Primarily in the United States, the United Kingdom, Japan, France, Germany, and China
Participants
At least 20 institutions, companies, and laboratories
Duration
1990 – 2003
The Human Genome Project (HGP) was an international scientific research project with the goal of determining the base pairs that make up human DNA, and of identifying, mapping and sequencing all of the genes of the human genome from both a physical and a functional standpoint. It started in 1990 and was completed in 2003.[1] It was the world's largest collaborative biological project.[2] Planning for the project began in 1984 by the US government, and it officially launched in 1990. It was declared complete on 14 April 2003, and included about 92% of the genome.[3] Level "complete genome" was achieved in May 2021, with only 0.3% of the bases covered by potential issues.[4][5] The final gapless assembly was finished in January 2022.[6]
Funding came from the US government through the National Institutes of Health (NIH) as well as numerous other groups from around the world. A parallel project was conducted outside the government by the Celera Corporation, or Celera Genomics, which was formally launched in 1998. Most of the government-sponsored sequencing was performed in twenty universities and research centres in the United States, the United Kingdom, Japan, France, Germany, and China,[7] working in the International Human Genome Sequencing Consortium (IHGSC).
The Human Genome Project originally aimed to map the complete set of nucleotides contained in a human haploidreference genome, of which there are more than three billion. The genome of any given individual is unique; mapping the human genome involved sequencing samples collected from a small number of individuals and then assembling the sequenced fragments to get a complete sequence for each of the 23 human chromosome pairs (22 pairs of autosomes and a pair of sex chromosomes, known as allosomes). Therefore, the finished human genome is a mosaic, not representing any one individual. Much of the project's utility comes from the fact that the vast majority of the human genome is the same in all humans.
History
The Human Genome Project was a 13-year-long publicly funded project initiated in 1990 with the objective of determining the DNA sequence of the entire euchromatic human genome within 13 years.[8][9] The idea that sets of inherited genes predicted the concept of mapping a disease gene to a chromosomal region originated in the work of Ronald Fisher, whose work is further credited with later initiating the project.[10] In 1977, Walter Gilbert, Frederick Sanger, and Paul Berg invented these methods of sequencing DNA.[11][12]
In May 1985, Robert Sinsheimer organized a workshop at the University of California, Santa Cruz, to discuss the feasibility of building a systematic reference genome using gene sequencing technologies.[13]Gilbert wrote the first plan for what he called The Human Genome Institute on the plane ride home from the workshop.[14] In March 1986, the Santa Fe Workshop was organized by Charles DeLisi and David Smith of the Department of Energy's Office of Health and Environmental Research (OHER).[15] At the same time Renato Dulbecco, President of the Salk Institute for Biological Studies, first proposed the concept of whole genome sequencing in an essay in Science.[16] The published work, titled "A Turning Point in Cancer Research: Sequencing the Human Genome", was shortened from the original proposal of using the sequence to understand the genetic basis of breast cancer.[17]James Watson, one of the discoverers of the double helix shape of DNA in the 1950s, followed two months later with a workshop held at the Cold Spring Harbor Laboratory. Thus the idea for obtaining a reference sequence had three independent origins: Sinsheimer, Dulbecco and DeLisi. Ultimately it was the actions by DeLisi that launched the project.[18][19][20][21]
The fact that the Santa Fe Workshop was motivated and supported by a federal agency opened a path, albeit a difficult and tortuous one,[22] for converting the idea into public policy in the United States. In a memo to the Assistant Secretary for Energy Research Alvin Trivelpiece, then-Director of the OHER Charles DeLisi outlined a broad plan for the project.[23] This started a long and complex chain of events that led to the approved reprogramming of funds that enabled the OHER to launch the project in 1986, and to recommend the first line item for the HGP, which was in President Reagan's 1988 budget submission,[22] and ultimately approved by Congress. Of particular importance in congressional approval was the advocacy of New Mexico Senator Pete Domenici, whom DeLisi had befriended.[24] Domenici chaired the Senate Committee on Energy and Natural Resources, as well as the Budget Committee, both of which were key in the DOE budget process. Congress added a comparable amount to the NIH budget, thereby beginning official funding by both agencies.[citation needed]
