevents the cell from expanding and bursting (cytolysis) from osmotic pressure due to a hypotonic environment.[18]
Cell-surface appendages can include flagella, and pili, protein structures that facilitate movement and communication between cells.[33] The flagellum stretches from the cytoplasm through the cell membrane and extrudes through the cell wall.[34]Fimbriae are short attachment pili, the other type of pilus is the longer conjugative type.[35] Fimbriae are formed of an antigenic protein called pilin, and are responsible for the attachment of bacteria to specific receptors on host cells.[36]
Archaea are enclosed in a cell envelope consisting of a plasma membrane and a cell wall. An exception to this is the Thermoplasma that only has the cell membrane.[15] The cell membranes of archaea are unique, consisting of ether-linked lipids. The prokaryotic cytoskeleton has homologues of eukaryotic actin and tubulin.[26] A unique form of metabolism in the archaean is methanogenesis. Their cell-surface appendage equivalent of the flagella is the differently structured and unique archaellum.[37][35] The DNA is contained in a circular chromosome in direct contact with the cytoplasm, in a region known as the nucleoid. Ribosomes are also found freely in the cytoplasm, or attached to the cell membrane where DNA processing takes place.[22][38]
The archaea are noted for their extremophile species, and many are selectively evolved to thrive in extreme heat, cold, acidic, alkaline, or high salt conditions.[39] There are no known archaean pathogens.[40]
Eukaryotes can be single-celled, as in diatoms (microscopic algae), or multicellular, as in animals, plants, most fungi, and some algae.[41]Multicellular organisms are made up of many different types of cell known overall as somatic cells.[42] Eukaryotes are distinguished by the presence of a membrane-bound nucleus.[43] The nucleus gives the eukaryote its name, which means "true nut" or "true kernel", where "nut" means the nucleus.[44] A eukaryotic cell can be 2 to 100 times larger in diameter than a typical prokaryotic cell.[45]
Eukaryotic cells have a cell membrane that surrounds a gel-like cytoplasm. The cytoplasm contains the cytoskeleton, and surrounds the cell nucleus, the endoplasmic reticulum, ribosomes, the Golgi apparatus, mitochondria, lysosomes, peroxisomes, endosomes, vacuoles and vesicles, and may have a cell wall, chloroplasts, vaults, and cell-surface appendages. There are many cell variations among the different eukaryote groups.
The membranes of most of the organelles including the cell membrane are sometimes referred to as the endomembrane system.[46] All of these membranes are involved in the secretory and endocytic pathways, modifying, packaging, and transporting proteins and lipids to and from the trans-Golgi network.[47] In mammalian cells, endocytosis includes early, late, and recyclingendosomes.[47]
Most distinct cell types arise from a single totipotent cell, called a zygote, that differentiates into hundreds of different cell types during the course of development. Differentiation of cells is driven by different environmental cues (such as cell–cell interaction) and intrinsic differences (such as those caused by the uneven distribution of molecules during division).[48]
Eukaryotic cell types include those that make up animals, plants, fungi, algae, and protists. All of which have many different species and cell differences. A separate grouping of animals and fungi are known as opisthokonts.
There are an estimated 200 different cell types in the human body. The estimated cell count in a typical adult human body is around 30 trillion cells, 36 trillion in an adult male, and 28 trillion in a female.[51]
Structure
An animal cell has a cell membrane that surrounds a gel-like cytoplasm. The cytoplasm contains the cytoskeleton, the cell nucleus, the endoplasmic reticulum, ribosomes, the Golgi apparatus, mitochondria, lysosomes, peroxisomes, endosomes, vacuoles and vesicles, and vaults. An animal cell structure, as other eukaryotes, includes an endomembrane system encompassing the cell membrane, and all the membranes of the organelles excluding those of the mitochondria.The whole system cooperates in the modification, packaging, and transport of proteins and lipids.[46]
Underlying, and attached to the cell membrane is the cell cortex, the outermost part of the actin cytoskeleton.[57]
Cytoplasm
The cell membrane encloses the cytoplasm of the cell that surrounds all of the cell's organelles.[58] It is made up of two main components, the cytoskeleton made up of protein filaments, and the cytosol.[58] The network of filaments and microtubules of the cytoskeleton gives shape and support to the cell, and has a part in organising the cell components.
