Related Research Articles
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
Interactive voice response (IVR) is a technology that allows telephone users to interact with a computer-operated telephone system through the use of voice and DTMF tones input with a keypad. In telephony, IVR allows customers to interact with a company's host system via a telephone keypad or by speech recognition, after which services can be inquired about through the IVR dialogue. IVR systems can respond with pre-recorded or dynamically generated audio to further direct users on how to proceed. IVR systems deployed in the network are sized to handle large call volumes and also used for outbound calling as IVR systems are more intelligent than many predictive dialer systems.

Affective computing is the study and development of systems and devices that can recognize, interpret, process, and simulate human affects. It is an interdisciplinary field spanning computer science, psychology, and cognitive science. While some core ideas in the field may be traced as far back as to early philosophical inquiries into emotion, the more modern branch of computer science originated with Rosalind Picard's 1995 paper entitled "Affective Computing" and her 1997 book of the same name published by MIT Press. One of the motivations for the research is the ability to give machines emotional intelligence, including to simulate empathy. The machine should interpret the emotional state of humans and adapt its behavior to them, giving an appropriate response to those emotions.
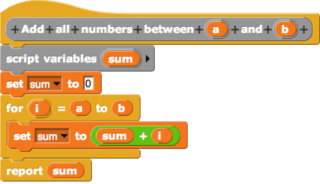
In computing, a visual programming language, also known as diagrammatic programming, graphical programming or block coding, is a programming language that lets users create programs by manipulating program elements graphically rather than by specifying them textually. A VPL allows programming with visual expressions, spatial arrangements of text and graphic symbols, used either as elements of syntax or secondary notation. For example, many VPLs are based on the idea of "boxes and arrows", where boxes or other screen objects are treated as entities, connected by arrows, lines or arcs which represent relations. VPLs are generally the basis of low-code development platforms.
A multimedia framework is a software framework that handles media on a computer and through a network. A good multimedia framework offers an intuitive API and a modular architecture to easily add support for new audio, video and container formats and transmission protocols. It is meant to be used by applications such as media players and audio or video editors, but can also be used to build videoconferencing applications, media converters and other multimedia tools. Data is processed among modules automatically, it is unnecessary for app to pass buffers between connected modules one by one.
Multimodal interaction provides the user with multiple modes of interacting with a system. A multimodal interface provides several distinct tools for input and output of data.

Thomas Shi-Tao Huang was a Chinese-born Taiwanese-American computer scientist and electrical engineer. He was a researcher and professor emeritus at the University of Illinois at Urbana-Champaign (UIUC). Huang was one of the leading figures in computer vision, pattern recognition and human computer interaction.
Automatic pronunciation assessment is the use of speech recognition to verify the correctness of pronounced speech, as distinguished from manual assessment by an instructor or proctor. Also called speech verification, pronunciation evaluation, and pronunciation scoring, the main application of this technology is computer-aided pronunciation teaching (CAPT) when combined with computer-aided instruction for computer-assisted language learning (CALL), speech remediation, or accent reduction.
As of the early 2000s, several speech recognition (SR) software packages exist for Linux. Some of them are free and open-source software and others are proprietary software. Speech recognition usually refers to software that attempts to distinguish thousands of words in a human language. Voice control may refer to software used for communicating operational commands to a computer.
ACM Multimedia (ACM-MM) is the Association for Computing Machinery (ACM)'s annual conference on multimedia, sponsored by the SIGMM special interest group on multimedia in the ACM. SIGMM specializes in the field of multimedia computing, from underlying technologies to applications, theory to practice, and servers to networks to devices.
RWTH ASR is a proprietary speech recognition toolkit.
Julia Hirschberg is an American computer scientist noted for her research on computational linguistics and natural language processing.
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
Multimodal sentiment analysis is a technology for traditional text-based sentiment analysis, which includes modalities such as audio and visual data. It can be bimodal, which includes different combinations of two modalities, or trimodal, which incorporates three modalities. With the extensive amount of social media data available online in different forms such as videos and images, the conventional text-based sentiment analysis has evolved into more complex models of multimodal sentiment analysis, which can be applied in the development of virtual assistants, analysis of YouTube movie reviews, analysis of news videos, and emotion recognition such as depression monitoring, among others.
Personality computing is a research field related to artificial intelligence and personality psychology that studies personality by means of computational techniques from different sources, including text, multimedia, and social networks.

