Explanation of the flow of genetic information within a biological system
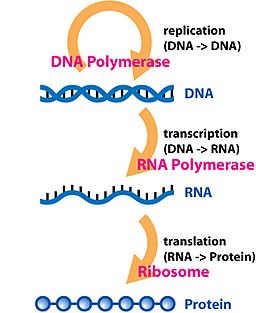
The central dogma of molecular biology deals with the flow of genetic information within a biological system. It is often stated as "DNA makes RNA, and RNA makes protein",[1] although this is not its original meaning. It was first stated by Francis Crick in 1957,[2][3] then published in 1958:[4][5]
The Central Dogma. This states that once "information" has passed into proteinit cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information here means the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein.
He re-stated it in a Nature paper published in 1970: "The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. It states that such information cannot be transferred back from protein to either protein or nucleic acid."[6]
A second version of the central dogma is popular but incorrect. This is the simplistic DNA → RNA → protein pathway published by James Watson in the first edition of The Molecular Biology of the Gene (1965). Watson's version differs from Crick's because Watson describes a two-step (DNA → RNA / RNA → protein) process as the central dogma.[7] While the dogma as originally stated by Crick remains valid today,[6][8] Watson's version does not.[2]
The biopolymers that comprise DNA, RNA and (poly)peptides are linear heteropolymers (i.e.: each monomer is connected to at most two other monomers). The sequence of their monomers effectively encodes information. The transfers of information from one molecule to another are faithful, deterministic transfers, wherein one biopolymer's sequence is used as a template for the construction of another biopolymer with a sequence that is entirely dependent on the original biopolymer's sequence. When DNA is transcribed to RNA, its complement is paired to it. DNA codes are transferred to RNA codes in a complementary fashion. The encoding of proteins is done in groups of three, known as codons. The standard codon table applies for humans and mammals, but some other lifeforms (including human mitochondria[9]) use different translations.[10]
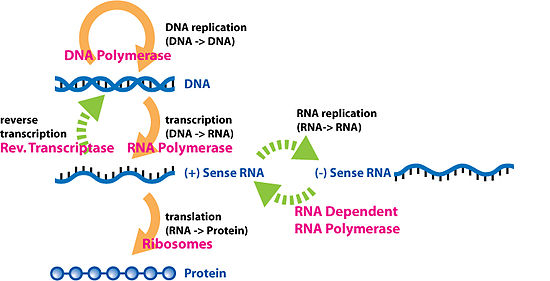
General transfers of biological sequential information
Francis Crick's 1958 figure showing various information transfers
In the sense that DNA replication must occur if genetic material is to be provided for the progeny of any cell, whether somatic or reproductive, the copying from DNA to DNA arguably is the fundamental step in information transfer. A complex group of proteins called the replisome performs the replication of the information from the parent strand to the complementary daughter strand.
Transcription is the process by which the information contained in a section of DNA is replicated in the form of a newly assembled piece of messenger RNA (mRNA). Enzymes facilitating the process include RNA polymerase and transcription factors. In eukaryotic cells the primary transcript is pre-mRNA. Pre-mRNA must be processed for translation to proceed. Processing includes the addition of a 5' cap and a poly-A tail to the pre-mRNA chain, followed by splicing. Alternative splicing occurs when appropriate, increasing the diversity of the proteins that any single mRNA can produce. The product of the entire transcription process (that began with the production of the pre-mRNA chain) is a mature mRNA chain.[citation needed]
The mature mRNA finds its way to a ribosome, where it gets translated. In prokaryotic cells, which have no nuclear compartment, the processes of transcription and translation may be linked together without clear separation. In eukaryotic cells, the site of transcription (the cell nucleus) is usually separated from the site of translation (the cytoplasm), so the mRNA must be transported out of the nucleus into the cytoplasm, where it can be bound by ribosomes. The ribosome reads the mRNA triplet codons, usually beginning with an AUG (adenine−uracil−guanine), or initiator methionine codon downstream of the ribosome binding site. Complexes of initiation factors and elongation factors bring aminoacylatedtransfer RNAs (tRNAs) into the ribosome-mRNA complex, matching the codon in the mRNA to the anti-codon on the tRNA. Each tRNA bears the appropriate amino acid residue to add to the polypeptide chain being synthesised. As the amino acids get linked into the growing peptide chain, the chain begins folding into the correct conformation. Translation ends with a stop codon which may be a UAA, UGA, or UAG triplet.[citation needed]
The mRNA does not contain all the information for specifying the nature of the mature protein. The nascent polypeptide chain released from the ribosome commonly requires additional processing before the final product emerges. For one thing, the correct folding process is complex and vitally important. For most proteins it requires other chaperone proteins to control the form of the product. Some proteins then excise internal segments from their own peptide chains, splicing the free ends that border the gap; in such processes the inside "discarded" sections are called inteins. Other proteins must be split into multiple sections without splicing. Some polypeptide chains need to be cross-linked, and others must be attached to cofactors such as haem (heme) before they become functional.[citation needed]