The cytosol is a gel-like substance made up of water, ions, and non-essential biomolecules, and is the main site of protein synthesis, and degradation.[58] The acidity (pH) of the cytosol is near neutral, and is regulated by transporters in the cell membrane. Different proteins in the cytoplasm operate optimally at different pHs.[59] The cytosol forms 30%–50% of the cell's volume.[60]
Cytoskeleton
The cytoskeleton acts to organize and maintain the cell's shape; anchors organelles in place; helps during endocytosis, and in the uptake of external materials by a cell.The cytoskeleton is composed of microtubules, intermediate filaments and microfilaments. There are a great number of proteins associated with them, each controlling a cell's structure by directing, bundling, and aligning filaments. The outermost part of the cytoskeleton is the cell cortex, or actin cortex, a thin layer of cross-linked actomyosins.[57] Its thickness varies with cell type and physiology.[57] It directs the transport through the ER and the Golgi apparatus.[61] The cytoskeleton in the animal cell also plays a part in cytokinesis, in the formation of the spindle apparatus during cell division, the separation of daughter cells.
Organelles are compartments of the cell that are specialized for carrying out one or more functions, analogous to the organs, such as the heart, and lungs.[22] There are several types of organelles held in the cytoplasm. Most organelles are membrane-bound, and vary in size and number based on the growth of the host cell.[62] Organelles include the nucleus, mitochondria, endoplasmic reticulum, Golgi apparatus, vesicles, and vacuoles. Membrane-less organelles include the centrosome, typically the ribosome,[63] and vaults.[64]
The cell nucleus is the largest organelle in the animal cell.[51] It houses the cell's chromosomes, and is the place where almost all DNA replication and RNA synthesis (transcription) occur. The nucleus is spherical and separated from the cytoplasm by a double-membraned nuclear envelope. A space between the membranes is called the perinuclear space. The nuclear envelope isolates and protects a cell's DNA from various molecules that could accidentally damage its structure or interfere with its processing. During processing, DNA is transcribed, or copied into a special RNA, called messenger RNA (mRNA). This mRNA is then transported out of the nucleus, where it is translated into a specific protein molecule. The nucleolus is a specialized biomolecular condensate within the nucleus where ribosome subunits are assembled. It is one of several types of membrane-less nuclear bodies.[22] Cells use DNA for their long-term information storage that is encoded in its DNA sequence.[22] RNA is used for information transport (e.g., mRNA) and enzymatic functions (e.g., ribosomal RNA). Transfer RNA (tRNA) molecules are used to add amino acids during protein translation.[65]
The endoplasmic reticulum (ER) is a transport network for molecules targeted for certain modifications and specific destinations, as compared to molecules that float freely in the cytoplasm. The ER has two forms: the rough endoplasmic reticulum (RER), which has ribosomes on its surface that secrete proteins into the ER, and the smooth endoplasmic reticulum (SER), which lacks ribosomes.[22] The smooth ER plays a role in calcium sequestration and release, and helps in synthesis of lipid.[68]
Golgi apparatus
The Golgi apparatus processes and packages proteins, and lipids, that are synthesized by the cell. It is organized as a stack of plate-like structures known as cisternae.[69]
Mitochondria
