In metagenomics, the genetic materials (DNA, C) are extracted directly from samples taken from the environment (e.g. soil, sea water, human gut, A) after filtering (B), and are sequenced (E) after multiplication by cloning (D) in an approach called shotgun sequencing. These short sequences can then be put together again using assembly methods (F) to deduce the individual genomes or parts of genomes that constitute the original environmental sample. This information can then be used to study the species diversity and functional potential of the microbial community of the environment.
Metagenomics is the study of all genetic material from all organisms in a particular environment, providing insights into their composition, diversity, and functional potential. Metagenomics has allowed researchers to profile the microbial composition of environmental and clinical samples without the need for time-consuming culture of individual species.
Metagenomics has transformed microbial ecology and evolutionary biology by uncovering previously hidden biodiversity and metabolic capabilities. As the cost of DNA sequencing continues to decline, metagenomic studies now routinely profile hundreds to thousands of samples, enabling large-scale exploration of microbial communities and their roles in health and global ecosystems.[2][3][4][5]
Metagenomic studies most commonly employ shotgun sequencing[6] though long-read sequencing is being increasingly utilised as technologies advance.[7] The field is also referred to as environmental genomics, ecogenomics, community genomics, or microbiomics and has significantly expanded the understanding of microbial life beyond what traditional cultivation-based methods can reveal.
Metagenomics is distinct from Amplicon sequencing, also referred to as Metabarcoding or PCR-based sequencing.[8] The main difference is the underlying methodology, since metagenomics targets all DNA in a sample, while Amplicon sequencing amplifies and sequences one or multiple specific genes.[9] Data utilisation also differs between these two approaches. Amplicon sequencing provides mainly community profiles detailing which taxa are present in a sample, whereas metagenomics also recovers encoded enzymes and pathways.[10] Amplicon sequencing was frequently used in early environmental gene sequencing focused on assessing specific highly conserved marker genes, such as the 16S rRNA gene, to profile microbial diversity. These studies demonstrated that the vast majority of microbial biodiversity had been missed by cultivation-based methods.[11]
Etymology
The term "metagenomics" was first used by Jo Handelsman, Robert M. Goodman, Michelle R. Rondon, Jon Clardy, and Sean F. Brady, and first appeared in publication in 1998.[12] The term metagenome referenced the idea that a collection of genes sequenced from the environment could be analyzed in a way analogous to the study of a single genome. In 2005, Kevin Chen and Lior Pachter (researchers at the University of California, Berkeley) defined metagenomics as "the application of modern genomics technique without the need for isolation and lab cultivation of individual species".[13]
Conventional sequencing begins with a culture of identical cells as a source of DNA. However, early metagenomic studies revealed that there are probably large groups of microorganisms in many environments that cannot be cultured and thus cannot be sequenced. These early studies focused on 16S ribosomalRNA (rRNA) sequences which are relatively short, often conserved within a species, and generally different between species. Many 16S rRNA sequences have been found which do not belong to any known cultured species, indicating that there are numerous non-isolated organisms. These surveys of ribosomal RNA genes taken directly from the environment revealed that cultivation based methods find less than 1% of the bacterial and archaeal species in a sample.[11] Much of the interest in metagenomics comes from these discoveries that showed that the vast majority of microorganisms had previously gone unnoticed.