Additional transfers of biological sequential information
Reverse transcription is the transfer of information from RNA to DNA (the reverse of normal transcription). This is known to occur in the case of retroviruses, such as HIV, as well as in eukaryotes, in the case of retrotransposons and telomere synthesis. It is the process by which genetic information from RNA gets transcribed into new DNA. The family of enzymes involved in this process is called Reverse Transcriptase.[citation needed]
RNA replication is the copying of one RNA to another. Many viruses replicate this way. The enzymes that copy RNA to new RNA, called RNA-dependent RNA polymerases, are also found in many eukaryotes where they are involved in RNA silencing.[11]
RNA editing, in which an RNA sequence is altered by a complex of proteins and a "guide RNA", could also be seen as an RNA-to-RNA transfer.[citation needed]
Activities unrelated to the central dogma
The central dogma of molecular biology states that once sequential information has passed from nucleic acid to protein it cannot flow back from protein to nucleic acid. Some people[who?] believe that the following activities conflict with the central dogma.
After protein amino acid sequences have been translated from nucleic acid chains, they can be edited by appropriate enzymes. This is a form of protein affecting protein sequence not protein transferring information to nucleic acid.[citation needed]
Some proteins are synthesized by nonribosomal peptide synthetases, which can be big protein complexes, each specializing in synthesizing only one type of peptide. Nonribosomal peptides often have cyclic and/or branched structures and can contain non-proteinogenicamino acids - both of these factors differentiate them from ribosome synthesized proteins. An example of nonribosomal peptides are some of the antibiotics.[citation needed]
An intein is a "parasitic" segment of a protein that is able to excise itself from the chain of amino acids as they emerge from the ribosome and rejoin the remaining portions with a peptide bond in such a manner that the main protein "backbone" does not fall apart. This is a case of a protein changing its own primary sequence from the sequence originally encoded by the DNA of a gene. Additionally, most inteins contain a homing endonuclease or HEG domain which is capable of finding a copy of the parent gene that does not include the intein nucleotide sequence. On contact with the intein-free copy, the HEG domain initiates the DNA double-stranded break repair mechanism. This process causes the intein sequence to be copied from the original source gene to the intein-free gene. This is an example of protein directly editing DNA sequence, as well as increasing the sequence's heritable propagation.[citation needed]
Prions are proteins of particular amino acid sequences in particular conformations. They propagate themselves in host cells by making conformational changes in other molecules of protein with the same amino acid sequence, but with a different conformation that is functionally important or detrimental to the organism. Once the protein has been transconformed to the prion folding it changes function. In turn it can convey information into new cells and reconfigure more functional molecules of that sequence into the alternate prion form. In some types of prion in fungi this change is continuous and direct; the information flow is Protein→Protein.[citation needed]
Some scientists such as Alain E. Bussard and Eugene Koonin have argued that prion-mediated inheritance violates the central dogma of molecular biology.[12][13] However, Rosalind Ridley in Molecular Pathology of the Prions (2001) has written that "The prion hypothesis is not heretical to the central dogma of molecular biology—that the information necessary to manufacture proteins is encoded in the nucleotide sequence of nucleic acid—because it does not claim that proteins replicate. Rather, it claims that there is a source of information within protein molecules that contributes to their biological function, and that this information can be passed on to other molecules."[14]
"I called this idea the central dogma, for two reasons, I suspect. I had already used the obvious word hypothesis in the sequence hypothesis, and in addition I wanted to suggest that this new assumption was more central and more powerful. ... As it turned out, the use of the word dogma caused almost more trouble than it was worth. Many years later Jacques Monod pointed out to me that I did not appear to understand the correct use of the word dogma, which is a belief that cannot be doubted. I did apprehend this in a vague sort of way but since I thought that all religious beliefs were without foundation, I used the word the way I myself thought about it, not as most of the world does, and simply applied it to a grand hypothesis that, however plausible, had little direct experimental support."