Mitochondria are self-replicating double membrane-bound organelles that occur in various numbers, shapes, and sizes in the cytoplasm of the cell.[22]Aerobic respiration in the mitochondria generates the cell's energy by oxidative phosphorylation, using oxygen to release energy stored in cellular nutrients (typically pertaining to glucose) to generate adenosine triphosphate (ATP).[70] Mitochondria are descended from bacteria that formed an endosymbiotic relationship with ancient prokaryotes.[71] Mitochondria multiply by binary fission[72] and have their own DNA contained in multiple small circular chromosomes.[73][74] The mitochondrial DNA (mtDNA) is very small compared to nuclear DNA,[22] but it codes for 13 proteins involved in mitochondrial energy production and specific transfer RNAs (tRNAs).[75] Mitochondria also have their own ribosomes known as mitoribosomes.[76]
Lysosomes
A lysosome is the most acidic compartment in the cell.[77] It contains over 60 different hydrolytic enzymes that need an acidic environment.[78] They digest excess or worn-out organelles, food particles, and engulfed viruses or bacteria. The cell could not house these destructive enzymes if they were not contained in a membrane-bound compartment.[22][79]
Peroxisomes
Peroxisomes are microbodies bounded by a single membrane. A peroxisome has no DNA or ribosomes and the proteins that it needs are encoded in the nucleus, and selectively imported from the cytosol. Some proteins enter via the endomembrane reticulum.[80] They have enzymes that rid the cell of toxic peroxides. The enzymatic content of the peroxisomes varies widely across the species, as it can in an individual organism.[81][80] The peroxisomes in animal cells are concentrated in the liver cells and adipocytes.[81]
Vacuoles
Vacuoles sequester waste products. Some cells, most notably Amoeba, have contractile vacuoles, which can pump water out of the cell if there is too much water.[82]
A vault is a large ribonuclear protein particle, a non-membrane-bound organelle, three times the size of a ribosome but with only three proteins in contrast to the near hundred in the ribosome.[64] Most human cells have around 10,000 vaults, and in some types of immune cell there may be up to 100,000. Macrophages have the greatest number of vaults of any human cell.[85] Vaults are largely overlooked because their functions are purely speculative. They may play a role in transport from the nucleus to the cytoplasm, and may serve as scaffolds for signal transduction proteins. They are present in normal tissues, and more so in secretory and excretory epithelial cells.[64][85]
Some types of specialised cell are localised to a particular animal group. Vertebrates for example have specialised, structurally changed cells including muscle cells. The cell membrane of a skeletal muscle cell or of a cardiac muscle cell is termed the sarcolemma.[86] And the cytoplasm is termed the sarcoplasm. Skeletal muscle cells also become multinucleated. Populations of animal groups evolve to become distinct species, where sexual reproduction is isolated. The many species of vertebrates for example have other unique characteristics by way of additional specialised cells. In some species of electric fish for example modified muscle cells or nerve cells have specialised to become electerocytes capable of creating and storing electrical energy for future release, as in stunning prey, or use in electrolocation.[87] These are large flat cells in the electric eel, and electric ray in which thousands are stacked into an electric organ comparable to a voltaic pile.[88]
Many animal cells are ciliated and most cells except red blood cells have primary cilia. Primary cilia play important roles in chemosensation and mechanosensation.[89][90] Each cilium may be "viewed as a sensory cellular antennae that coordinates a large number of cellular signaling pathways, sometimes coupling the signaling to ciliary motility or alternatively to cell division and differentiation."[91] The cilia in other cells are motile organelles, and in the respiratory epithelium play an important role in the movement of mucus. In the reproductive system ciliated epithelium in the fallopian tubes move the egg from the uterus to the ovary. Motile cilia also known as flagella, drive the sperm cells.[92]Invertebrateplanarians have ciliated excretory flame cells.[93] Other excretory cells also found in planarians are solenocytes that are long and flagellated.
