In digital signal processing (DSP), parallel processing is a technique duplicating function units to operate different tasks (signals) simultaneously.[1] Accordingly, we can perform the same processing for different signals on the corresponding duplicated function units. Further, due to the features of parallel processing, the parallel DSP design often contains multiple outputs, resulting in higher throughput than not parallel.
Consider a function unit () and three tasks (, , and ). The required time for the function unit to process those tasks is , , and , respectively. Then, if we operate these three tasks in a sequential order, the required time to complete them is .
However, if we duplicate the function unit to another two copies (), the aggregate time is reduced to , which is smaller than in a sequential order.
Versus pipelining
Mechanism:
Parallel: duplicated function units working in parallel
Each task is processed entirely by a different function unit.
Pipelining: different function units working in parallel
Each task is split into a sequence of sub-tasks, which are handled by specialized and different function units.
Parallel processing techniques require multiple outputs, which are computed in parallel in a clock period. Therefore, the effective sample speed is increased by the level of parallelism.
Consider a condition that we are able to apply both parallel processing and pipelining techniques, it is better to choose parallel processing techniques with the following reasons
Pipelining usually causes I/O bottlenecks
Parallel processing is also utilized for reduction of power consumption while using slow clocks
The hybrid method of pipelining and parallel processing further increase the speed of the architecture
Assume the calculation time for multiplication units is Tm and Ta for add units. The sample period is given by
By parallelizing it, the resultant architecture is shown as follows. The sample rate now becomes
where N represents the number of copies.
Please note that, in a parallel system, while holds in a pipelined system.
Parallel 1st-order IIR filters
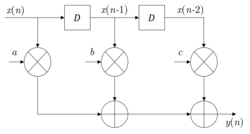
Consider the transfer function of a 1st-order IIR filter formulated as
where |a| ≤ 1 for stability, and such filter has only one pole located at z=a;
The corresponding recursive representation is
Consider the design of a 4-parallel architecture (N=4). In such parallel system, each delay element means a block delay and the clock period is four times the sample period.
Therefore, by iterating the recursion with n=4k, we have
The corresponding architecture is shown as follows.
The resultant parallel design has the following properties.
The pole of the original filter is at z=a while the pole for the parallel system is at z=a4 which is closer to the origin.
The pole movement improves the robustness of the system to the round-off noise.
Hardware complexity of this architecture: N×N multiply-add operations.
The square increase in hardware complexity can be reduced by exploiting the concurrency and the incremental computation to avoid repeated computing.
Parallel processing for low power
Another advantage for the parallel processing techniques is that it can reduce the power consumption of a system by reducing the supply voltage.
Consider the following power consumption in a normal CMOS circuit.
where the Ctotal represents the total capacitance of the CMOS circuit.
For a parallel version, the charging capacitance remains the same but the total capacitance increases by N times.
In order to maintain the same sample rate, the clock period of the N-parallel circuit increases to N times the propagation delay of the original circuit.
It makes the charging time prolongs N times. The supply voltage can be reduced to βV0.
Therefore, the power consumption of the N-parallel system can be formulated as
where β can be computed by
References
↑ K. K. Parhi, VLSI Digital Signal Processing Systems: Design and Implementation, John Wiley, 1999
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.