In the 1980s early molecular work in the field was conducted by Norman R. Pace and colleagues, who used PCR to explore the diversity of ribosomal RNA sequences.[14] The insights gained from these breakthrough studies led Pace to propose the idea of cloning DNA directly from environmental samples as early as 1985.[15] This led to the first report of isolating and cloning bulk DNA from an environmental sample, published by Pace and colleagues in 1991[16] while Pace was in the Department of Biology at Indiana University. Considerable efforts ensured that these were not PCR false positives and supported the existence of a complex community of unexplored species. Although this methodology was limited to exploring highly conserved, non-protein coding genes, it did support early microbial morphology-based observations that diversity was far more complex than was known by culturing methods. Soon after that in 1995, Healy reported the metagenomic isolation of functional genes from "zoolibraries" constructed from a complex culture of environmental organisms grown in the laboratory on dried grasses.[17] After leaving the Pace laboratory, Edward DeLong continued in the field and has published work that has largely laid the groundwork for environmental phylogenies based on signature 16S sequences, beginning with his group's construction of libraries from marine samples.[18]
In 2002, Mya Breitbart, Forest Rohwer, and colleagues used environmental shotgun sequencing (see below) to show that 200 liters of seawater contains over 5000 different viruses.[19] Subsequent studies showed that there are more than a thousand viral species in human stool and possibly a million different viruses per kilogram of marine sediment, including many bacteriophages. Essentially all of the viruses in these studies were new species. In 2004, Gene Tyson, Jill Banfield, and colleagues at the University of California, Berkeley and the Joint Genome Institute sequenced DNA extracted from an acid mine drainage system.[20] This effort resulted in the complete, or nearly complete, genomes for a handful of bacteria and archaea that had previously resisted attempts to culture them.[21]
Beginning in 2003, Craig Venter, leader of the privately funded parallel of the Human Genome Project, has led the Global Ocean Sampling Expedition (GOS), circumnavigating the globe and collecting metagenomic samples throughout the journey. All of these samples were sequenced using shotgun sequencing, in hopes that new genomes (and therefore new organisms) would be identified. The pilot project, conducted in the Sargasso Sea, found DNA from nearly 2000 different species, including 148 types of bacteria never before seen.[22] Venter thoroughly explored the West Coast of the United States, and completed a two-year expedition in 2006 to explore the Baltic, Mediterranean, and Black Seas. Analysis of the metagenomic data collected during this journey revealed two groups of organisms, one composed of taxa adapted to environmental conditions of 'feast or famine', and a second composed of relatively fewer but more abundantly and widely distributed taxa primarily composed of plankton.[23]
As of 2025[update] there are few metagenomics laboratories in the world; for example, in the UK only the metagenomics labs at Great Ormond Street Hospital is recognised to carry out these tests. The cost is high (quoted as £1,300 in 2025), but this is expected to drop as the technology is developed.[26]
Advances in bioinformatics, refinements of DNA amplification, and the proliferation of computational power have greatly aided the analysis of DNA sequences recovered from environmental samples, allowing the adaptation of shotgun sequencing to metagenomic samples (known also as whole metagenome shotgun or WMGS sequencing). The approach, used to sequence many cultured microorganisms and the human genome, randomly shears DNA, sequences many short sequences, and reconstructs them into a consensus sequence. Shotgun sequencing reveals genes present in environmental samples. Historically, clone libraries were used to facilitate this sequencing. However, with advances in high throughput sequencing technologies, the cloning step is no longer necessary and greater yields of sequencing data can be obtained without this labour-intensive bottleneck step. Shotgun metagenomics provides information both about which organisms are present and what metabolic processes are possible in the community.[29] Because the collection of DNA from an environment is largely uncontrolled, the most abundant organisms in an environmental sample are most highly represented in the resulting sequence data. To achieve the high coverage needed to fully resolve the genomes of under-represented community members, large samples, often prohibitively so, are needed. On the other hand, the random nature of shotgun sequencing ensures that many of these organisms, which would otherwise go unnoticed using traditional culturing techniques, will be represented by at least some small sequence segments.[20]
High-throughput sequencing
