In computer science, a priority queue is an abstract data type similar to a regular queue or stack abstract data type. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order in which they were enqueued. In other implementations, the order of elements with the same priority is undefined.
In computer science, a red–black tree is a self-balancing binary search tree data structure noted for fast storage and retrieval of ordered information. The nodes in a red-black tree hold an extra "color" bit, often drawn as red and black, which help ensure that the tree is always approximately balanced.

Meiko Scientific Ltd. was a British supercomputer company based in Bristol, founded by members of the design team working on the Inmos transputer microprocessor.

In computer science, distributed memory refers to a multiprocessor computer system in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data are required, the computational task must communicate with one or more remote processors. In contrast, a shared memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.
In computer science, a binomial heap is a data structure that acts as a priority queue. It is an example of a mergeable heap, as it supports merging two heaps in logarithmic time. It is implemented as a heap similar to a binary heap but using a special tree structure that is different from the complete binary trees used by binary heaps. Binomial heaps were invented in 1978 by Jean Vuillemin.

Quadrics was a supercomputer company formed in 1996 as a joint venture between Alenia Spazio and the technical team from Meiko Scientific. They produced hardware and software for clustering commodity computer systems into massively parallel systems. Their highpoint was in June 2003 when six out of the ten fastest supercomputers in the world were based on Quadrics' interconnect. They officially closed on June 29, 2009.
In computer science, a skip list is a probabilistic data structure that allows average complexity for search as well as average complexity for insertion within an ordered sequence of elements. Thus it can get the best features of a sorted array while maintaining a linked list-like structure that allows insertion, which is not possible with a static array. Fast search is made possible by maintaining a linked hierarchy of subsequences, with each successive subsequence skipping over fewer elements than the previous one. Searching starts in the sparsest subsequence until two consecutive elements have been found, one smaller and one larger than or equal to the element searched for. Via the linked hierarchy, these two elements link to elements of the next sparsest subsequence, where searching is continued until finally searching in the full sequence. The elements that are skipped over may be chosen probabilistically or deterministically, with the former being more common.
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel and distributed algorithm on a cluster.
Optical computing or photonic computing uses light waves produced by lasers or incoherent sources for data processing, data storage or data communication for computing. For decades, photons have shown promise to enable a higher bandwidth than the electrons used in conventional computers.

A network on a chip or network-on-chip is a network-based communications subsystem on an integrated circuit ("microchip"), most typically between modules in a system on a chip (SoC). The modules on the IC are typically semiconductor IP cores schematizing various functions of the computer system, and are designed to be modular in the sense of network science. The network on chip is a router-based packet switching network between SoC modules.
In computer networking, a network may be bisected into two equal-sized partitions. The bisection bandwidth of a network topology is the minimum bandwidth available between any two such partitions. Given a graph with vertices , edges , and edge weights , the bisection bandwidth of is
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:
In distributed computing, leader election is the process of designating a single process as the organizer of some task distributed among several computers (nodes). Before the task has begun, all network nodes are either unaware which node will serve as the "leader" of the task, or unable to communicate with the current coordinator. After a leader election algorithm has been run, however, each node throughout the network recognizes a particular, unique node as the task leader.
Multistage interconnection networks (MINs) are a class of high-speed computer networks usually composed of processing elements (PEs) on one end of the network and memory elements (MEs) on the other end, connected by switching elements (SEs). The switching elements themselves are usually connected to each other in stages, hence the name.

Fabric computing or unified computing involves constructing a computing fabric consisting of interconnected nodes that look like a weave or a fabric when seen collectively from a distance.
Collective operations are building blocks for interaction patterns, that are often used in SPMD algorithms in the parallel programming context. Hence, there is an interest in efficient realizations of these operations.
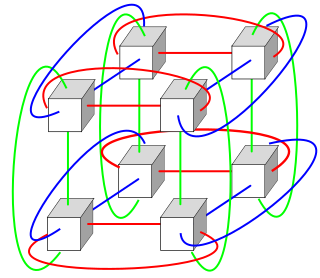
A torus interconnect is a switch-less network topology for connecting processing nodes in a parallel computer system.

A butterfly network is a technique to link multiple computers into a high-speed network. This form of multistage interconnection network topology can be used to connect different nodes in a multiprocessor system. The interconnect network for a shared memory multiprocessor system must have low latency and high bandwidth unlike other network systems, like local area networks (LANs) or internet for three reasons:
Broadcast is a collective communication primitive in parallel programming to distribute programming instructions or data to nodes in a cluster. It is the reverse operation of reduction. The broadcast operation is widely used in parallel algorithms, such as matrix-vector multiplication, Gaussian elimination and shortest paths.

In graph theory, the shuffle-exchange network is an undirected cubic multigraph, whose vertices represent binary sequences of a given length and whose edges represent two operations on these sequence, circular shifts and flipping the lowest-order bit.