Trivelpiece sought and obtained the approval of DeLisi's proposal from Deputy Secretary William Flynn Martin. This chart[25] was used by Trivelpiece in the spring of 1986 to brief Martin and Under Secretary Joseph Salgado regarding his intention to reprogram $4million to initiate the project with the approval of John S. Herrington.[citation needed] This reprogramming was followed by a line item budget of $13million in the Reagan administration's 1987 budget submission to Congress.[15] It subsequently passed both Houses. The project was planned to be completed within 15 years.[26]
In 1990 the two major funding agencies, DOE and the National Institutes of Health, developed a memorandum of understanding to coordinate plans and set the clock for the initiation of the Project to 1990.[27] At that time, David J. Galas was Director of the renamed "Office of Biological and Environmental Research" in the US Department of Energy's Office of Science and James Watson headed the NIH Genome Program. In 1993, Aristides Patrinos succeeded Galas and Francis Collins succeeded Watson, assuming the role of overall Project Head as Director of the NIH National Center for Human Genome Research (which would later become the National Human Genome Research Institute). A working draft of the genome was announced in 2000 and the papers describing it were published in February 2001. A more complete draft was published in 2003, and genome "finishing" work continued for more than a decade after that.[citation needed]
The $3billion project was formally founded in 1990 by the US Department of Energy and the National Institutes of Health, and was expected to take 15 years.[28] In addition to the United States, the international consortium comprised geneticists in the United Kingdom, France, Australia, China, and a myriad of other spontaneous relationships.[29] The project ended up costing less than expected, at about $2.7billion (equivalent to about $5billion in 2021).[7][30][31] Most of the genome was mapped over a two-year span.[32]
Two technologies enabled the project: gene mapping and DNA sequencing. The gene mapping technique of restriction fragment length polymorphism (RFLP) arose from the search for the location of the breast cancer gene by Mark Skolnick of the University of Utah,[33] which began in 1974.[34] Seeing a linkage marker for the gene, in collaboration with David Botstein, Ray White and Ron Davis conceived of a way to construct a genetic linkage map of the human genome. This enabled scientists to launch the larger human genome effort.[35]
Because of widespread international cooperation and advances in the field of genomics (especially in sequence analysis), as well as parallel advances in computing technology, a 'rough draft' of the genome was finished in 2000 (announced jointly by US President Bill Clinton and British Prime Minister Tony Blair on 26 June 2000).[36][37] This first available rough draft assembly of the genome was completed by the Genome Bioinformatics Group at the University of California, Santa Cruz, primarily led by then-graduate student Jim Kent and his advisor David Haussler.[38] Ongoing sequencing led to the announcement of the essentially complete genome on 14 April 2003, two years earlier than planned.[39][40] In May 2006, another milestone was passed on the way to completion of the project when the sequence of the very last chromosome was published in Nature.[41]
The various institutions, companies, and laboratories which participated in the Human Genome Project are listed below, according to the NIH:[7]
Notably the project was not able to sequence all of the DNA found in human cells; rather, the aim was to sequence only euchromatic regions of the nuclear genome, which make up 92.1% of the human genome. The remaining 7.9% exists in scattered heterochromatic regions such as those found in centromeres and telomeres. These regions by their nature are generally more difficult to sequence and so were not included as part of the project's original plans.[42]
The Human Genome Project (HGP) was declared complete in April 2003. An initial rough draft of the human genome was available in June 2000 and by February 2001 a working draft had been completed and published followed by the final sequencing mapping of the human genome on 14 April 2003. Although this was reported to cover 99% of the euchromatic human genome with 99.99% accuracy, a major quality assessment of the human genome sequence was published on 27 May 2004, indicating over 92% of sampling exceeded 99.99% accuracy which was within the intended goal.[43]
In March 2009, the Genome Reference Consortium (GRC) released a more accurate version of the human genome, but that still left more than 300 gaps,[44] while 160 such gaps remained in 2015.[45]