An advantage to high throughput sequencing is that this technique does not require cloning the DNA before sequencing, removing one of the main biases and bottlenecks in environmental sampling. The first metagenomic studies conducted using high-throughput sequencing used massively parallel 454 pyrosequencing.[24] Three other technologies commonly applied to environmental sampling are the Ion Torrent Personal Genome Machine, the Illumina MiSeq or HiSeq and the Applied Biosystems SOLiD system.[30] These techniques for sequencing DNA generate shorter fragments than Sanger sequencing; Ion Torrent PGM System and 454 pyrosequencing typically produces ~400bp reads, Illumina MiSeq produces 400-700bp reads (depending on whether paired end options are used), and SOLiD produce 25–75bp reads.[31] Historically, these read lengths were significantly shorter than the typical Sanger sequencing read length of ~750bp, however the Illumina technology is quickly coming close to this benchmark. However, this limitation is compensated for by the much larger number of sequence reads. In 2009, pyrosequenced metagenomes generate 200–500megabases, and Illumina platforms generate around 20–50gigabases, but these outputs have increased by orders of magnitude in recent years.[32]
To achieve higher resolution and more complete assemblies from complex environmental samples, the field has adopted several advanced techniques.[2] One approach combines shotgun sequencing and chromosome conformation capture (Hi-C), which measures the proximity of any two DNA sequences within the same cell, to guide microbial genome assembly.[33] Another technique is single-cell metagenomic sequencing, which resolves the heterogeneity present within the community.[2] Additionally, long read sequencing technologies, such as those from Pacific Biosciences (PacBio RSII and Sequel) and Oxford Nanopore Technologies (MinION, GridION, PromethION), generate significantly longer reads that simplify the assembly process, particularly in repetitive or structurally complex regions.[34][35]
Sequencing depth
An important consideration when sequencing for metagenomics is sequencing depth, the number of times each base is read by the sequencer; it can be thought of as resolution. The higher the sequencing depth, the larger the resultant file and number of contigs, and the higher the number of microbial genomes recovered. Higher depth metagenomes have been shown to have exceptionally high genome recovery, with tremendous novelty being reported.[36] Low depth metagenomes have lower resolution on every taxonomic level than high depth samples.[37]
Bioinformatics
This section is missing information about quality assessment: on assembly (N50, MetaQUAST), on genome (universal single-copy marker genes – CheckM and BUSCO). Please expand the section to include this information. Further details may exist on the talk page.(February 2022)
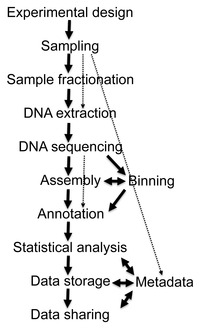
Schematic representation of the main steps necessary for the analysis of whole metagenome shotgun sequencing-derived data. The software related to each step is shown in italics.
The data generated by metagenomics experiments are both enormous and inherently noisy, containing fragmented data representing as many as 10,000 species.[1] The sequencing of the cow rumen metagenome generated 279 gigabases, or 279 billion base pairs of nucleotide sequence data,[39] while the human gut microbiome gene catalog identified 3.3 million genes assembled from 567.7 gigabases of sequence data.[40] Collecting, curating, and extracting useful biological information from datasets of this size represent significant computational challenges for researchers.[29][41][42][43]
Sequence pre-filtering
The first step of metagenomic data analysis requires the execution of certain pre-filtering steps, including the removal of redundant, low-quality sequences and sequences of probable eukaryotic origin (especially in metagenomes of human origin).[44][45] The methods available for the removal of contaminating eukaryotic genomic DNA sequences include Eu-Detect and DeConseq.[46][47]
DNA sequence data from genomic and metagenomic projects are essentially the same, but genomic sequence data offers higher coverage while metagenomic data is usually highly non-redundant.[42] Furthermore, the increased use of second-generation sequencing technologies with short read lengths means that much of future metagenomic data will be error-prone. Taken in combination, these factors make the assembly of metagenomic sequence reads into genomes difficult and unreliable. Misassemblies are caused by the presence of repetitive DNA sequences that make assembly especially difficult because of the difference in the relative abundance of species present in the sample.[48] Misassemblies can also involve the combination of sequences from more than one species into chimeric contigs.[48]
There are several assembly programs, most of which can use information from paired-end tags in order to improve the accuracy of assemblies. Some programs, such as Phrap or Celera Assembler, were designed to be used to assemble single genomes but nevertheless produce good results when assembling metagenomic data sets.[1] Other programs, such as Velvet assembler, have been optimized for the shorter reads produced by second-generation sequencing through the use of de Bruijn graphs.[49][50] The use of reference genomes allows researchers to improve the assembly of the most abundant microbial species, but this approach is limited by the small subset of microbial phyla for which sequenced genomes are available.[48] After an assembly is created, an additional challenge is "metagenomic deconvolution", or determining which sequences come from which species in the sample.[51]