Voice computing is the discipline that develops hardware or software to process voice inputs.

Björn Wolfgang Schuller is a scientist of electrical engineering, information technology and computer science as well as entrepreneur. He is professor of artificial intelligence at Imperial College London., UK, and holds the chair of embedded intelligence for healthcare and wellbeing at the University of Augsburg in Germany. He was a university professor and holder of the chair of complex and intelligent systems at the University of Passau in Germany. He is also co-founder and managing director as well as the current chief scientific officer (CSO) of audEERING GmbH, Germany, as well as permanent visiting professor at the Harbin Institute of Technology in the People's Republic of China and associate of CISA at the University of Geneva in French-speaking Switzerland.
Emily Mower Provost is a professor of computer science at the University of Michigan. She directs the Computational Human-Centered Artificial Intelligence (CHAI) Laboratory.
Apps to analyse COVID-19 sounds are mobile software applications designed to collect respiratory sounds and aid diagnosis in response to the COVID-19 pandemic. Numerous applications are in development, with different institutions and companies taking various approaches to privacy and data collection. Current efforts are aimed at gathering data. In a later stage, it is possible that sound apps will have the capacity to provide information back to users. In order to develop and train signal analysis approaches, large datasets are required.
References
- ↑ "Release openSMILE 3.0.1" . Retrieved 5 January 2022.
- ↑ F. Eyben, M. Wöllmer, B. Schuller: „openSMILE - The Munich Versatile and Fast Open-Source Audio Feature Extractor“, In Proc. ACM Multimedia (MM), ACM, Florence, Italy, ACM, pp. 1459-1462, October 2010.
- ↑ B. Schuller, B. Vlasenko, F. Eyben, M. Wöllmer, A. Stuhlsatz, A. Wendemuth, G. Rigoll, "Cross-Corpus Acoustic Emotion Recognition: Variances and Strategies (Extended Abstract)," in Proc. of ACII 2015, Xi'an, China, invited for the Special Session on Most Influential Articles in IEEE Transactions on Affective Computing.
- ↑ B. Schuller, S. Steidl, A. Batliner, J. Hirschberg, J. K. Burgoon, A. Elkins, Y. Zhang, E. Coutinho: "The INTERSPEECH 2016 Computational Paralinguistics Challenge: Deception & Sincerity Archived 2017-06-09 at the Wayback Machine ", Proceedings INTERSPEECH 2016, ISCA, San Francisco, USA, 2016.
- ↑ F. Ringeval, B. Schuller, M. Valstar, R. Cowie, M. Pantic, “AVEC 2015 - The 5th International Audio/Visual Emotion Challenge and Workshop,” in Proceedings of the 23rd ACM International Conference on Multimedia, MM 2015, (Brisbane, Australia), ACM, October 2015.
- ↑ M. Eskevich, R. Aly, D. Racca, R. Ordelman, S. Chen, G. J. Jones, "The search and hyperlinking task at MediaEval 2014".
- ↑ F. Ringeval, S. Amiriparian, F. Eyben, K. Scherer, B. Schuller, “Emotion Recognition in the Wild: Incorporating Voice and Lip Activity in Multimodal Decision-Level Fusion,” in Proceedings of the ICMI 2014 EmotiW – Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2014), Satellite of the 16th ACM International Conference on Multimodal Interaction (ICMI 2014), (Istanbul, Turkey), pp. 473– 480, ACM, November 2014
- ↑ Eyben, Florian; Wöllmer, Martin; Schuller, Björn (26 April 2018). Opensmile: the munich versatile and fast open-source audio feature extractor. ACM. pp. 1459–1462. doi:10.1145/1873951.1874246. ISBN 978-1-60558-933-6 – via Google Scholar.
- ↑ Eyben, Florian; Wöllmer, Martin; Schuller, Björn (26 April 2018). "OpenEAR—introducing the Munich open-source emotion and affect recognition toolkit". IEEE. pp. 1–6 – via Google Scholar.