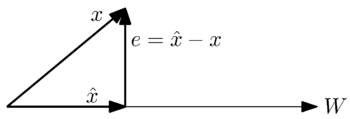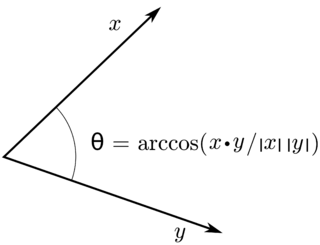
In mathematics, an inner product space is a real vector space or a complex vector space with an operation called an inner product. The inner product of two vectors in the space is a scalar, often denoted with angle brackets such as in . Inner products allow formal definitions of intuitive geometric notions, such as lengths, angles, and orthogonality of vectors. Inner product spaces generalize Euclidean vector spaces, in which the inner product is the dot product or scalar product of Cartesian coordinates. Inner product spaces of infinite dimension are widely used in functional analysis. Inner product spaces over the field of complex numbers are sometimes referred to as unitary spaces. The first usage of the concept of a vector space with an inner product is due to Giuseppe Peano, in 1898.
The Riesz representation theorem, sometimes called the Riesz–Fréchet representation theorem after Frigyes Riesz and Maurice René Fréchet, establishes an important connection between a Hilbert space and its continuous dual space. If the underlying field is the real numbers, the two are isometrically isomorphic; if the underlying field is the complex numbers, the two are isometrically anti-isomorphic. The (anti-) isomorphism is a particular natural isomorphism.
The weighted arithmetic mean is similar to an ordinary arithmetic mean, except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
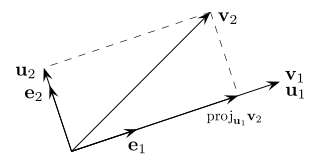
In mathematics, particularly linear algebra and numerical analysis, the Gram–Schmidt process is a method for orthonormalizing a set of vectors in an inner product space, most commonly the Euclidean space Rn equipped with the standard inner product. The Gram–Schmidt process takes a finite, linearly independent set of vectors S = {v1, ..., vk} for k ≤ n and generates an orthogonal set S′ = {u1, ..., uk} that spans the same k-dimensional subspace of Rn as S.
In linear algebra, the outer product of two coordinate vectors is a matrix. If the two vectors have dimensions n and m, then their outer product is an n × m matrix. More generally, given two tensors, their outer product is a tensor. The outer product of tensors is also referred to as their tensor product, and can be used to define the tensor algebra.
In probability theory and statistics, covariance is a measure of the joint variability of two random variables. If the greater values of one variable mainly correspond with the greater values of the other variable, and the same holds for the lesser values, the covariance is positive. In the opposite case, when the greater values of one variable mainly correspond to the lesser values of the other,, the covariance is negative. The sign of the covariance therefore shows the tendency in the linear relationship between the variables. The magnitude of the covariance is not easy to interpret because it is not normalized and hence depends on the magnitudes of the variables. The normalized version of the covariance, the correlation coefficient, however, shows by its magnitude the strength of the linear relation.
In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal, nor do they need to be independent and identically distributed. The requirement that the estimator be unbiased cannot be dropped, since biased estimators exist with lower variance. See, for example, the James–Stein estimator, ridge regression, or simply any degenerate estimator.
In mathematics, particularly in linear algebra, a skew-symmetricmatrix is a square matrix whose transpose equals its negative. That is, it satisfies the condition

In probability theory and statistics, a covariance matrix is a square matrix giving the covariance between each pair of elements of a given random vector. Any covariance matrix is symmetric and positive semi-definite and its main diagonal contains variances.
In linear algebra, a QR decomposition, also known as a QR factorization or QU factorization, is a decomposition of a matrix A into a product A = QR of an orthogonal matrix Q and an upper triangular matrix R. QR decomposition is often used to solve the linear least squares problem and is the basis for a particular eigenvalue algorithm, the QR algorithm.
In control systems, sliding mode control (SMC) is a nonlinear control method that alters the dynamics of a nonlinear system by applying a discontinuous control signal that forces the system to "slide" along a cross-section of the system's normal behavior. The state-feedback control law is not a continuous function of time. Instead, it can switch from one continuous structure to another based on the current position in the state space. Hence, sliding mode control is a variable structure control method. The multiple control structures are designed so that trajectories always move toward an adjacent region with a different control structure, and so the ultimate trajectory will not exist entirely within one control structure. Instead, it will slide along the boundaries of the control structures. The motion of the system as it slides along these boundaries is called a sliding mode and the geometrical locus consisting of the boundaries is called the sliding (hyper)surface. In the context of modern control theory, any variable structure system, like a system under SMC, may be viewed as a special case of a hybrid dynamical system as the system both flows through a continuous state space but also moves through different discrete control modes.

In linear algebra and functional analysis, a projection is a linear transformation from a vector space to itself such that . That is, whenever is applied twice to any vector, it gives the same result as if it were applied once. It leaves its image unchanged. This definition of "projection" formalizes and generalizes the idea of graphical projection. One can also consider the effect of a projection on a geometrical object by examining the effect of the projection on points in the object.

In quantum mechanics and computing, the Bloch sphere is a geometrical representation of the pure state space of a two-level quantum mechanical system (qubit), named after the physicist Felix Bloch.
In statistics, ordinary least squares (OLS) is a type of linear least squares method for estimating the unknown parameters in a linear regression model. OLS chooses the parameters of a linear function of a set of explanatory variables by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the given dataset and those predicted by the linear function of the independent variable.
In statistics and signal processing, a minimum mean square error (MMSE) estimator is an estimation method which minimizes the mean square error (MSE), which is a common measure of estimator quality, of the fitted values of a dependent variable. In the Bayesian setting, the term MMSE more specifically refers to estimation with quadratic loss function. In such case, the MMSE estimator is given by the posterior mean of the parameter to be estimated. Since the posterior mean is cumbersome to calculate, the form of the MMSE estimator is usually constrained to be within a certain class of functions. Linear MMSE estimators are a popular choice since they are easy to use, easy to calculate, and very versatile. It has given rise to many popular estimators such as the Wiener–Kolmogorov filter and Kalman filter.
In mathematics and physics, in particular quantum information, the term generalized Pauli matrices refers to families of matrices which generalize the properties of the Pauli matrices. Here, a few classes of such matrices are summarized.
In statistics, Bayesian multivariate linear regression is a Bayesian approach to multivariate linear regression, i.e. linear regression where the predicted outcome is a vector of correlated random variables rather than a single scalar random variable. A more general treatment of this approach can be found in the article MMSE estimator.
In statistics, the projection matrix, sometimes also called the influence matrix or hat matrix, maps the vector of response values to the vector of fitted values. It describes the influence each response value has on each fitted value. The diagonal elements of the projection matrix are the leverages, which describe the influence each response value has on the fitted value for that same observation.
The purpose of this page is to provide supplementary materials for the ordinary least squares article, reducing the load of the main article with mathematics and improving its accessibility, while at the same time retaining the completeness of exposition.
In mathematics, a dual system, dual pair, or duality over a field is a triple consisting of two vector spaces and over and a non-degenerate bilinear map . Duality theory, the study of dual systems, is part of functional analysis.