Plant cells have cell walls composed of cellulose, hemicelluloses, and pectin that are constructed outside the cell membrane. In sclerenchyma tissue lignin is secreted to form a secondary wall inside the primary cell wall.[94]Cutin is secreted outside the primary cell wall and into the outer layers of the secondary cell wall of the epidermal cells of leaves, stems and other above-ground organs to form the plant cuticle.[citation needed] Cell walls perform many essential functions, they provide shape to form the tissue and organs of the plant, and play an important role in intercellular communication and plant-microbe interactions.[citation needed] Specialized cell-to-cell communication pathways known as plasmodesmata, occur in the form of pores in the primary cell wall through which the cell membrane and endoplasmic reticulum of adjacent cells are continuous.[citation needed]
Organelles in plant cells, include pigment-containing plastids, especially chloroplasts that contain chlorophyll (also found in algae), water-storage vacuoles, and two types of peroxisome. Chloroplasts capture the sun's energy to make carbohydrates through photosynthesis.[95]Chromoplasts contain fat-soluble carotenoid pigments such as orange carotene and yellow xanthophylls which helps in synthesis and storage. Leucoplasts are non-pigmented plastids and helps in storage of nutrients.[96] Plastids divide by binary fission.[97] The vacuoles are larger than those in animal cells, and their membrane transports ions against concentration gradients.[98][99] One type of peroxisome is in the leaves where it takes part in photorespiration. The other type is in germinating seeds where it takes part in the conversion of fatty acids into sugars for the plant's growth.[80] In this peroxisome type the enzymatic content is so different from other groups that it has an alternative name of glyoxysome. The enzymes are of the glyoxylate cycle.[81]
The plant cytoskeleton is a dynamic structure that has a scaffold of microtubules and microfilaments, but no intermediate filaments.[100] The microtubule organizing center in plant cells is often sited underneath the cell membrane where nucleated microtubules often form sheet-like semi-parallel arrays.[101]
The cells of fungi have in addition to the shared eukaryotic organelles a spitzenkörper in their endomembrane system, associated with hyphal tip growth. It is a phase-dark body that is composed of an aggregation of membrane-bound vesicles containing cell wall components, serving as a point of assemblage and release of such components intermediate between the Golgi and the cell membrane. The spitzenkörper is motile and generates new hyphal tip growth as it moves forward.[107]
Human cancer cells, specifically HeLa cells, with DNA stained blue. The central and rightmost cell are in interphase, so their DNA is diffuse and the entire nuclei are labelled. The cell on the left is going through mitosis and its chromosomes have condensed.
In meiosis, the DNA is replicated only once, while the cell divides twice. DNA replication only occurs before meiosis I. DNA replication does not occur when the cells divide the second time, in meiosis II.[114] Replication, like all cellular activities, requires specialized proteins.[22]
Cell signaling is the process by which a cell interacts with itself, other cells, and the environment. Typically, the signaling process involves three components: the first messenger (the ligand), the receptor, and the signal itself.[115] Most cell signaling is chemical in nature, and can occur with neighboring cells or more distant targets. Signal receptors are complex proteins or tightly bound multimer of proteins, located in the plasma membrane or within the interior.[116]
Each cell is programmed to respond to specific extracellular signal molecules, and this process is the basis of development, tissue repair, immunity, and homeostasis. Individual cells are able to manage receptor sensitivity including turning them off, and receptors can become less sensitive when they are occupied for long durations.[116] Errors in signaling interactions may cause diseases such as cancer, autoimmunity, and diabetes.[117]
Proteins can be targeted to the inner space of an organelle, different intracellular membranes, the plasma membrane, or to the exterior of the cell via secretion.[118][119] Information contained in the protein itself directs this delivery process.[119][120] Correct sorting is crucial for the cell; errors or dysfunction in sorting have been linked to multiple diseases.[119][121][122]
Between successive cell divisions, cells grow through the functioning of cellular metabolism. Cell metabolism is the process by which individual cells process nutrient molecules. Metabolism has two distinct divisions: catabolism, in which the cell breaks down complex molecules to produce energy and reducing power, and anabolism, in which the cell uses energy and reducing power to construct complex molecules and perform other biological functions.[124]