Though in May 2020 the GRC reported 79 "unresolved" gaps,[46] accounting for as much as 5% of the human genome,[47] months later, the application of new long-range sequencing techniques and a hydatidiform mole-derived cell line in which both copies of each chromosome are identical led to the first telomere-to-telomere, truly complete sequence of a human chromosome, the X chromosome.[48] Similarly, an end-to-end complete sequence of human autosomal chromosome 8 followed several months later.[49]
In April 2022, the Telomere-to-Telomere (T2T) consortium published a complete sequence of the non-Y chromosomes, highlighting the 8% of the human genome that the HGP had not sequenced.[50][51][52][53] The T2T consortium then used this newly completed genome sequence[54] as a reference to identify over 2 million additional genomic variants.[55] In August 2023, Rhie et al. reported the successful sequencing of the previously missing regions of the Y chromosome, achieving the full sequencing of all 24 human chromosomes.[56][57]
Applications and proposed benefits
The sequencing of the human genome holds benefits for many fields, from molecular medicine to human evolution. The Human Genome Project, through its sequencing of the DNA, can help researchers understand diseases including: genotyping of specific viruses to direct appropriate treatment; identification of mutations linked to different forms of cancer; the design of medication and more accurate prediction of their effects; advancement in forensic applied sciences; biofuels and other energy applications; agriculture, animal husbandry, bioprocessing; risk assessment; bioarcheology, anthropology and evolution. The sequence of the DNA is stored in databases available to anyone on the Internet. The US National Center for Biotechnology Information (and sister organizations in Europe and Japan) house the gene sequence in a database known as GenBank, along with sequences of known and hypothetical genes and proteins. Other organizations, such as the UCSC Genome Browser at the University of California, Santa Cruz,[58] and Ensembl[59] present additional data and annotation and powerful tools for visualizing and searching it. Computer programs have been developed to analyze the data because the data itself is difficult to interpret without such programs. Generally speaking, advances in genome sequencing technology have followed Moore's Law, a concept from computer science which states that integrated circuits can increase in complexity at an exponential rate.[60] This means that the speeds at which whole genomes can be sequenced can increase at a similar rate, as was seen during the development of the Human Genome Project. By 2023, the speed record for sequencing a genome was around five hours; more often, however, it takes weeks.[32]
Techniques and analysis
The process of identifying the boundaries between genes and other features in a raw DNA sequence is called genome annotation and is in the domain of bioinformatics. While expert biologists make the best annotators, their work proceeds slowly, and computer programs are increasingly used to meet the high-throughput demands of genome sequencing projects. Beginning in 2008, a new technology known as RNA-seq was introduced that allowed scientists to directly sequence the messenger RNA in cells. This replaced previous methods of annotation, which relied on the inherent properties of the DNA sequence, with direct measurement, which was much more accurate. Today, annotation of the human genome and other genomes relies primarily on deep sequencing of the transcripts in every human tissue using RNA-seq. These experiments have revealed that over 90% of genes contain at least one and usually several alternative splice variants, in which the exons are combined in different ways to produce 2 or more gene products from the same locus.[61]
The genome published by the HGP does not represent the sequence of every individual's genome. It is the combined mosaic of a small number of anonymous donors, of African, European, and East Asian ancestry. The HGP genome is a scaffold for future work in identifying differences among individuals.[citation needed] Subsequent projects sequenced the genomes of multiple distinct ethnic groups, though as of 2019 there is still only one "reference genome".[62]
Findings
Key findings of the draft (2001) and complete (2004) genome sequences include:
There are approximately 22,300[63] protein-coding genes in human beings, the same range as in other mammals.
The human genome has significantly more segmental duplications (nearly identical, repeated sections of DNA) than had been previously suspected.[64][65][66]
At the time when the draft sequence was published, fewer than 7% of protein families appeared to be vertebrate specific.[67]
Accomplishments
The first printout of the human genome to be presented as a series of books, displayed at the Wellcome Collection, London
The human genome has approximately 3.1billion base pairs.[68] The Human Genome Project was started in 1990 with the goal of sequencing and identifying all base pairs in the human genetic instruction set, finding the genetic roots of disease and then developing treatments. It is considered a megaproject.
