
The Open Archives Initiative (OAI) was an informal organization, in the circle around the colleagues Herbert Van de Sompel, Carl Lagoze, Michael L. Nelson and Simeon Warner, to develop and apply technical interoperability standards for archives to share catalogue information (metadata). The group got together in the late late 1990s and was active for around twenty years. OAI coordinated in particular three specification activities: OAI-PMH, OAI-ORE and ResourceSync. All along the group worked towards building a "low-barrier interoperability framework" for archives containing digital content to allow people harvest metadata. Such sets of metadata are since then harvested to provide "value-added services", often by combining different data sets.
Electronic publishing includes the digital publication of e-books, digital magazines, and the development of digital libraries and catalogues. It also includes an editorial aspect, that consists of editing books, journals or magazines that are mostly destined to be read on a screen.
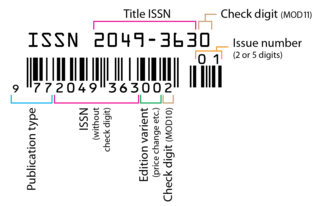
An International Standard Serial Number (ISSN) is an eight-digit serial number used to uniquely identify a serial publication, such as a magazine. The ISSN is especially helpful in distinguishing between serials with the same title. ISSNs are used in ordering, cataloging, interlibrary loans, and other practices in connection with serial literature.
This page is a glossary of library and information science.

A digital object identifier (DOI) is a persistent identifier or handle used to identify objects uniquely, standardized by the International Organization for Standardization (ISO). An implementation of the Handle System, DOIs are in wide use mainly to identify academic, professional, and government information, such as journal articles, research reports, data sets, and official publications. However, they also have been used to identify other types of information resources, such as commercial videos.
An institutional repository is an archive for collecting, preserving, and disseminating digital copies of the intellectual output of an institution, particularly a research institution.
Enterprise content management (ECM) extends the concept of content management by adding a timeline for each content item and, possibly, enforcing processes for its creation, approval and distribution. Systems using ECM generally provide a secure repository for managed items, analog or digital. They also include one methods for importing content to bring manage new items, and several presentation methods to make items available for use. Although ECM content may be protected by digital rights management (DRM), it is not required. ECM is distinguished from general content management by its cognizance of the processes and procedures of the enterprise for which it is created.
An OpenURL is similar to a web address, but instead of referring to a physical website, it refers to an article, book, patent, or other resource within a website.

Digital accessible information system (DAISY) is a technical standard for digital audiobooks, periodicals, and computerized text. DAISY is designed to be a complete audio substitute for print material and is specifically designed for use by people with "print disabilities", including blindness, impaired vision, and dyslexia. Based on the MP3 and XML formats, the DAISY format has advanced features in addition to those of a traditional audio book. Users can search, place bookmarks, precisely navigate line by line, and regulate the speaking speed without distortion. DAISY also provides aurally accessible tables, references, and additional information. As a result, DAISY allows visually impaired listeners to navigate something as complex as an encyclopedia or textbook, otherwise impossible using conventional audio recordings.
Serials Solutions was a division of ProQuest that provided e-resource access and management services (ERAMS) to libraries. These products enabled librarians to more easily manage electronic resources that serve the needs of their users. Serials Solutions became part of ProQuest Workflow Solutions in 2011 and the "Serials Solutions" name was retired in 2014. In 2015, Proquest acquired Ex Libris Group, a library automation company with many similar products to those of ProQuest Workflow Solutions. The Workflow Solutions division was to be merged with Ex Libris into a new business group called Ex Libris, a ProQuest Company.
Agricultural Information Management Standards, abbreviated to AIMS is a space for accessing and discussing agricultural information management standards, tools and methodologies connecting information workers worldwide to build a global community of practice. Information management standards, tools and good practices can be found on AIMS:
RefWorks is a web-based commercial reference management software package. It is produced by Ex Libris, a ProQuest company. RefWorks LLC was founded in 2001 and the software was marketed by Cambridge Scientific Abstracts from 2002 until being acquired by ProQuest in 2008.
UKSG is an international association that exists to "connect the information community" and "encourage the exchange of ideas on scholarly communication". The name UKSG originally stood for United Kingdom Serials Group, but the association is now known simply as UKSG as it has expanded beyond the UK and beyond serials to include e-books and other electronic resources.
Preservation metadata is information that supports and documents acts of preservation on digital materials. A specific type of metadata, preservation metadata works to maintain a digital object’s viability while also ensuring continued access through providing contextual information as well as details on usage and rights. It describes both the context of an item as well as its structure.

Metadata is "data that provides information about other data". In other words, it is "data about data". Many distinct types of metadata exist, including descriptive metadata, structural metadata, administrative metadata, reference metadata, statistical metadata and legal metadata.
A digital library, also called an online library, an internet library, a digital repository, or a digital collection is an online database of digital objects that can include text, still images, audio, video, digital documents, or other digital media formats or a library accessible through the internet. Objects can consist of digitized content like print or photographs, as well as originally produced digital content like word processor files or social media posts. In addition to storing content, digital libraries provide means for organizing, searching, and retrieving the content contained in the collection.
The Handle System is the Corporation for National Research Initiatives's proprietary registry assigning persistent identifiers, or handles, to information resources, and for resolving "those handles into the information necessary to locate, access, and otherwise make use of the resources".
The Grey Literature International Steering Committee (GLISC) was established in 2006 after the 7th International Conference on Grey Literature (GL7) held in Nancy (France) on 5–6 December 2005.

Trove is an Australian online library database aggregator and service which includes full text documents, digital images, bibliographic and holdings data of items which are not available digitally, and a free faceted-search engine as a discovery tool. The database includes archives, images, newspapers, official documents, archived websites, manuscripts and other types of data. Hosted by the National Library of Australia in partnership with content providers, including members of the National and State Libraries Australia, it is one of the most well-respected and accessed GLAM services in Australia, with over 70,000 daily users.
Umlaut is an open source front-end for a link resolver for libraries, which deals with advertising services for specific known citations. It runs as Ruby on Rails application via an engine gem. Umlaut accepts requests in OpenURL format, but has no knowledge base of its own, and is intended to be used as a front-end for an existing knowledge base. Currently only SFX is supported, but other plugins can be written.