Complex sugars can be broken down into simpler sugar molecules called monosaccharides such as glucose. Once inside the cell, glucose is broken down to make adenosine triphosphate (ATP),[22] a molecule that possesses readily available energy, through two different pathways. In plant cells, chloroplasts create sugars by photosynthesis, using the energy of light to join molecules of water and carbon dioxide.[125]
Cells are capable of synthesizing new proteins, which are essential for the modulation and maintenance of cellular activities. This process involves the formation of new protein molecules from amino acid building blocks based on information encoded in DNA/RNA. Protein synthesis generally consists of two major steps: transcription and translation.[65]
Transcription is the process where genetic information in DNA is used to produce a complementary RNA strand. This RNA strand is then processed to give messenger RNA (mRNA), which is free to migrate into the cytoplasm. mRNA molecules bind to protein-RNA complexes called ribosomes located in the cytosol, where they are translated into polypeptide sequences. The ribosome mediates the formation of a polypeptide sequence based on the mRNA sequence. The mRNA sequence directly relates to the polypeptide sequence by binding to transfer RNA (tRNA) adapter molecules in binding pockets within the ribosome.[65] The new polypeptide chain then folds into a functional three-dimensional protein molecule.
Unicellular organisms can move in order to find food or escape predators. Common mechanisms of motion include flagella and cilia,[35] and the projection of pseudopodia in amoeboid movement. Cells in multicellular organisms can move during processes such as wound healing, the immune response, and cancer metastasis. In wound healing in animals, white blood cells move to the wound site to kill the pathogens causing infection. Cell motility involves many receptors, crosslinking, bundling, binding, adhesion, motor and other proteins.[126] The process is divided into three steps: protrusion of the leading edge of the cell, adhesion of the leading edge and de-adhesion at the cell body and rear, and cytoskeletal contraction to pull the cell forward. Each step is driven by physical forces generated by unique segments of the cytoskeleton.[127][126]
In August 2020, scientists described one way cells—in particular cells of a slime mold and mouse pancreatic cancer-derived cells—are able to navigate efficiently through a body and identify the best routes through complex mazes: generating gradients after breaking down diffused chemoattractants which enable them to sense upcoming maze junctions before reaching them, including around corners.[128][129][130]
Stromatolites are left behind by cyanobacteria, known as blue-green algae. They are among the oldest fossils of life on Earth. This one-billion-year-old fossil is from Glacier National Park in the United States.
Cells emerged around 4 billion years ago.[138][139] The first cells were most likely heterotrophs. The early cell membranes were probably simpler and more permeable than later ones, with only a single fatty acid chain per lipid. Lipids spontaneously form bilayered vesicles in water, and could have preceded RNA.[140][141]
In the theory of symbiogenesis, a merger of an archaean and an aerobic bacterium created the eukaryotes, with aerobic mitochondria, some 2.2 billion years ago. A second merger, 1.6 billion years ago, added chloroplasts, creating the green plants.
The first evidence of multicellularity in an organism comes from cyanobacteria-like organisms that lived between 3 and 3.5 billion years ago.[150] Cyanobacteria are variable in morphology, filamentous forms exhibit functional cell differentiation such as heterocysts (for nitrogen fixation), akinetes (resting stage cells), and hormogonia (reproductive, motile filaments). These, together with the intercellular connections they possess, are considered the first signs of multicellularity.[151]
Multicellularity was made possible by the development of the extracellular matrix (ECM) similar in function to the bacterial EPS that consists of extracellular polymeric substances.[152] EPS enables microbial cell adhesion, and is believed to be the first evolutionary step toward multicellular organisms.[153]Basement membranes are a type of specialized extracellular matrix that surrounds most animal tissues, and are essential in their formation.[154] Extracellular matrix components of laminin domains, integrated with other proteins such as cadherins have been described in single-celled motile choanoflagellates that pre-dates the evolutionary emergence of basement membranes, one of the two types of ECM.[155] The emergence of the basement membrane coincided with the origin of multicellularity.[154][156] The other type of ECM is the interstial matrix.