The genome was broken into smaller pieces; approximately 150,000 base pairs in length.[69] These pieces were then ligated into a type of vector known as "bacterial artificial chromosomes", or BACs, which are derived from bacterial chromosomes which have been genetically engineered. The vectors containing the genes can be inserted into bacteria where they are copied by the bacterial DNA replication machinery. Each of these pieces was then sequenced separately as a small "shotgun" project and then assembled. The larger, 150,000 base pairs go together to create chromosomes. This is known as the "hierarchical shotgun" approach, because the genome is first broken into relatively large chunks, which are then mapped to chromosomes before being selected for sequencing.[70][71]
The UN Educational, Scientific and Cultural Organization (UNESCO) served as an important channel for the involvement of developing countries in the Human Genome Project.[73]
Public versus private approaches
In 1998 a similar, privately funded quest was launched by the American researcher Craig Venter, and his firm Celera Genomics. Venter was a scientist at the NIH during the early 1990s when the project was initiated. The $300million Celera effort was intended to proceed at a faster pace and at a fraction of the cost of the roughly $3billion publicly funded project. While the Celera project focused its efforts on production sequencing and assembly of the human genome, the public HGP also funded mapping and sequencing of the worm, fly, and yeast genomes, funding of databases, development of new technologies, supporting bioinformatics and ethics programs, as well as polishing and assessment of the genome assembly.[74] Both the Celera and public approaches spent roughly $250million on the production sequencing effort.[75] For sequence assembly, Celera made use of publicly available maps at GenBank, which Celera was capable of generating, but the availability of which was "beneficial" to the privately funded project.[64]
Celera used a technique called whole genome shotgun sequencing, employing pairwise end sequencing,[76] which had been used to sequence bacterial genomes of up to six million base pairs in length, but not for anything nearly as large as the three billion base pair human genome.
Celera initially announced that it would seek patent protection on "only 200–300" genes, but later amended this to seeking "intellectual property protection" on "fully-characterized important structures" amounting to 100–300 targets. The firm eventually filed preliminary ("place-holder") patent applications on 6,500 whole or partial genes. Celera also promised to publish their findings in accordance with the terms of the 1996 "Bermuda Statement", by releasing new data annually (the HGP released its new data daily), although, unlike the publicly funded project, they would not permit free redistribution or scientific use of the data. The publicly funded competitors were compelled to release the first draft of the human genome before Celera for this reason. On 7 July 2000, the UCSC Genome Bioinformatics Group released the first working draft on the web. The scientific community downloaded about 500GB of information from the UCSC genome server in the first 24 hours of free and unrestricted access.[77]
In March 2000 President Clinton, along with Prime Minister Tony Blair in a dual statement, urged that all researchers who wished to research the sequence should have "unencumbered access" to the genome sequence.[78] The statement sent Celera's stock plummeting and dragged down the biotechnology-heavy Nasdaq. The biotechnology sector lost about $50billion in market capitalization in two days.[citation needed]
Although the working draft was announced in June 2000, it was not until February 2001 that Celera and the HGP scientists published details of their drafts. Special issues of Nature (which published the publicly funded project's scientific paper)[64] described the methods used to produce the draft sequence and offered analysis of the sequence. These drafts covered about 83% of the genome (90% of the euchromatic regions with 150,000 gaps and the order and orientation of many segments not yet established). In February 2001, at the time of the joint publications, press releases announced that the project had been completed by both groups. Improved drafts were announced in 2003 and 2005, filling in to approximately 92% of the sequence currently.[citation needed]
Genome donors
In the International Human Genome Sequencing Consortium (IHGSC) public-sector HGP, researchers collected blood (female) or sperm (male) samples from a large number of donors. Only a few of many collected samples were processed as DNA resources. Thus the donor identities were protected so neither donors nor scientists could know whose DNA was sequenced. DNA clones taken from many different libraries were used in the overall project, with most of those libraries being created by Pieter J. de Jong. Much of the sequence (>70%) of the reference genome produced by the public HGP came from a single anonymous male donor from Buffalo, New York, (code name RP11; the "RP" refers to Roswell Park Comprehensive Cancer Center).[79][80]
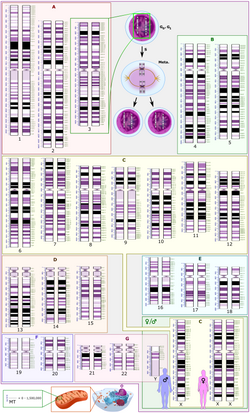
Schematic karyogram of a human, showing an overview of the human genome, with 22 homologous chromosomes, both the female (XX) and male (XY) versions of the sex chromosome (bottom right), as well as the mitochondrial genome (to scale at bottom left). The blue scale to the left of each chromosome pair (and the mitochondrial genome) shows its length in terms of millions of DNA base pairs.
