An optimizing compiler is a compiler designed to generate code that is optimized in aspects such as minimizing program execution time, memory usage, storage size, and power consumption. Optimization is generally implemented as a sequence of optimizing transformations—algorithms that transform code to produce semantically equivalent code optimized for some aspect.

In computer science, a control-flow graph (CFG) is a representation, using graph notation, of all paths that might be traversed through a program during its execution. The control-flow graph was discovered by Frances E. Allen, who noted that Reese T. Prosser used boolean connectivity matrices for flow analysis before.
In compiler design, static single assignment form is a type of intermediate representation (IR) where each variable is assigned exactly once. SSA is used in most high-quality optimizing compilers for imperative languages, including LLVM, the GNU Compiler Collection, and many commercial compilers.
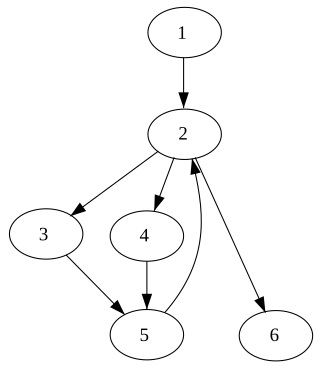
In computer science, a node d of a control-flow graph dominates a node n if every path from the entry node to n must go through d. Notationally, this is written as d dom n. By definition, every node dominates itself.
In compiler theory, dead-code elimination is a compiler optimization to remove dead code. Removing such code has several benefits: it shrinks program size, an important consideration in some contexts, it reduces resource usage such as the number of bytes to be transferred and it allows the running program to avoid executing irrelevant operations, which reduces its running time. It can also enable further optimizations by simplifying program structure. Dead code includes code that can never be executed, and code that only affects dead variables, that is, irrelevant to the program.

LLVM is a set of compiler and toolchain technologies that can be used to develop a frontend for any programming language and a backend for any instruction set architecture. LLVM is designed around a language-independent intermediate representation (IR) that serves as a portable, high-level assembly language that can be optimized with a variety of transformations over multiple passes. The name LLVM originally stood for Low Level Virtual Machine, though the project has expanded and the name is no longer officially an initialism.
Data-flow analysis is a technique for gathering information about the possible set of values calculated at various points in a computer program. A program's control-flow graph (CFG) is used to determine those parts of a program to which a particular value assigned to a variable might propagate. The information gathered is often used by compilers when optimizing a program. A canonical example of a data-flow analysis is reaching definitions.
In computer science, instruction scheduling is a compiler optimization used to improve instruction-level parallelism, which improves performance on machines with instruction pipelines. Put more simply, it tries to do the following without changing the meaning of the code:
An intermediate representation (IR) is the data structure or code used internally by a compiler or virtual machine to represent source code. An IR is designed to be conducive to further processing, such as optimization and translation. A "good" IR must be accurate – capable of representing the source code without loss of information – and independent of any particular source or target language. An IR may take one of several forms: an in-memory data structure, or a special tuple- or stack-based code readable by the program. In the latter case it is also called an intermediate language.
In compiler theory, loop optimization is the process of increasing execution speed and reducing the overheads associated with loops. It plays an important role in improving cache performance and making effective use of parallel processing capabilities. Most execution time of a scientific program is spent on loops; as such, many compiler optimization techniques have been developed to make them faster.
In compiler theory, dependence analysis produces execution-order constraints between statements/instructions. Broadly speaking, a statement S2 depends on S1 if S1 must be executed before S2. Broadly, there are two classes of dependencies--control dependencies and data dependencies.
In computer science, loop dependence analysis is a process which can be used to find dependencies within iterations of a loop with the goal of determining different relationships between statements. These dependent relationships are tied to the order in which different statements access memory locations. Using the analysis of these relationships, execution of the loop can be organized to allow multiple processors to work on different portions of the loop in parallel. This is known as parallel processing. In general, loops can consume a lot of processing time when executed as serial code. Through parallel processing, it is possible to reduce the total execution time of a program through sharing the processing load among multiple processors.
Automatic parallelization, also auto parallelization, or autoparallelization refers to converting sequential code into multi-threaded and/or vectorized code in order to use multiple processors simultaneously in a shared-memory multiprocessor (SMP) machine. Fully automatic parallelization of sequential programs is a challenge because it requires complex program analysis and the best approach may depend upon parameter values that are not known at compilation time.
Automatic vectorization, in parallel computing, is a special case of automatic parallelization, where a computer program is converted from a scalar implementation, which processes a single pair of operands at a time, to a vector implementation, which processes one operation on multiple pairs of operands at once. For example, modern conventional computers, including specialized supercomputers, typically have vector operations that simultaneously perform operations such as the following four additions :
A data dependency in computer science is a situation in which a program statement (instruction) refers to the data of a preceding statement. In compiler theory, the technique used to discover data dependencies among statements is called dependence analysis.
In computer science, pointer analysis, or points-to analysis, is a static code analysis technique that establishes which pointers, or heap references, can point to which variables, or storage locations. It is often a component of more complex analyses such as escape analysis. A closely related technique is shape analysis.
In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm, it is possible to express static or dynamic data streams with ease, and also communicate that an inferred dependency within the associated execution model exists, which facilitates the automatic propagation of the changed data flow.
Use of the polyhedral model within a compiler requires software to represent the objects of this framework and perform operations upon them.
In computer science, code motion, also known as code hoisting, code sinking, loop-invariant code motion, or code factoring, is a blanket term for any process that moves code within a program for performance or size benefits, and is a common optimization performed in most optimizing compilers. It can be difficult to differentiate between different types of code motion, due to the inconsistent meaning of the terms surrounding it.
In computer science, a code property graph (CPG) is a computer program representation that captures syntactic structure, control flow, and data dependencies in a property graph. The concept was originally introduced to identify security vulnerabilities in C and C++ system code, but has since been employed to analyze web applications, cloud deployments, and smart contracts. Beyond vulnerability discovery, code property graphs find applications in code clone detection, attack-surface detection, exploit generation, measuring code testability, and backporting of security patches.