Gene annotations provide the "what", while measurements of species diversity provide the "who".[52] In order to connect community composition and function in metagenomes, sequences must be binned. Binning is the process of associating a particular sequence with an organism.[48] In similarity-based binning, methods such as BLAST are used to rapidly search for phylogenetic markers or otherwise similar sequences in existing public databases. This approach is implemented in MEGAN.[53] Another tool, PhymmBL, uses interpolated Markov models to assign reads.[1]MetaPhlAn and AMPHORA are methods based on unique clade-specific markers for estimating organismal relative abundances with improved computational performances.[54] Other tools, like mOTUs[55][56] and MetaPhyler,[57] use universal marker genes to profile prokaryotic species. With the mOTUs profiler is possible to profile species without a reference genome, improving the estimation of microbial community diversity.[56] Recent methods, such as SLIMM, use read coverage landscape of individual reference genomes to minimize false-positive hits and get reliable relative abundances.[58] In composition based binning, methods use intrinsic features of the sequence, such as oligonucleotide frequencies or codon usage bias.[1] Once sequences are binned, it is possible to carry out comparative analysis of diversity and richness.
After binning, assembled contigs are collected into "bins" each representing a species-like collection of organisms (see: operational taxonomic unit), to the best ability of the binning tool. Each bin consists of a metagenome-assembled genome (MAG), as all included sequences can be thought of being derived from the genome of the organism being represented. Tools based on single-copy genes such as CheckM and BUSCO can then be used to estimate the completeness percentage and contamination percentage of the MAG.[59]
Metagenomic analysis pipelines use two approaches in the annotation of coding regions in the assembled contigs.[48] The first approach is to identify genes based upon homology with genes that are already publicly available in sequence databases, usually by BLAST searches. This type of approach is implemented in the program MEGAN4.[60] The second, ab initio, uses intrinsic features of the sequence to predict coding regions based upon gene training sets from related organisms. This is the approach taken by programs such as GeneMark[61] and GLIMMER. The main advantage of ab initio prediction is that it enables the detection of coding regions that lack homologs in the sequence databases; however, it is most accurate when there are large regions of contiguous genomic DNA available for comparison.[1] Gene prediction is usually done after binning.[38]
Comparative metagenomics
Comparative metagenomics involves analyzing differences in the taxonomic and functional composition of microbial communities across multiple samples or conditions. When focusing on features that vary between groups, this is often referred to as differential abundance analysis.[62] Comparative analyses of metagenomes provide insights into how microbial communities vary across environments or hosts, helping to link community structure and function to ecological or health-related outcomes.[63] Metagenomes are most commonly compared by analyzing taxonomic composition—such as differences in normalized species or genus abundance between groups— or taxonomic diversity, but can also be compared by sequence features such as k-mer profiles.[64] Metadata on the environmental context of the metagenomic sample is important in comparative analyses, as it provides researchers with the ability to study the effect of habitat upon community structure and function.[1]
Functional comparisons between metagenomes often involve profiling gene families or pathways using tools like HUMAnN3[65] or gutSMASH,[66] which map reads to reference databases (e.g. KEGG, COG) or detect biosynthetic/metabolic gene clusters, enabling statistical comparison of functional potential across samples. This gene-centric approach emphasizes the functional complement of the community as a whole rather than taxonomic groups, and shows that the functional complements are analogous under similar environmental conditions.[67]
Data analysis
Community metabolism
In many bacterial communities, natural or engineered (such as bioreactors), there is significant division of labor in metabolism (syntrophy), during which the waste products of some organisms are metabolites for others.[68] In one such system, the methanogenic bioreactor, functional stability requires the presence of several syntrophic species (Syntrophobacterales and Synergistia) working together in order to turn raw resources into fully metabolized waste (methane).[69] Using comparative gene studies and expression experiments with microarrays or proteomics researchers can piece together a metabolic network that goes beyond species boundaries. Such studies require detailed knowledge about which versions of which proteins are coded by which species and even by which strains of which species. Therefore, community genomic information is another fundamental tool (with metabolomics and proteomics) in the quest to determine how metabolites are transferred and transformed by a community.[70]