HGP scientists used white blood cells from the blood of two male and two female donors (randomly selected from 20 of each) – each donor yielding a separate DNA library. One of these libraries (RP11) was used considerably more than others, because of quality considerations. One minor technical issue is that male samples contain just over half as much DNA from the sex chromosomes (one X chromosome and one Y chromosome) compared to female samples (which contain two X chromosomes). The other 22 chromosomes (the autosomes) are the same for both sexes.
In the Celera Genomics private-sector project, DNA from five different individuals was used for sequencing. The lead scientist of Celera Genomics at that time, Craig Venter, later acknowledged (in a public letter to the journal Science) that his DNA was one of 21 samples in the pool, five of which were selected for use.[81][82]
Developments
With the sequence in hand the next step was to identify the genetic variants that increase the risk for common diseases like cancer and diabetes.[27][69]
It is anticipated that detailed knowledge of the human genome will offer new avenues for advances in medicine and biotechnology. Clear practical results of the project emerged even before the work was finished. For example, a number of companies, such as Myriad Genetics, started offering easy ways to administer genetic tests that can show predisposition to a variety of illnesses, including breast cancer, hemostasis disorders, cystic fibrosis, liver diseases, and many others. Also, the etiologies for cancers, Alzheimer's disease and other areas of clinical interest are considered likely to benefit from genome information and possibly may lead in the long term to significant advances in their management.[83][84]
There are also many tangible benefits for biologists. For example a researcher investigating a certain form of cancer may have narrowed down their search to a particular gene. By visiting the human genome database on the internet, this researcher can examine what other scientists have written about this gene, including (potentially) the three-dimensional structure of its product, its functions, its evolutionary relationships to other human genes, or to genes in mice, yeast, or fruit flies, possible detrimental mutations, interactions with other genes, body tissues in which this gene is activated, and diseases associated with this gene or other datatypes. Further, a deeper understanding of the disease processes at the level of molecular biology may determine new therapeutic procedures. Given the established importance of DNA in molecular biology and its central role in determining the fundamental operation of cellular processes, it is likely that expanded knowledge in this area will facilitate medical advances in numerous areas of clinical interest that may not have been possible without them.[85]
Analysis of similarities between DNA sequences from different organisms is also opening new avenues in the study of evolution. In many cases, evolutionary questions can now be framed in terms of molecular biology; indeed, many major evolutionary milestones (the emergence of the ribosome and organelles, the development of embryos with body plans, the vertebrateimmune system) can be related to the molecular level. Many questions about the similarities and differences between humans and their closest relatives (the primates, and indeed the other mammals) are expected to be illuminated by the data in this project.[83][86]
The project inspired and paved the way for genomic work in other fields, such as agriculture. For example by studying the genetic composition of Tritium aestivum, the world's most commonly used bread wheat, great insight has been gained into the ways that domestication has impacted the evolution of the plant.[87] It is being investigated which loci are most susceptible to manipulation, and how this plays out in evolutionary terms. Genetic sequencing has allowed these questions to be addressed for the first time, as specific loci can be compared in wild and domesticated strains of the plant. This will allow for advances in genetic modification in the future which could yield healthier and disease-resistant wheat crops, among other things.
Ethical, legal, and social issues
At the onset of the Human Genome Project, several ethical, legal, and social concerns were raised in regard to how increased knowledge of the human genome could be used to discriminate against people. One of the main concerns of most individuals was the fear that both employers and health insurance companies would refuse to hire individuals or refuse to provide insurance to people because of a health concern indicated by someone's genes.[88] In 1996, the United States passed the Health Insurance Portability and Accountability Act (HIPAA), which protects against the unauthorized and non-consensual release of individually identifiable health information to any entity not actively engaged in the provision of healthcare services to a patient.[89]
Along with identifying all of the approximately 20,000–25,000 genes in the human genome (estimated at between 80,000 and 140,000 at the start of the project), the Human Genome Project also sought to address the ethical, legal, and social issues that were created by the onset of the project.[90] For that, the Ethical, Legal, and Social Implications (ELSI) program was founded in 1990. Five percent of the annual budget was allocated to address the ELSI arising from the project.[28][91] This budget started at approximately $1.57million in the year 1990, but increased to approximately $18million in the year 2014.[92]
While the project may offer significant benefits to medicine and scientific research, some authors have emphasized the need to address the potential social consequences of mapping the human genome. Historian of science Hans-Jörg Rheinberger wrote that "the prospect of 'molecularizing' diseases and their possible cure will have a profound impact on what patients expect from medical help, and on a new generation of doctors' perception of illness."[93]
In July 2024, an investigation by Undark Magazine[94] and co-published with STAT News[95] revealed for the first time several ethical lapses by the scientists spearheading the Human Genome Project. Chief among these was the use of roughly 75 percent of a single donor's DNA in the construction of the reference genome, despite informed consent forms, provided to each of the 20 anonymous donors participating, that indicated no more than 10 percent of any one donor's DNA would be used. About 10 percent of the reference genome belonged to one of the project's lead scientists, Pieter De Jong.[94]
↑Bevatron's Encyclopedia of Inventions: a compendium of technological leaps, ground break discoveries and scientific breakthroughs that changed the world. The Human Genome Project, Charles DeLisi, pp. 360–362.