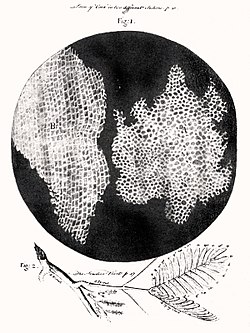
In 1665, Robert Hooke examined a thin slice of cork under his microscope, and saw a structure of small enclosures. He wrote "I could exceeding plainly perceive it to be all perforated and porous, much like a honeycomb, but that the pores of it were not regular".[157] To further support his theory, Matthias Schleiden and Theodor Schwann studied cells of both animal and plants. What they discovered were significant differences between the two types of cells. This put forth the idea that cells were fundamental to both plants and animals.[158]
↑Cooper, Geoffrey M. (2000). "The Origin and Evolution of Cells". The Cell: A Molecular Approach. 2nd edition. Sinauer Associates. Retrieved 17 September 2025.
↑Cole, Laurence A. (2016-01-01), Cole, Laurence A. (ed.), "Chapter 13 - Evolution of Chemical, Prokaryotic, and Eukaryotic Life", Biology of Life, Academic Press, pp.93–99, doi:10.1016/b978-0-12-809685-7.00013-7, ISBN978-0-12-809685-7{{citation}}: CS1 maint: work parameter with ISBN (link)
↑Egan, Elizabeth S.; Fogel, Michael A.; Waldor, Matthew K. (2005). "MicroReview: Divided genomes: negotiating the cell cycle in prokaryotes with multiple chromosomes". Molecular Microbiology. 56 (5): 1129–1138. doi:10.1111/j.1365-2958.2005.04622.x. PMID15882408.
↑Saier Jr., Milton H.; Bogdanov, Mikhail V. (2013). "Membranous Organelles in Bacteria". Microbial Physiology. 23 (1–2): 5–12. doi:10.1159/000346496. PMID23615191.
↑Kim, K. W. (2017). "Electron microscopic observations of prokaryotic surface appendages". Journal of Microbiology. 55 (12): 919–926. doi:10.1007/s12275-017-7369-4. PMID29214488.
↑Lodé, Thierry (October 2012). "For Quite a Few Chromosomes More: The Origin of Eukaryotes…". Journal of Molecular Biology. 423 (2): 135–142. doi:10.1016/j.jmb.2012.07.005. PMID22796299.
12Khan, Yusuf S.; Farhana, Aisha (2025). "Histology, Cell". StatPearls. StatPearls Publishing. Retrieved 15 October 2025.
↑"Inside the Cell"(PDF). publications.nigms.nih.gov. Archived from the original(PDF) on 28 July 2017. Retrieved 22 September 2025.
↑Singer, S. J.; Nicolson, Garth L. (February 18, 1972). "The Fluid Mosaic Model of the Structure of Cell Membranes: Cell membranes are viewed as two-dimensional solutions of oriented globular proteins and lipids". Science. 175 (4023): 720–731. doi:10.1126/science.175.4023.720. PMID4333397.
123Alberts, Bruce (2015). Molecular biology of the cell (6thed.). New York: Garland science, Taylor and Francis group. pp.666–667. ISBN978-0-8153-4464-3.
↑Mauro A (April 1969). "The role of the Voltaic pile in the Galvani-Volta controversy concerning animal vs. metallic electricity". J Hist Med Allied Sci. 24 (2): 140–50. doi:10.1093/jhmas/xxiv.2.140. PMID4895861.