Metagenomics allows researchers to access the functional and metabolic diversity of microbial communities, but it cannot show which of these processes are active.[67] The extraction and analysis of metagenomic mRNA (the metatranscriptome) provides information on the regulation and expression profiles of complex communities. Because of the technical difficulties (the short half-life of mRNA, for example) in the collection of environmental RNA there have been relatively few in situ metatranscriptomic studies of microbial communities to date.[67] While originally limited to microarray technology, metatranscriptomics studies have made use of transcriptomics technologies to measure whole-genome expression and quantification of a microbial community,[67] first employed in analysis of ammonia oxidation in soils.[71]
Metagenomic sequencing is particularly useful in the study of viral communities. As viruses lack a shared universal phylogenetic marker (as 16S RNA for bacteria and archaea, and 18S RNA for eukarya), the only way to access the genetic diversity of the viral community from an environmental sample is through metagenomics. Viral metagenomes (also called viromes) should thus provide more and more information about viral diversity and evolution.[72][73][74][75][76] For example, a metagenomic pipeline called Giant Virus Finder showed the first evidence of existence of giant viruses in a saline desert[77] and in Antarctic dry valleys.[78]
The soils in which plants grow are inhabited by microbial communities, with one gram of soil containing around 109-1010 microbial cells which comprise about one gigabase of sequence information.[80][81] The microbial communities which inhabit soils are some of the most complex known to science, and remain poorly understood despite their economic importance.[82]Microbial consortia perform a wide variety of ecosystem services necessary for plant growth, including fixing atmospheric nitrogen, nutrient cycling, disease suppression, and sequesteriron and other metals.[83] Functional metagenomics strategies are being used to explore the interactions between plants and microbes through cultivation-independent study of these microbial communities.[84][85] By allowing insights into the role of previously uncultivated or rare community members in nutrient cycling and the promotion of plant growth, metagenomic approaches can contribute to improved disease detection in crops and livestock and the adaptation of enhanced farming practices which improve crop health by harnessing the relationship between microbes and plants.[42]
The efficient industrial-scale deconstruction of biomass requires novel enzymes with higher productivity and lower cost.[39] Metagenomic approaches to the analysis of complex microbial communities allow the targeted screening of enzymes with industrial applications in biofuel production, such as glycoside hydrolases.[86] Furthermore, knowledge of how these microbial communities function is required to control them, and metagenomics is a key tool in their understanding. Metagenomic approaches allow comparative analyses between convergent microbial systems like biogas fermenters[87] or insectherbivores such as the fungus garden of the leafcutter ants.[88]
Biotechnology
Microbial communities produce a vast array of biologically active chemicals that are used in competition and communication.[83] Many of the drugs in use today were originally uncovered in microbes; recent progress in mining the rich genetic resource of non-culturable microbes has led to the discovery of new genes, enzymes, and natural products.[67][89] The application of metagenomics has allowed the development of commodity and fine chemicals, agrochemicals and pharmaceuticals where the benefit of enzyme-catalyzedchiral synthesis is increasingly recognized.[90]
Two types of analysis are used in the bioprospecting of metagenomic data: function-driven screening for an expressed trait, and sequence-driven screening for DNA sequences of interest.[91] Function-driven analysis seeks to identify clones expressing a desired trait or useful activity, followed by biochemical characterization and sequence analysis. This approach is limited by availability of a suitable screen and the requirement that the desired trait be expressed in the host cell. Moreover, the low rate of discovery (less than one per 1,000 clones screened) and its labor-intensive nature further limit this approach.[92] In contrast, sequence-driven analysis uses conserved DNA sequences to design PCR primers to screen clones for the sequence of interest.[91] In comparison to cloning-based approaches, using a sequence-only approach further reduces the amount of bench work required. The application of massively parallel sequencing also greatly increases the amount of sequence data generated, which require high-throughput bioinformatic analysis pipelines.[92] The sequence-driven approach to screening is limited by the breadth and accuracy of gene functions present in public sequence databases. In practice, experiments make use of a combination of both functional and sequence-based approaches based upon the function of interest, the complexity of the sample to be screened, and other factors.[92][93] An example of success using metagenomics as a biotechnology for drug discovery is illustrated with the malacidin antibiotics.[94]
Ecology
Metagenomics allows the study of microbial communities like those present in this stream receiving acid drainage from surface coal mining.
