
In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.
A relational database (RDB) is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A database management system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.
Data integrity is the maintenance of, and the assurance of, data accuracy and consistency over its entire life-cycle. It is a critical aspect to the design, implementation, and usage of any system that stores, processes, or retrieves data. The term is broad in scope and may have widely different meanings depending on the specific context even under the same general umbrella of computing. It is at times used as a proxy term for data quality, while data validation is a prerequisite for data integrity.
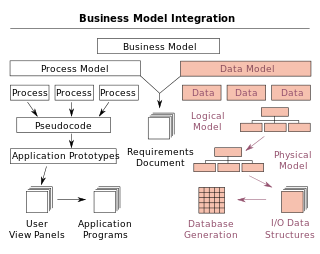
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if no attribute domain has relations as elements. Or more informally, that no table column can have tables as values. Database normalization is the process of representing a database in terms of relations in standard normal forms, where first normal is a minimal requirement. SQL-92 does not support creating or using table-valued columns, which means that using only the "traditional relational database features" most relational databases will be in first normal form by necessity. Database systems which do not require first normal form are often called NoSQL systems. Newer SQL standards like SQL:1999 have started to allow so called non-atomic types, which include composite types. Even newer versions like SQL:2016 allow JSON.

In computing, extract, transform, load (ETL) is a three-phase process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.
ABAP is a high-level programming language created by the German software company SAP SE. It is currently positioned, alongside Java, as the language for programming the SAP NetWeaver Application Server, which is part of the SAP NetWeaver platform for building business applications.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.

An entity–relationship model describes interrelated things of interest in a specific domain of knowledge. A basic ER model is composed of entity types and specifies relationships that can exist between entities.
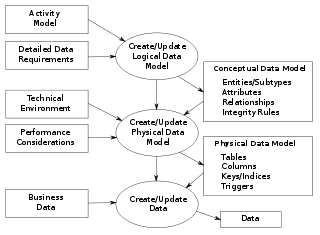
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDE) concept.
Database design is the organization of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the database model. A database management system manages the data accordingly.
In computing, data validation or input validation is the process of ensuring data has undergone data cleansing to confirm they have data quality, that is, that they are both correct and useful. It uses routines, often called "validation rules", "validation constraints", or "check routines", that check for correctness, meaningfulness, and security of data that are input to the system. The rules may be implemented through the automated facilities of a data dictionary, or by the inclusion of explicit application program validation logic of the computer and its application.
Data cleansing or data cleaning is the process of detecting and correcting corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data wrangling tools, or as batch processing through scripting or a data quality firewall.
In data management and database analysis, a data domain is the collection of values that a data element may contain. The rule for determining the domain boundary may be as simple as a data type with an enumerated list of values.
An entity–attribute–value model (EAV) is a data model optimized for the space-efficient storage of sparse—or ad-hoc—property or data values, intended for situations where runtime usage patterns are arbitrary, subject to user variation, or otherwise unforeseeable using a fixed design. The use-case targets applications which offer a large or rich system of defined property types, which are in turn appropriate to a wide set of entities, but where typically only a small, specific selection of these are instantiated for a given entity. Therefore, this type of data model relates to the mathematical notion of a sparse matrix. EAV is also known as object–attribute–value model, vertical database model, and open schema.
In relational database management systems, a unique key is a candidate key. All the candidate keys of a relation can uniquely identify the records of the relation, but only one of them is used as the primary key of the relation. The remaining candidate keys are called unique keys because they can uniquely identify a record in a relation. Unique keys can consist of multiple columns. Unique keys are also called alternate keys. Unique keys are an alternative to the primary key of the relation. In SQL, the unique keys have a UNIQUE constraint assigned to them in order to prevent duplicates. Alternate keys may be used like the primary key when doing a single-table select or when filtering in a where clause, but are not typically used to join multiple tables.

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
A document-oriented database, or document store, is a computer program and data storage system designed for storing, retrieving and managing document-oriented information, also known as semi-structured data.
In relational databases, the log trigger or history trigger is a mechanism for automatic recording of information about changes inserting or/and updating or/and deleting rows in a database table.