"My mind was, that a dogma was an idea for which there was no reasonable evidence. You see?!" And Crick gave a roar of delight. "I just didn't know what dogma meant. And I could just as well have called it the 'Central Hypothesis,' or — you know. Which is what I meant to say. Dogma was just a catch phrase."
Comparison with the Weismann barrier
In August Weismann's germ plasm theory, the hereditary material, the germ plasm, is confined to the gonads. Somatic cells (of the body) develop afresh in each generation from the germ plasm. Whatever may happen to those cells does not affect the next generation.
The Weismann barrier, proposed by August Weismann in 1892, distinguishes between the "immortal" germ cell lineages (the germ plasm) which produce gametes and the "disposable" somatic cells. Hereditary information moves only from germline cells to somatic cells (that is, somatic mutations are not inherited). This, before the discovery of the role or structure of DNA, does not predict the central dogma, but does anticipate its gene-centric view of life, albeit in non-molecular terms.[16][17]
↑ Crick FH (1958). "On Protein Synthesis". In F. K. Sanders (ed.). Symposia of the Society for Experimental Biology, Number XII: The Biological Replication of Macromolecules. Cambridge University Press. pp.138–163.
↑ Crick, Francis. H. C. (1958). "On protein synthesis". Symposia of the Society for Experimental Biology. 12. Symposia on the society for Experimental biology number XII: The Biological Replication of Macromolecules. p. 153. PMID13580867.
↑ Cobb, Matthew (2015). Life's Greatest Secret: The Race to Crack the Genetic Code. Basic Books. ISBN978-0-465-06267-6. When Crick enuciated the central dogma, his aim was not to reframe Weismann's division of cells into the somatic line and the germ line, or to defend the modern understanding of evolution by natural selection against the idea of the inheritance of acquired characteristics. The central dogma was based on known or assumed patterns of biochemical information transfer in the cell rather than any dogmatic position. As such it was vulnerable to being invalidated by future discoveries. Nevertheless, in its fundamentals it has been shown to be correct. Real or apparent exceptions to this rule, such as retrotranscription prion disease or transgenerational epigenetic effects have not undermined its basic truth. (p. 263)
↑ Judson HF (1996). "Chapter 6: My mind was, that a dogma was an idea for which there was no reasonable evidence. You see?!". The Eighth Day of Creation: Makers of the Revolution in Biology (25th anniversaryed.). Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. ISBN978-0-87969-477-7.
↑ De Tiège A, Tanghe K, Braeckman J, Van de Peer Y (January 2014). "From DNA- to NA-centrism and the conditions for gene-centrism revisited". Biology & Philosophy. 29 (1): 55–69. doi:10.1007/s10539-013-9393-z. S2CID85866639.
↑ Turner JS (2013). Henning BG, Scarfe AC (eds.). Biology's Second Law: Homeostasis, Purpose, and Desire. Rowman and Littlefield. p.192. ISBN978-0-7391-7436-4. Where Weismann would say that it is impossible for changes acquired during an organism's lifetime to feed back onto transmissible traits in the germ line, the CDMB now added that it was impossible for information encoded in proteins to feed back and affect genetic information in any form whatsoever, which was essentially a molecular recasting of the Weismann barrier.{{cite book}}: |work= ignored (help)
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.