Metagenomics can provide valuable insights into the functional ecology of environmental communities.[95] Metagenomic analysis of the bacterial consortia found in the defecations of Australian sea lions suggests that nutrient-rich sea lion faeces may be an important nutrient source for coastal ecosystems. This is because the bacteria that are expelled simultaneously with the defecations are adept at breaking down the nutrients in the faeces into a bioavailable form that can be taken up into the food chain.[96]
DNA sequencing can also be used more broadly to identify species present in a body of water,[97] debris filtered from the air, sample of dirt, or animal's faeces,[98] and even detect diet items from blood meals.[99] This can establish the range of invasive species and endangered species, and track seasonal populations.
Furthermore, metagenomics is utilized to assess the ecological impacts of anthropogenic pollution on environmental microbiomes. For instance, long-read whole-metagenome sequencing of soils in industrial technogenic zones has revealed that chronic heavy metal contamination fundamentally restructures the soil microbial community. Rather than significantly reducing overall biodiversity, intense environmental pressures drive strain-level adaptations, selecting for metal-resistant taxa and suppressing vulnerable phyla, which provides high-resolution insights into the natural bioremediation potential of polluted ecosystems.[100]
Metagenomics can improve strategies for monitoring the impact of pollutants on ecosystems and for cleaning up contaminated environments. Increased understanding of how microbial communities cope with pollutants improves assessments of the potential of contaminated sites to recover from pollution and increases the chances of bioaugmentation or biostimulation trials to succeed.[101]
Gut microbe characterization
Microbial communities play a key role in preserving human health, but their composition and the mechanism by which they do so remains mysterious.[102] Metagenomic sequencing is being used to characterize the microbial communities from 15 to 18 body sites from at least 250 individuals. This is part of the Human Microbiome initiative with primary goals to determine if there is a core human microbiome, to understand the changes in the human microbiome that can be correlated with human health, and to develop new technological and bioinformatics tools to support these goals.[103]
Another medical study as part of the MetaHit (Metagenomics of the Human Intestinal Tract) project consisted of 124 individuals from Denmark and Spain consisting of healthy, overweight, and irritable bowel disease patients.[104] The study attempted to categorize the depth and phylogenetic diversity of gastrointestinal bacteria. Using Illumina GA sequence data and SOAPdenovo, a de Bruijn graph-based tool specifically designed for assembly short reads, they were able to generate 6.58 million contigs greater than 500 bp for a total contig length of 10.3 Gb and a N50 length of 2.2 kb.
