The likelihood function is the joint probability of observed data viewed as a function of the parameters of a statistical model.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
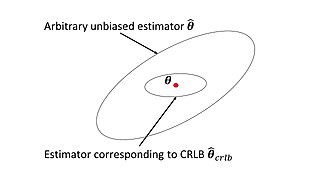
In estimation theory and statistics, the Cramér–Rao bound (CRB) relates to estimation of a deterministic parameter. The result is named in honor of Harald Cramér and C. R. Rao, but has also been derived independently by Maurice Fréchet, Georges Darmois, and by Alexander Aitken and Harold Silverstone. It states that the precision of any unbiased estimator is at most the Fisher information; or (equivalently) the reciprocal of the Fisher information is a lower bound on its variance.
In statistics, the informant is the gradient of the log-likelihood function with respect to the parameter vector. Evaluated at a particular point of the parameter vector, the score indicates the steepness of the log-likelihood function and thereby the sensitivity to infinitesimal changes to the parameter values. If the log-likelihood function is continuous over the parameter space, the score will vanish at a local maximum or minimum; this fact is used in maximum likelihood estimation to find the parameter values that maximize the likelihood function.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
Estimation theory is a branch of statistics that deals with estimating the values of parameters based on measured empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation theory, two approaches are generally considered:
In statistics, the score test assesses constraints on statistical parameters based on the gradient of the likelihood function—known as the score—evaluated at the hypothesized parameter value under the null hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ from zero by more than sampling error. While the finite sample distributions of score tests are generally unknown, they have an asymptotic χ2-distribution under the null hypothesis as first proved by C. R. Rao in 1948, a fact that can be used to determine statistical significance.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative prior distribution for a parameter space; its density function is proportional to the square root of the determinant of the Fisher information matrix:
In statistics, the method of moments is a method of estimation of population parameters. The same principle is used to derive higher moments like skewness and kurtosis.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
Scoring algorithm, also known as Fisher's scoring, is a form of Newton's method used in statistics to solve maximum likelihood equations numerically, named after Ronald Fisher.
In statistics, the Hájek–Le Cam convolution theorem states that any regular estimator in a parametric model is asymptotically equivalent to a sum of two independent random variables, one of which is normal with asymptotic variance equal to the inverse of Fisher information, and the other having arbitrary distribution.
In statistics, an adaptive estimator is an estimator in a parametric or semiparametric model with nuisance parameters such that the presence of these nuisance parameters does not affect efficiency of estimation.
In statistics, efficiency is a measure of quality of an estimator, of an experimental design, or of a hypothesis testing procedure. Essentially, a more efficient estimator needs fewer input data or observations than a less efficient one to achieve the Cramér–Rao bound. An efficient estimator is characterized by having the smallest possible variance, indicating that there is a small deviance between the estimated value and the "true" value in the L2 norm sense.
In statistics, the variance function is a smooth function that depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
In statistics, the class of vector generalized linear models (VGLMs) was proposed to enlarge the scope of models catered for by generalized linear models (GLMs). In particular, VGLMs allow for response variables outside the classical exponential family and for more than one parameter. Each parameter can be transformed by a link function. The VGLM framework is also large enough to naturally accommodate multiple responses; these are several independent responses each coming from a particular statistical distribution with possibly different parameter values.
Laplace's approximation provides an analytical expression for a posterior probability distribution by fitting a Gaussian distribution with a mean equal to the MAP solution and precision equal to the observed Fisher information. The approximation is justified by the Bernstein–von Mises theorem, which states that under regularity conditions the posterior converges to a Gaussian in large samples.