123Human Genome Information Archive. "About the Human Genome Project". US Department of Energy & Human Genome Project program. Archived from the original on 2 September 2011. Retrieved 1 August 2013. This article incorporates text from this source, which is in the public domain.
↑Cook-Deegan, Robert M. (1994). The Gene Wars: Science, Politics, and the Human Genome. New York: W.W. Norton. pp.95–96.
↑Bishop, Jerry E.; Waldholz, Michael (1990). Genome: The Story of the Most Astonishing Scientific Adventure of Our Time – the Attempt to Map All the Genes in the Human Body. New York: Simon and Schuster. p.54.
↑Bishop, Jerry E.; Waldholz, Michael (1990). Genome: The Story of the Most Astonishing Scientific Adventure of Our Time – the Attempt to Map All the Genes in the Human Body. New York: Simon and Schuster. p.201.
↑Sulston, John; Ferry, Georgina (2002). The Common Thread: A Story of Science, Politics, Ethics and the Human Genome. London: Bantam Press. p.160. ISBN0593-048016.
↑Roach JC, Boysen C, Wang K, Hood L (March 1995). "Pairwise end sequencing: a unified approach to genomic mapping and sequencing". Genomics. 26 (2): 345–353. doi:10.1016/0888-7543(95)80219-C. PMID7601461.
↑Center for Biomolecular Science & Engineering. "The Human Genome Project Race". Center for Biomolecular Science and Engineering. Retrieved 1 August 2013.
McElheny VK (2010). Drawing the Map of Life: Inside the Human Genome Project. Basic Books. ISBN978-0-465-03260-0. 361 pages. Examines the intellectual origins, history, and motivations of the project to map the human genome; draws on interviews with key figures.
National Human Genome Research Institute (NHGRI). NHGRI led the National Institutes of Health's contribution to the International Human Genome Project. This project, which had as its primary goal the sequencing of the three billion base pairs that make up the human genome, was successfully completed in April 2003.
Human Genome News. Published from 1989 to 2002 by the US Department of Energy, this newsletter was a major communications method for coordination of the Human Genome Project. Complete online archives are available.
The HGP information pages Department of Energy's portal to the international Human Genome Project, Microbial Genome Program, and Genomics:GTL systems biology for energy and environment
Ensembl project, an automated annotation system and browser for the human genome
UCSC genome browser, This site contains the reference sequence and working draft assemblies for a large collection of genomes. It also provides a portal to the ENCODE project.
relationship to healthcare and to the federally funded Human Genome Project.
Cracking the Code of Life Companion website to 2-hour NOVA program documenting the race to decode the genome, including the entire program hosted in 16 parts in either QuickTime or RealPlayer format.
Project Gutenberg hosts e-texts for Human Genome Project, titled Human Genome Project, Chromosome Number # (# denotes 01–22, X and Y). This information is the raw sequence, released in November 2002; access to entry pages with download links is available through Human Genome Project, Chromosome Number 01 for Chromosome 1 sequentially to Human Genome Project, Y Chromosome for the Y Chromosome. Note that this sequence might not be considered definitive because of ongoing revisions and refinements. In addition to the chromosome files, there is a supplementary information file dated March 2004 which contains additional sequence information.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.



{kind=link}
{kind=link}
{kind=link}