The study demonstrated that two bacterial divisions, Bacteroidetes and Firmicutes, constitute over 90% of the known phylogenetic categories that dominate distal gut bacteria. Using the relative gene frequencies found within the gut these researchers identified 1,244 metagenomic clusters that are critically important for the health of the intestinal tract. There are two types of functions in these range clusters: housekeeping and those specific to the intestine. The housekeeping gene clusters are required in all bacteria and are often major players in the main metabolic pathways including central carbon metabolism and amino acid synthesis. The gut-specific functions include adhesion to host proteins and the harvesting of sugars from globoseries glycolipids. Patients with irritable bowel syndrome were shown to exhibit 25% fewer genes and lower bacterial diversity than individuals not suffering from irritable bowel syndrome indicating that changes in patients' gut biome diversity may be associated with this condition.[104]
While these studies highlight some potentially valuable medical applications, only 31–48.8% of the reads could be aligned to 194 public human gut bacterial genomes and 7.6–21.2% to bacterial genomes available in GenBank which indicates that there is still far more research necessary to capture novel bacterial genomes.[105]
In the Human Microbiome Project (HMP), gut microbial communities were assayed using high-throughput DNA sequencing. HMP showed that, unlike individual microbial species, many metabolic processes were present among all body habitats with varying frequencies. Microbial communities of 649 metagenomes drawn from seven primary body sites on 102 individuals were studied as part of the human microbiome project. The metagenomic analysis revealed variations in niche specific abundance among 168 functional modules and 196 metabolic pathways within the microbiome. These included glycosaminoglycan degradation in the gut, as well as phosphate and amino acid transport linked to host phenotype (vaginal pH) in the posterior fornix. The HMP has brought to light the utility of metagenomics in diagnostics and evidence-based medicine. Thus metagenomics is a powerful tool to address many of the pressing issues in the field of personalized medicine.[106]
In animals, metagenomics can be used to profile their gut microbiomes and enable detection of antibiotic-resistant bacteria.[107] This can have implications in monitoring the spread of diseases from wildlife to farmed animals and humans.
Infectious disease diagnosis
Differentiating between infectious and non-infectious illness, and identifying the underlying etiology of infection, can be challenging. For example, more than half of cases of encephalitis remain undiagnosed, despite extensive testing using state-of-the-art clinical laboratory methods. Clinical metagenomic sequencing shows promise as a sensitive and rapid method to diagnose infection by comparing genetic material found in a patient's sample to databases of all known microscopic human pathogens and thousands of other bacterial, viral, fungal, and parasitic organisms and databases on antimicrobial resistances gene sequences with associated clinical phenotypes.[108][109][110]
Arbovirus surveillance
Metagenomics is helpful to characterize the diversity and ecology of viruses spread by hematophagous (blood-feeding) arthropods such as mosquitoes and ticks, called arboviruses. It can also be used as a tool by public health officials and organizations to surveil arboviruses in circulation in wild arthropod populations.[109][111]
Dietary estimation
Metagenomic Estimation of Dietary Intake (MEDI), enables reconstruction of individual dietary profiles by detecting food-derived DNA in human stool metagenomes.[112] MEDI has shown concordance with food frequency questionnaires, tracked dietary shifts in infants, and identified diet–health associations in large cohorts without dietary records.
↑Pace NR, Stahl DA, Lane DJ, Olsen GJ (1986). "The Analysis of Natural Microbial Populations by Ribosomal RNA Sequences". In Marshall KC (ed.). Advances in Microbial Ecology. Vol.9. Springer US. pp.1–55. doi:10.1007/978-1-4757-0611-6_1. ISBN978-1-4757-0611-6.
↑Charles T (2010). "The Potential for Investigation of Plant-microbe Interactions Using Metagenomics Methods". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN978-1-904455-54-7.
↑Wong D (2010). "Applications of Metagenomics for Industrial Bioproducts". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN978-1-904455-54-7.
↑George I, Stenuit B, Agathos SN (2010). "Application of Metagenomics to Bioremediation". In Marco D (ed.). Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN978-1-904455-54-7.
↑Nelson KE and White BA (2010). "Metagenomics and Its Applications to the Study of the Human Microbiome". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN978-1-904455-54-7.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.