↑Haycraft, Courtney J.; Serra, Rosa (2008-01-01), "Chapter 11 Cilia Involvement in Patterning and Maintenance of the Skeleton", Current Topics in Developmental Biology, Ciliary Function in Mammalian Development, 85, Academic Press: 303–332, doi:10.1016/s0070-2153(08)00811-9, ISBN978-0-12-374453-1, PMC3107512, PMID19147010{{citation}}: CS1 maint: work parameter with ISBN (link)
↑Björn, Lars Olof; Govindjee (2009). "The evolution of photosynthesis and chloroplasts". Current Science. 96 (11 June 10, 2009): 1466–1474. JSTOR24104775.
↑Sato, N. (2006). "Origin and Evolution of Plastids: Genomic View on the Unification and Diversity of Plastids". In Wise, R. R.; Hoober, J. K. (eds.). The Structure and Function of Plastids. Advances in Photosynthesis and Respiration. Vol.23. Springer. pp.75–102. doi:10.1007/978-1-4020-4061-0_4. ISBN978-1-4020-4060-3.
↑Shigenaga AM, Argueso CT (August 2016). "No hormone to rule them all: Interactions of plant hormones during the responses of plants to pathogens". Seminars in Cell & Developmental Biology. 56: 174–189. doi:10.1016/j.semcdb.2016.06.005. PMID27312082.
↑Takeda, David Y.; Dutta, Anindya (April 2005). "DNA replication and progression through S phase". Oncogene. 24 (17): 2827–2843. doi:10.1038/sj.onc.1208616. PMID15838518.
↑Campbell Biology–Concepts and Connections. Pearson Education. 2009. p.138.
12Nelson DL (January 2017). Lehninger principles of biochemistry. Cox, Michael M.,, Lehninger, Albert L. (Seventhed.). New York, NY. ISBN978-1-4641-2611-6. OCLC986827885.{{cite book}}: CS1 maint: location missing publisher (link)
1234Lodish, Berk, Kaiser, Krieger, Bretscher, Ploegh, Martin, Yaffe, Amon (2021). Molecular Cell Biology (9thed.). New York, NY: W.H. Freeman and Company. ISBN978-1-319-20852-3.{{cite book}}: CS1 maint: multiple names: authors list (link)
↑Guo Y, Sirkis DW, Schekman R (2014-10-11). "Protein sorting at the trans-Golgi network". Annual Review of Cell and Developmental Biology. 30 (1): 169–206. doi:10.1146/annurev-cellbio-100913-013012. PMID25150009.
↑Alberts, B.; etal. (2002). "Chloroplasts and Photosynthesis". Molecular Biology of the Cell (4thed.). New York: Garland Science. Retrieved 2025-10-04.
↑D'Arcy, Mark S. (June 2019). "Cell death: a review of the major forms of apoptosis, necrosis and autophagy". Cell Biology International. 43 (6): 582–592. doi:10.1002/cbin.11137. PMID30958602.
↑Orgel, L. E. (December 1998). "The origin of life--a review of facts and speculations". Trends in Biochemical Sciences. 23 (12): 491–495. doi:10.1016/S0968-0004(98)01300-0. PMID9868373.
1234Latorre, A.; Durban, A; Moya, A.; Pereto, J. (2011). "The role of symbiosis in eukaryotic evolution". In Gargaud, Muriel; López-Garcìa, Purificacion; Martin, H. (eds.). Origins and Evolution of Life: An astrobiological perspective. Cambridge: Cambridge University Press. pp.326–339. ISBN978-0-521-76131-4. Archived from the original on 24 March 2019. Retrieved 27 August 2017.
↑Hooke, Robert (1665). Micrographia: ... London: Royal Society of London. p.113. ... I could exceedingly plainly perceive it to be all perforated and porous, much like a Honey-comb, but that the pores of it were not regular [...] these pores, or cells, [...] were indeed the first microscopical pores I ever saw, and perhaps, that were ever seen, for I had not met with any Writer or Person, that had made any mention of them before this ... – Hooke describing his observations on a thin slice of cork. See also: Robert HookeArchived 1997-06-06 at the Wayback Machine
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.